Idea
这个 paper 的初始 idea 其实很直接:我在训练大模型、跑各种 eval 的时候,除了在不同测试集上得到一个个分数之外,有没有办法对 eval 这件事本身做一些更量化的分析?
比如说,我能不能分析一下某个 eval 分数的置信区间?或者我能不能分析一下,eval 样本个数和 eval 结果可信度之间到底是什么关系?通俗地讲,我就是很想在 eval 指标上给它加一个 error bar。
而另一个 idea 则更 general: 大模型一直可以从能量模型的视角去理解。score matching、统计物理里的能量模型,都会通过指数和 log 变换,把“能量”和“概率分布”联系起来。这个 idea 其实我很早之前就有,一直在想:如果沿着这个视角继续看下去,它能不能让我们对大模型有更多理解?或者它能不能帮我们做一些具体的事情?
Method
最开始我顺着第二个 insight 的视角往下做。
一开始的问题是:能不能把大模型理解成一个能量模型?但很快我发现,这其实不是一个好问题。因为它只是提供了一种看问题的视角,或者说是一种解释性的方法。它既没有给出可以量化的指标,也没有给出可以计算、可以验证的假设。只有这样一个问题本身,其实没有太大意义。
于是我紧接着追问:能不能借助物理里的一些概念,构造出可以计算的量,然后再分析它的性质?
这个时候,一个非常符合直觉的 idea 出现了:很多时候,描述一个绝对量是比较困难的。比如你要用物理的视角描述一个系统,如果你试图记录系统里所有点的绝对位置,这当然可以做,但它往往不是最自然、也不是最稳定的描述方式。相反,我可以只描述点与点之间的相对关系。这样一来,整个系统就天然具有某种平移不变性:这些点整体可以移动,但点之间的相对关系不变,因此系统的一些性质依然可以被描述。
而且,正是因为我们不再纠结绝对位置,而是保留相对结构,描述反而可能变得更好、更稳定。
于是我尝试借助统计物理里 order parameter 的概念,构造几个用于描述模型整体状态的比较量,并分析它们的性质。这个量最初是从能量模型出发的,所以它最自然的形式是:每一个生成的 token sequence 都可以看作系统中的一个样本点,而每个样本点都有自己的能量。直觉上,能量低的点应该有更高概率出现,也就是更容易被模型生成。
具体来说,设 $M$ 是一个语言模型,$x$ 是 prompt,$y=(y_1,\dots,y_T)$ 是模型在 prompt 下的一段 response,其中 $T=|y|$ 表示 response 的 token 数量。模型给这段 response 分配条件概率:
$$ Q_M(y\mid x). $$如果从能量模型的角度看,可以把 response 的能量定义为负 log-probability:
$$ E_M(x,y)=-\log Q_M(y\mid x). $$概率越大,$-\log$ 之后的能量越低。这和能量模型里的直觉是一致的:低能量状态更容易出现。
不过在语言模型里,response 长度会强烈影响 log-likelihood。长文本天然会累积更多 token 的 log-probability,因此直接比较 $\log Q_M(y\mid x)$ 往往不公平。于是论文里采用的是 token-normalized log-likelihood,也就是平均到每个 token 上的 log-probability:
$$ S_M(x,y)=\frac{1}{|y|}\log Q_M(y\mid x). $$这里 $S_M(x,y)$ 是模型 $M$ 对 response $y$ 的标量打分。它越大,表示模型越“愿意”给出这段 response;如果换成能量语言,也可以定义归一化能量:
$$ \begin{aligned} \bar{E}_M(x,y) &= -S_M(x,y) \\ &= -\frac{1}{|y|}\log Q_M(y\mid x). \end{aligned} $$这样我们就可以把“模型更偏好哪个回答”写成一个 pairwise comparison。给定一组三元组:
$$ (x,y^+,y^-), $$其中 $y^+$ 是参考分布里更偏好的回答,$y^-$ 是被拒绝的回答。如果模型给出的标量分数满足:
$$ S_M(x,y^+) > S_M(x,y^-), $$那么我们就说模型在这个 pair 上和参考偏好是一致的。用能量语言说,就是:
$$ \bar{E}_M(x,y^+) < \bar{E}_M(x,y^-). $$也就是说,参考更偏好的回答,在模型的能量景观里也处在更低能量的位置。
之后我又进一步分析这个量的性质,发现它确实非常好。更进一步,我可以跳出具体的能量函数视角,不再限定 $S_M$ 必须来自 log-likelihood,而是把它看成任意一个标量函数。它可以是 log-likelihood,可以是 reward model 的分数,也可以是 LLM-as-a-judge 给出的评分。只要这个标量可以比较两个 response,我们就可以定义同样的 observable。
设 $P_{\mathrm{pair}}$ 是一个参考 pair 分布。它会生成这样的三元组:
$$ (x,y^+,y^-)\sim P_{\mathrm{pair}}. $$这里 $P_{\mathrm{pair}}$ 很重要。它不是一个随便的测试集,而是我们想要对齐的参考偏好分布。比如它可以来自人类偏好数据,可以来自专家规则,也可以来自某个 judge model。不同的 $P_{\mathrm{pair}}$ 就定义了不同的“偏好目标”。
对于某个模型 $M$ 和标量打分函数 $S_M$,我们定义 pairwise agreement indicator:
