MiniMind 学习笔记
这本书用于系统整理我基于 MiniMind 项目以及之前零零散散的的 LLM 学习笔记。希望能把大部分LLM相关的内容都串起来,形成一个比较完整的学习地图。内容会持续更新,欢迎大家一起讨论和补充。
我自己的感觉是,LLM 的学习除了算法理论层面,更重要的是实践层面。之前我看了很多课程和文章,也推了很多公式,但是直到我自己亲自写了一遍代码,把这些算法和概念对应到具体实现上之前,始终有一种“看懂了,但没有真正理解”的感觉。很多东西单看原理会觉得明白了,但一旦落到训练流程、张量维度、数据处理和代码实现上,就会发现这中间其实还隔着很多层。
学习方法
所以我现在越来越觉得,入门 LLM 时最重要的事情之一,不是先把所有理论一次性学完,而是先建立起一个整体框架,然后尽快去做一些能在短时间内看到反馈的实践。因为如果一开始就扎进大量细节里,很容易在各种术语、公式和论文之间迷失;但如果能先把一个最小流程跑通,再回头去看很多概念,就会清楚很多。
实践推荐
这里我特别推荐 MiniMind 这个项目。它是一个非常完整的 LLM 训练框架,真正做到了让你从零到一自己训练一个模型。并且它把整个流程,以及其中大部分核心概念,都用大部分人可以真正上手实现的代码展现了出来。尤其是训练部分,我自己最大的感受就是:会写 Transformer,和真的能把一个模型训练出来,是完全不同的两个概念。
问题导向
我这部分笔记就是基于这个学习过程的整理。另一点我希望以问题导向来串联这份笔记,目标不是简单堆知识点,而是尽量把学习 LLM 时那些真正关键的问题串起来,既能构建一个整体框架的骨架,作为学习地图,又能随时把细节核心的东西插入到这棵搜索库的合适位置,比如:
- 一个 LLM 系统整体包含哪些部分?
- 模型的输入输出到底是什么?
- Tokenizer、Embedding、Attention 这些模块在代码里到底长什么样?
- 预训练、微调、对齐这些概念在训练流程里分别对应什么?
我会尽量按照“先有整体认识,再进入细节;先能动手,再补理论;用问题串起学习过程”的思路来整理这些内容。这样一来,笔记更像是一份持续生长的学习地图,而不只是零散的知识摘抄。
这部分笔记大概会分为三种类型的介绍:
- 理论方面:主要整理一些核心概念的理解,比如什么是预训练、什么是微调、什么是 DPO 等,以及相关的算法背景。
- 实践方面:主要记录代码实现的细节,比如如何准备数据、如何理解训练流程,尤其是训练部分的一些关键实现和实际操作。
- Tips 方面:我会把一些常用的代码写法和经验整理成 cookbook,比如 PyTorch 的常见用法、调试时容易遇到的问题等。
环境准备与项目结构
对于一个项目,最好的办法是最快的把它跑起来.在这个过程中,我们可以先不纠结细节,先把环境搭建好,把代码跑起来,再慢慢去理解它的细节和原理.
项目结构
一个适合长期学习和反复实验的项目,首先要有清晰的目录结构。原始的 MiniMind 仓库已经比较清楚,而这个仓库又在它的基础上做了一层适合学习和维护的整理。
原始项目里比较核心的部分大致是:
model:模型定义trainer:不同训练阶段的脚本dataset:数据集与数据加载逻辑scripts:转换、评估等辅助脚本
在这个仓库里,我们进一步改成了更适合 Python 工程化维护的 src layout,并补充了一些学习笔记和测试目录。现在比较重要的目录可以这样理解:
src:项目的核心代码,包含模型定义、训练代码、数据集实现等scripts:辅助脚本,例如转换、评估和实验工具notes:学习笔记,后续会组织成 mdBookminimind_upstream:上游参考代码,使用 submodule 管理configs:配置文件tests:测试代码
如果只是第一次进入这个仓库,建议先把注意力放在 src、notes 和 minimind_upstream 这三个目录上:前者是当前可运行代码,中间是学习记录,后者用于对照原始实现。
项目管理工具
这个项目推荐使用 uv 作为依赖管理工具,并配合 src layout 组织代码。
# 同步项目依赖
uv sync
# 以开发模式安装当前项目
uv pip install -e .
uv 是一个现代的 Python 包管理工具,安装速度快,依赖解析也更稳定。不过它同时提供了两套常见接口:
uv add/uv remove:会修改pyproject.toml,适合把依赖正式加入项目uv pip install/uv pip uninstall:只操作当前环境,不修改项目声明
两者的区别可以简单理解为:
- 如果你想把一个包正式纳入项目依赖,使用
uv add - 如果你只是临时试验某个包,使用
uv pip install
例如:
# 正式修改项目依赖
uv add package_name
uv remove package_name
uv add -r requirements.txt
# 仅操作当前环境(只需要把传统的pip 换成uv pip)
uv pip install package_name
uv pip install -r requirements.txt
uv pip uninstall package_name
查看当前环境依赖时,也可以直接使用:
uv tree
uv pip list
uv pip show package_name
用 uv 配置 PyTorch
PyTorch 的安装和一般 Python 包不完全一样。很多 CUDA 版本的 PyTorch 目前不再支持类似 torch==2.2.0+cu121 这样的版本后缀来选择,而是通过不同的软件源安装。
也就是说,如果你直接执行:
uv add torch
默认通常会从 PyPI 安装 CPU 版本。
如果你想安装 CUDA 版本,需要在 pyproject.toml 里为 torch 和 torchvision 单独指定源。这个思路和 PyTorch 官网用 pip --index-url 安装 CUDA 版本本质上是一样的。
可参考 uv 的官方说明: Configuring accelerators with environment markers
本项目当前采用 optional-dependencies + tool.uv.sources 的方式,分别适配 CPU 和 CUDA 环境:
# 安装 CPU 版本
uv sync --extra cpu
# 安装 CUDA 版本
uv sync --extra cuda
这里有一个容易踩坑的点
uv 的 extra 机制在实际使用中有一个容易让人困惑的地方:
如果你之前通过 uv sync --extra cuda 安装了 CUDA 相关依赖,之后再执行普通的 uv sync,而默认依赖里又没有包含这些包,那么 