$$ Z_M(x,y^+,y^-)=\mathbf{1}\left[S_M(x,y^+) > S_M(x,y^-)\right]. $$这里 $\mathbf{1}[\cdot]$ 是指示函数:如果括号里的条件成立,它等于 1;否则等于 0。也就是说,如果模型把参考偏好的回答排在前面,$Z_M=1$;如果模型排反了,$Z_M=0$。
然后定义模型层面的 pairwise reference alignment:
$$ A_M(P_{\mathrm{pair}})=\mathbb{E}_{(x,y^+,y^-)\sim P_{\mathrm{pair}}}\left[Z_M(x,y^+,y^-)\right]. $$等价地,它也可以写成一个概率:
$$ A_M(P_{\mathrm{pair}})=\mathbb{P}_{(x,y^+,y^-)\sim P_{\mathrm{pair}}}\left[S_M(x,y^+) > S_M(x,y^-)\right]. $$这个定义非常直接:如果我从参考偏好分布里随机抽一对回答,那么 $A_M(P_{\mathrm{pair}})$ 就是模型排序和参考排序一致的概率。
如果 $A_M=0.8$,它的含义就是:在这个参考分布下,随机抽取一个 pair,模型有 80% 的概率把参考偏好的回答排在参考拒绝的回答前面。这个解释非常干净。
为了更像统计物理里的 order parameter,我们还可以定义一个 centered statistic:
$$ m_M^{\mathrm{sign}}(P_{\mathrm{pair}})=2A_M(P_{\mathrm{pair}})-1. $$这样一来,$m=1$ 表示完全一致,$m=0$ 表示随机水平,$m<0$ 表示模型系统性地偏向参考拒绝的回答。这个量就很像一个 order parameter:它把大量微观 pairwise comparison 聚合成一个宏观量,用来描述模型相对于某个参考分布的整体状态。
不过,这个 sign observable 只回答了一个离散问题:模型有没有把这个 pair 排对。它不回答模型到底有多强地偏向 $y^+$,也不区分“刚好排对”和“非常确信地排对”。所以论文里还定义了第二个 observable,也就是 margin observable。
对同一个参考 pair $(x,y^+,y^-)$,定义模型的 signed margin:
$$ d_M(x,y^+,y^-)=S_M(x,y^+)-S_M(x,y^-). $$这里 $d_M$ 是两个 response 在模型标量分数下的差值。如果 $d_M>0$,说明模型更偏向参考偏好的回答 $y^+$;如果 $d_M<0$,说明模型反而更偏向参考拒绝的回答 $y^-$。和前面的 $Z_M$ 相比,$d_M$ 不只保留方向,还保留了强度。
因此可以定义分布层面的 mean margin:
$$ \mu_M(P_{\mathrm{pair}})=\mathbb{E}_{(x,y^+,y^-)\sim P_{\mathrm{pair}}}\left[d_M(x,y^+,y^-)\right]. $$这个量描述的是:在参考 pair 分布上,模型平均给参考偏好回答比参考拒绝回答高出多少分。它和 $A_M(P_{\mathrm{pair}})$ 是互补的。$A_M$ 关心“排对的比例”,$\mu_M$ 关心“平均分数差距”。
有限样本上的估计量也很自然。定义第 $k$ 个 pair 的 observed margin:
$$ \begin{aligned} \Delta_k^{(M)} &= d_M(x_k,y_k^+,y_k^-) \\ &= S_M(x_k,y_k^+)-S_M(x_k,y_k^-). \end{aligned} $$那么 mean margin 的经验估计是:
$$ \hat{\mu}_M(\mathcal{C})=\frac{1}{K}\sum_{k=1}^{K}\Delta_k^{(M)}. $$如果 $S_M$ 取的是 log-probability,也就是
$$ S_M(x,y)=\log Q_M(y\mid x), $$那么 margin 就有一个非常直观的 log-likelihood ratio 解释:
$$ \begin{aligned} d_M(x,y^+,y^-) &= \log Q_M(y^+\mid x)-\log Q_M(y^-\mid x) \\ &= \log\frac{Q_M(y^+\mid x)}{Q_M(y^-\mid x)}. \end{aligned} $$也就是说,margin 衡量的是模型分布中 $y^+$ 相对 $y^-$ 的概率优势。如果 $d_M=\log 2$,就表示模型给 $y^+$ 的概率是 $y^-$ 的 2 倍;如果 $d_M=-\log 2$,则表示模型给 $y^+$ 的概率只有 $y^-$ 的一半。实验中使用的是 token-normalized log-likelihood,所以它对应的是平均到每个 token 上的相对 likelihood gap。
当然,margin observable 也更敏感。因为它依赖 score 的尺度,可能受到长度、罕见 token、极低概率 sequence 或打分函数分布尾部的影响。所以 sign observable 更稳、更容易给出干净的统计 bound;margin observable 信息更多,但解释时必须说明 score 的定义、归一化方式和估计方法。
接下来是估计问题。现实中我们拿不到完整的 $P_{\mathrm{pair}}$,只能拿到有限样本:
$$ \mathcal{C}=\{(x_k,y_k^+,y_k^-)\}_{k=1}^{K}. $$这里 $K$ 是 pair 的数量。自然的经验估计量是:
$$ \hat{A}_M(\mathcal{C})=\frac{1}{K}\sum_{k=1}^{K}Z_M(x_k,y_k^+,y_k^-). $$这就是在有限测试集上算出来的 accuracy:模型有多少比例的 pair 排对了。
但关键是,我们不是把这个有限测试集上的数字当成最终对象。真正的对象是分布上的 $A_M(P_{\mathrm{pair}})$;有限测试集只是用来估计它。这个区别非常重要。
如果假设这些 pair 是从 $P_{\mathrm{pair}}$ 中独立采样得到的,由于每个 $Z_M$ 都是 0 或 1 的 Bernoulli 随机变量,Hoeffding inequality 直接给出:
$$ \mathbb{P}\left(\left|\hat{A}_M(\mathcal{C})-A_M(P_{\mathrm{pair}})\right|\ge \epsilon\right)\le 2\exp(-2K\epsilon^2). $$这里 $\epsilon$ 是我们允许的估计误差。这个 bound 的意思是:样本数 $K$ 越大,经验估计 $\hat{A}_M$ 偏离真实分布量 $A_M$ 的概率就指数下降。
如果我们希望以至少 $1-\delta$ 的概率,把误差控制在 $\epsilon$ 以内,只需要:
$$ K\ge \frac{1}{2\epsilon^2}\log\frac{2}{\delta}. $$比如 $\epsilon=0.05$、$\delta=0.05$,也就是希望在 95% 置信水平下把误差控制在 0.05 以内,那么:
$$ K\ge \frac{1}{2(0.05)^2}\log\frac{2}{0.05}\approx 738. $$对于 margin observable,也可以得到类似的结论,只是需要额外假设 margin 是有界的。假设对所有 pair 都有
$$ d_M(x,y^+,y^-)\in[a,b], $$也就是说 margin 不会跑出区间 $[a,b]$。那么 Hoeffding inequality 给出:
$$ \mathbb{P}\left(\left|\hat{\mu}_M(\mathcal{C})-\mu_M(P_{\mathrm{pair}})\right|\ge \epsilon\right)\le 2\exp\left(-\frac{2K\epsilon^2}{(b-a)^2}\right). $$因此,如果要以至少 $1-\delta$ 的概率把 margin 的估计误差控制在 $\epsilon$ 以内,一个充分条件是:
$$ K\ge \frac{(b-a)^2}{2\epsilon^2}\log\frac{2}{\delta}. $$这也解释了为什么 margin observable 虽然信息更多,但统计上更依赖 score 的尺度。如果 score 的范围很大,或者 margin 分布尾部很重,那么估计 mean margin 就会比估计 sign agreement 更困难。
这个结果对我来说非常漂亮。因为它把“eval 需要多少样本才靠谱”这件事,直接变成了一个可以计算的问题。
那这个时候我们再看 $A_M$ 的定义,会发现它有一点出乎意料地好。它不但有非常明确的理论 bound,而且它真的像 order parameter 一样,可以描述模型的一些整体性质。比如,我能不能用它来判断模型的偏好对齐?看起来它是真的可以做到的。
首先,这个定义本身有非常直接的含义:它描述的是模型用某个标量对一组 response 进行排序时,是否符合这组 response 所来自的参考偏好分布。比如 $A_M=80\%$,它描述的就是模型对任意一个参考 pair 排序时,有 80% 的概率和参考偏好一致。
其次,这个量并不依赖于某一个固定的测试集。它是根据分布定义的。测试集只是一个采样工具,用来估计这个分布量。样本数越多,我们对这个估计越有信心。Hoeffding bound 正好把样本个数、估计误差和置信度之间的关系给出来了。
这让我觉得这个量非常有意义。比如我们如何定义一个人的偏好?我们是不是可以说,假设存在一个无限样本集合,一个具有某种偏好的人,应该会对这些样本形成一套排序关系。如果我的模型在所有这些排序关系上都和他一致,那是不是可以说模型和这个人的偏好达到了某种对齐?
当然,这里有一点必须强调:我们这里的偏好是由分布定义的。不同的偏好,对应不同的 $P_{\mathrm{pair}}$。一个数学推理偏好分布、一个安全拒答偏好分布、一个代码质量偏好分布,它们并不是同一个东西。所以 alignment 在这里永远不是一个抽象的、无条件的词,而是相对于某个参考 pair 分布和某个 scoring rule 来说的。
这点在后面的实验里也会看到:同一个模型,在不同 subset 上的表现会明显不同。这说明我们不能简单地说“模型 aligned”或者“模型 not aligned”,更精确的说法应该是:在某个 $P_{\mathrm{pair}}$ 和某个 $S_M$ 下,模型达到了怎样的 pairwise reference alignment。
Experiments
说实话,这个时候我已经有点感觉这个 idea 真的妙不可言了。但它里面其实有一个非常关键的实验问题:如果我们把 $S_M$ 定义成任意 general scalar,那这个东西就不好通过实验验证。因为你总得指定一个具体的 score,才能真正算出数值。
所以实验里我们把 $S_M$ 固定成最开始的能量形式,也就是 token-normalized log-likelihood。这样就可以问一个非常具体的问题:用模型自己的 likelihood 诱导出来的排序,是否真的能够体现模型对参考偏好的倾向?
这个形式和 perplexity 的关系很近,但它并不完全等同于 perplexity。对一段 response $y$,如果使用前文定义的 token-normalized log-likelihood:
$$ S_M(x,y)=\frac{1}{|y|}\log Q_M(y\mid x). $$那么对应的 perplexity 通常可以写成:
$$ \mathrm{PPL}_M(x,y)=\exp\left(-\frac{1}{|y|}\log Q_M(y\mid x)\right). $$也就是说:
$$ \mathrm{PPL}_M(x,y)=\exp(-S_M(x,y)). $$因此,$S_M$ 越大,perplexity 越低;$S_M$ 越小,perplexity 越高。换句话说,前文定义的两个 observable 即使不从能量模型角度出发,也依然有很自然的 perplexity 解释。sign agreement $\hat{A}_M$ 比较的是两个 response 的 perplexity 大小关系:模型是否给参考偏好的回答更低的 perplexity。mean signed margin $\hat{\mu}_M$ 则对应 log perplexity 层面的相对差值,也就是模型在平均 token 级别上给 $y^+$ 和 $y^-$ 分配的 log-perplexity gap。所以这里的定义并不依赖“能量”这个解释框架;能量视角只是让它更直观,而 perplexity 视角本身已经足够说明这个量为什么有意义。
然后我们做了三组实验。
第一组实验是整体 pairwise reference alignment。问题是:这个比较量能不能区分模型?具体来说,instruction-tuned 模型是否比 base 模型更符合参考偏好?更大的模型是否比更小的模型更符合参考偏好?
实验使用 Qwen2.5 系列模型,包括 0.5B、1.5B、3B、7B 的 base 和 instruct 版本。数据集使用 RewardBench,共使用 $K=5120$ 个 preference pairs。每个 pair 都包含 prompt $x$、参考偏好的回答 $y^+$ 和参考拒绝的回答 $y^-$。
第二组实验是 subset-level analysis。它对应前面理论里的一个关键点:$A_M(P_{\mathrm{pair}})$ 不是模型本身无条件的属性,而是模型、score function 和 reference pair distribution 三者共同定义的属性。所以我们把 RewardBench 按 subset 或语义类别拆开,观察同一个模型在不同参考分布上的表现是否不同。
第三组实验是统计性质分析。它又分成两部分:一部分是看不同样本数下估计量的收敛情况;另一部分是用 bootstrap resampling 分析 full-sample estimate 的不确定性。这里正好对应前面 Hoeffding bound 的理论分析。
实验结果出乎意料地好。三组实验基本都按照我们预期的方向进行。
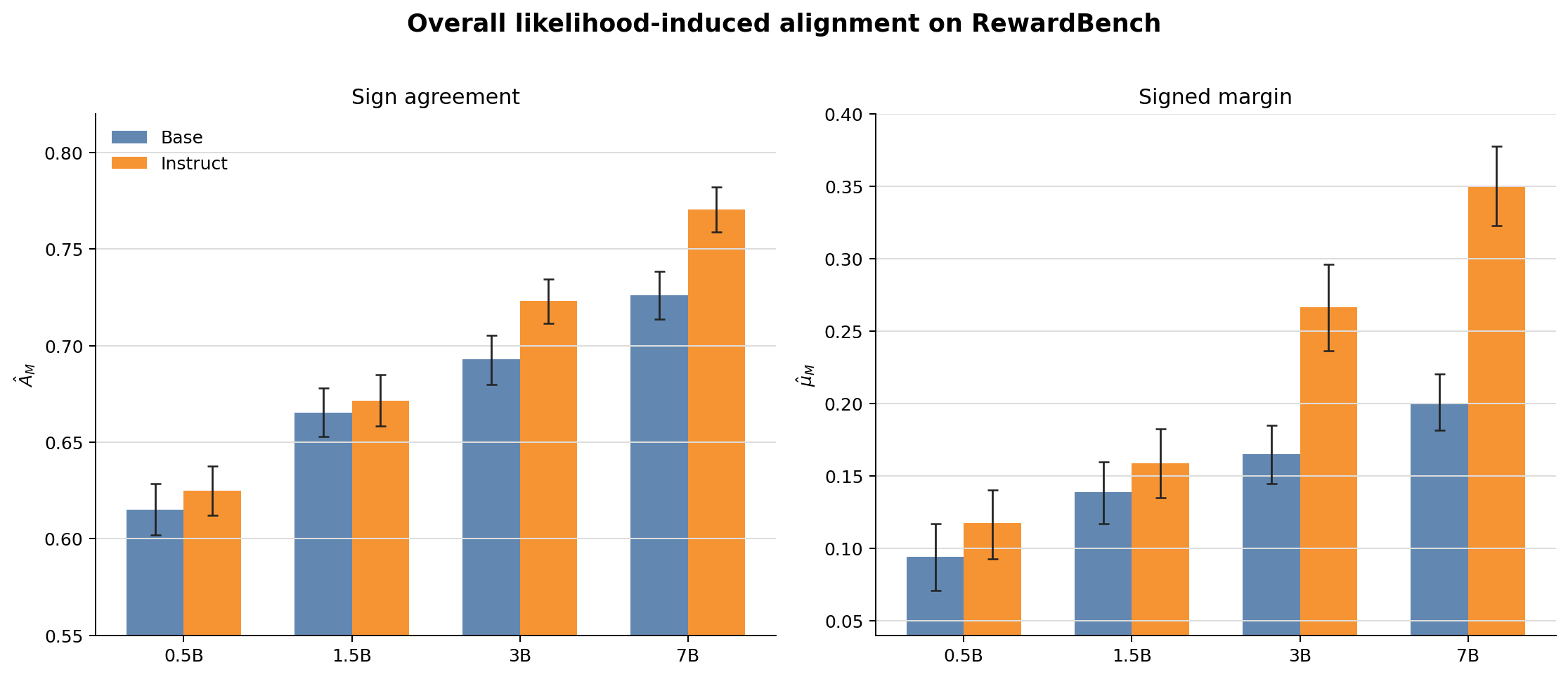
第一组实验里,instruction-tuned 模型在每个 size 上都比对应 base 模型更对齐参考偏好。随着模型尺寸增加,$A_M$ 也整体上升。比如 Qwen2.5-0.5B 的 $\hat{A}_M$ 是 0.6148,而 Qwen2.5-7B 达到 0.7262;Qwen2.5-0.5B-Instruct 是 0.6250,而 Qwen2.5-7B-Instruct 达到 0.7705。
这说明这个 likelihood-induced pairwise alignment 确实能捕捉到模型 size 和 instruction tuning 带来的差异。用更口语的话说,就是模型越强、越经过 instruction tuning,它在 RewardBench 这种人类偏好分布上的排序就越像参考偏好。
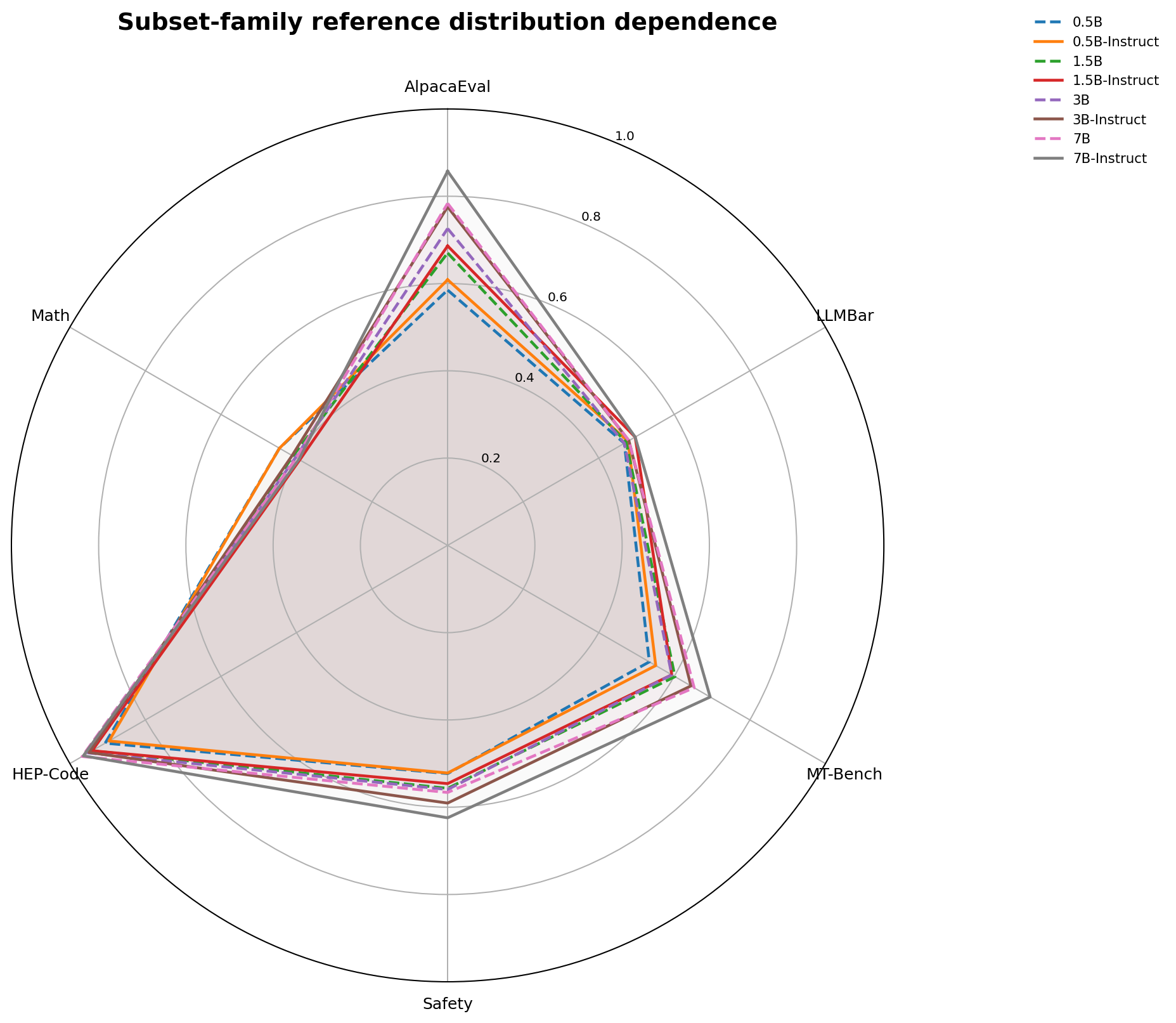
第二组实验也很有意思。我们能明显看到模型在不同偏好类别上的表现并不一致。这说明模型能力并不是一个全面均匀增强的东西,而是在不同 preference distribution 上有不同的形状。
比如论文里的 subset-family radar plot 显示,模型在 code-related subsets 上通常有较高 agreement,而在 adversarial、refusal、safety 相关 subsets 上表现会更低。这正好支持前面的理论说法:alignment 必须相对于参考分布来谈。
这里还有一个特别好玩的现象:在某些数学相关 subset 上,小模型反而表现得更好,甚至 0.5B 可能比更大的模型更突出。这个现象可以有几种解释。一个可能的解释是,这几个模型尺寸本身都还比较小,后续 instruction tuning 或其他训练目标可能改变了模型对数学文本的 likelihood 分布,甚至在某些局部能力上产生了挤占。另一个可能是这个 subset 本身的数据分布、response 风格或长度结构,使得 token-normalized likelihood 更偏向某类模型。无论如何,这个现象非常有意思,因为它提醒我们:模型变大或被 instruction tuned,并不意味着所有偏好维度都会单调增强。
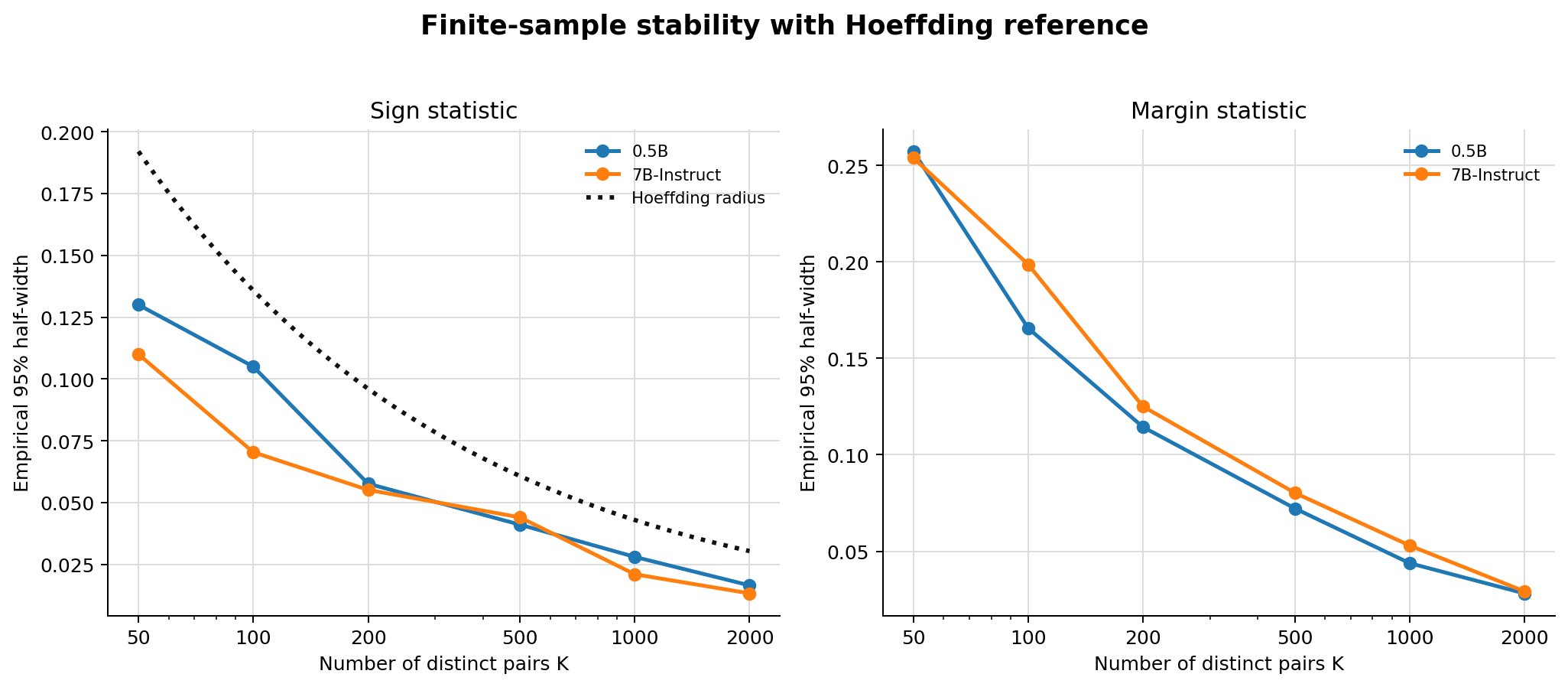
第三组实验是统计分析。这里可以看到,经验不确定性确实随着样本数增加而下降。对于 sign statistic,Hoeffding bound 给出了一个保守但非常清晰的参考曲线。实验中 bootstrap 的区间通常比 Hoeffding radius 更窄,这也符合预期:Hoeffding 是 distribution-free 的保守 bound,而 bootstrap 使用了观测数据的经验分布。
在 full RewardBench size,也就是 $K=5120$ 的情况下,sign statistic 的 Hoeffding radius 大约是 0.0190,而 bootstrap half-width 通常在 0.011 到 0.013 左右。这说明 full-sample estimate 已经相当稳定。
所以这三组实验合在一起,给了一个非常完整的闭环:
- 整体结果说明这个 observable 能区分模型 size 和 instruction tuning。
- subset 结果说明它确实依赖参考 pair 分布,而不是模型的无条件属性。
- finite-sample 和 bootstrap 结果说明它有清晰、可解释的统计行为。
当然,这些实验的 scope 也很清楚:目前只覆盖了一个模型家族、一个偏好 benchmark,以及一种 likelihood-induced scoring rule。它不是最终的全面验证,但作为一个探索性 paper,我觉得它已经把核心 idea 验证得非常完整了。
Workflow
然后这一段我觉得有必要专门讲一下我整个 paper 的 vibe research workflow。说实话,我是真的没有想到这篇文章只用 4 天就可以做完。
DAY1
第一阶段做 idea 构思的时候,我觉得一个很重要的 insight 是:我构建了一个 context 库。里面大概分成两类,一类是 open questions,另一类是 insights。基本上我就是跟 Codex 讨论,然后让它把讨论完的 idea 写到 Markdown 文档里,并且按照这两个分类归档。
这样做的一个巨大好处是,从一个 idea 向另一个 idea 迁移会非常迅速。我可以直接告诉它:你参考某几个 idea 里面的思路,把它改一下,看看能不能这么做。
第二个好处是,这个库维护了大量 context。你会发现,把一个问题定义清楚,其实需要相当多的定义、背景和中间推理。有时候人自己其实也没那么容易把事情搞清楚,但 Agent 可以很快帮你梳理出来。然后你只需要站在更上层,做关键问题的判断和逻辑方向的选择。
就像我最开始讲的这一系列问题,其实都是我在中间不断追问 Agent 的结果。最开始的时候,这个 idea 的清晰度完全没有这么高。但大概问了四五个问题、迭代几轮之后,我的 insight 里就出现了一个非常明确、而且可以计算的核心量。
这个过程确实让我很震惊。比如把大模型和能量模型联系起来这件事,我可能一年前就已经隐隐约约有一点直觉。但如果要把这件事明确推下去、验证下去,其实需要花不少时间。你要推公式,要写定义,要做推导。由于这不是我的主业,所以我一直没有真正开这个头。正常来说,我可能起码要花一周,或者好几天。
但这一次我用了 Agent 加 idea 库的工作方式,从早晨建立 idea 库,到下午不断聊天,整个 idea 包括其中最重要的 Hoeffding bound 推导,就已经基本完成了。
DAY2
第二天基本就把论文写好了。这个时候,之前 idea 库的 context 复用就体现出来了。
我直接把 insight 文档扔给 Agent,让它帮我写一份中文草稿。然后我跟它讨论几遍,对章节顺序和逻辑进行调整。之后再次复用 context,让它从中文草稿直接生成整篇 LaTeX 论文。再之后就是逐段修改。
Agent 不太可能一开始就把整篇文章的所有细节都写成你设想中的样子。但它确实能非常迅速地搭出一个框架。你只需要在这个框架上做局部优化。
这个过程中还有一件很有意思的事:它进一步深化了我对这个 idea 的理解。我发现这个 idea 其实特别明确。让你直接写一篇论文很困难,但是让你判断一篇论文写得好不好,就容易很多。用抽象一点的话说,判别器比生成器容易。
再进一步,即使让我去看一篇文章或一段话,判断它到底好不好,其实也有点费事。效率最高的方式是通过 git diff 比较着看:它到底改了哪里?是改得更好了,还是改坏了?这个时候你会发现,比较器甚至比判别器还要简单一些。
我后来意识到,这种工作流本身可能也启发了这篇 paper 的 idea:很多时候,比较关系比绝对评分更容易、更稳定。
DAY3
到实验这一步的时候,我有一点放飞自我。我就想问:能不能连实验也让 Agent 帮我外包出来?事实证明,如果你对整个事情的目标和边界把控到位,这也是完全可行的。
这里有几个我觉得非常有价值的经验。
首先是进一步的 context 复用。我直接把之前的 idea insight 和论文初稿扔给 Agent,让它帮我生成实验设计。Agent 最初生成的实验,有些并不一定很好。这个时候你自己的问题必须是清晰的。你要主动追问:这个实验的目的是什么?它验证的是哪个假设?能不能改一改,让它更准确地服务于这个目的?
然后再让它把这些实验落实到实验设计文档里。这既方便你自己看,也会成为后面写代码的依据。
代码部分,我觉得我在工程上做了几个非常好的决定。
第一个是测试到底。要确保每一步都是可验证、可测试的。我专门让 Agent 写了很多测试性代码,而且把测试拆成多个层次。
比如我意识到这次实验需要租服务器跑,就让 Agent 专门写了检查依赖是否满足要求的脚本。然后又让它写模型和数据集是否能正常下载、正常加载的测试脚本。下一层是 CPU smoke test,用来测试基础实验代码框架是不是可以跑。再下一层是小样本 GPU test,用很小的样本数覆盖真实实验需要跑的主要参数,但总计算量很小,避免一上来就爆显存。
至于具体实验代码,反而比较简单。我基本上告诉 Agent 需要写什么实验,它就可以把代码写出来。中间当然会有一些细节需要人来把控,比如接口怎么设计、结果怎么保存、哪些中间数据要缓存。但这些事情最好提前告诉它;即使中间再改,也不是特别难。
这次有一些我一开始没想到、后来发现非常有道理的工程设计。比如 Agent 会把 GPU 计算密集的部分缓存成中间数据;我也要求它把实验的详细配置、运行结果、参数都写到结果目录里,并且用 SwanLab 记录。Agent 写代码太快了,让它多写一些辅助功能,对它来说不是大事。但这些东西对后续 debug、数据复用和结果追溯都非常有意义。
这些操作极大提高了我的效率。最后跑代码用的是 AutoDL 平台。这个平台最困难的事情其实有两个:第一是抢不到显卡,第二是配环境。中间最耗时的步骤是下载所有数据集和模型,用了 15 个小时。
这个时候你就会发现,之前让 Agent 写的那些小测试脚本,就像给它提供了一整套工具。它可以自己执行、自己观察反馈、自己继续推进。我配环境那段基本就是直接给 Agent 开了一个任务,告诉它:根据这些测试脚本的要求,去执行脚本,把环境配好。然后我就去睡觉了。
第二天早上发现,Agent 还没完全结束,但那些脚本已经把所有依赖环境都下载好了。之后它又很快跑了一遍整体验证流程,发现实验整体可以执行。这就是分步式验证非常大的魅力。如果你一边跑实验,一边下载数据,一边处理依赖,即使让 Agent 自动化去跑,整个流程也很难处理得很好。
DAY4
所以到第四天早上,当我发现 Agent 跑了 15 个小时,已经把环境配好,而且之前所有小测试流程都能通过时,我对整个实验代码有了非常大的信心。后面的事情就非常迅速,也很水到渠成。
其中唯一的小波折是,我发现原来节点的显卡被别人抢走了,抢不上了。于是又做了一次镜像迁移,把代码和数据迁到另一个节点上。挂上显卡之后,就让 Agent 自己去跑实验。
由于之前大量测试已经覆盖了主要问题,所以后面大部分都是很小的问题,Agent 可以很快解决。整个实验中所有计算密集的中间变量,在两个小时内基本全部算完。然后我又补了一下后续实验的代码,让 Agent 放上去继续跑。差不多在第二天中午,实验就搞定了。
这个时候,之前把实验结果明确输出到结果路径里的设计就变得非常有意义。我直接让 Agent 根据这些数据生成一份实验报告,并且继续在高层次把我问题:里面应该插入哪些数据?放哪些表格?画哪些图?
画图这件事,也不要让 Agent 手动画。更好的方式是让它写画图程序,并且把输入路径和输出路径全部配置好。这样只需要一个脚本,就可以快速完成整个画图流程,也可以很容易替换所有图片。后续我修改图也变得非常方便。
等实验报告基本把重要数据和想展示的图表都放进去之后,其中需要强调的逻辑也基本 OK。然后再次复用之前的 context,让 Agent 根据实验报告生成 LaTeX 版本。校对几轮之后,它把整段插入论文原文,再对全文进行整体润色。整篇文章就基本完成了。
整个过程速度之快,让我感到有些震惊。并且确实有一种停不下来的感觉:你所有的 idea 和想法都能够被迅速验证和执行,你可以忽略所有烦恼的细节,而关注核心的问题和方向的把控。这种快乐是真的让人不想停。高强度工作了 4 天,感觉恍若隔世。想到上周五这个 idea 还模模糊糊、完全不清楚,而这周五整篇文章已经完成并上传了arxiv,这种感觉非常奇妙。
Review
那么这篇文章有什么问题呢?
首先,我们看一下 GPT 的审稿意见。它其中说的第一条是:pairwise comparison 这个思想在大模型领域里已经被广泛使用了,比如 DPO 的训练、reward model 的训练,甚至包括模型之间比较的 Model Elo。所以它并不是一个很新的东西,有点 lack of novelty。
审稿人那种 mean 的感觉扑面而来,直接给我看 PTSD 了。
这条确实不好反驳,并且真的审稿人估计也会这么问,不过我觉得这条其实说得不太对,审稿人果然读不懂你的文章。我们这个问题的引入和思考路线其实是不一样的。虽然用相对比较样本来学习或评估这件事已经出现过很多次,但我们这里既不是训练 reward model,也不是做模型之间的相对排名。我们想做的是:通过样本 pair 所体现的参考分布本身,去定义并估计一个固定模型的 model-level observable。
并且我很关心样本数量和估计误差之间的关系。这其实更接近统计推断的思想:有限 eval set 不是最终对象,分布上的 estimand 才是最终对象。
第二个问题,也是文章目前最大的问题,是实验还不够 scale up。模型尺寸选得有些小,数据集也比较单一。如果要正式发一篇更强的论文,必须补更多数据集,也应该尽量把推理模型、更多 model families、更大模型都纳入进来。
还有一个比较致命的点是解释边界。虽然 energy view 听起来很合理,也很好听,但它并不能保证模型一定会生成这样的样本。模型给样本 A 比样本 B 更高概率,或者说 A 的能量比 B 更低,只能说明在模型分布里 A 相对更容易出现;但这并不能保证模型在真实生成过程中一定会生成 A。尤其在 decoding、采样策略、prompt format 等因素介入之后,这件事会更复杂。
不过,正因为这个框架足够 general,它其实并不限定必须用于语言模型,也不限定 score 必须是 log-likelihood。它也可以用于 reward model、judge model,或者其他任何 scalar scoring function。比如评价一个 LLM-as-a-judge 的偏好对齐度时,让 judge model 给两个 response 打分,然后看它的排序是否符合参考分布,这可能就是一个很自然的应用。
第三点,也是我觉得最重要的一点:作为一篇探索性的文章,我觉得它已经很好了。它提出了一个问题,并且在理论和实验上都给出了相当完整的验证。这件事本身就非常快乐。
但是如果我想把它进一步应用到具体场景里,就会发现自己缺 context。也就是说,我缺少对应实际领域的背景知识,缺少那个领域里真正需要解决的问题、假设和约束。
就像上面提到的 judge model 评价,这可能是一个不错的方向。但我自己没有深入做过这个方向,因此缺少相应 context。如果我为了发论文而 overclaim,过分强调这个方法有多么好、可以应用到什么什么问题上,我觉得这反而是不严谨的。那样的话,它就从一个原本真诚的探索,变成了为了发文章而发文章。
当然,如果真的想把它打磨成更完整的投稿版本,估计还要花不少时间补实验和补应用场景,至少可能需要一个月到两个月的投入。与其这样,不如先把这篇文章发出来,看看能不能启发到一些人。也许某个有对应领域背景的人,会发现它正好能用在一个很有意思的问题上。这可能也是科研本身的目的和快乐所在。
所以我直接把它挂 arXiv 了,实验代码也放出来了:
https://arxiv.org/abs/2605.30758
https://github.com/leemojiang/pairwise-reference-alignment
最后,这也算是给自己打一个广告。正如前面说的,我现在太缺 context 了。我正在找机会:无论是 RA、实习,还是正式工作.并且我的时间现在很flexible.如果有任何机会,欢迎联系我!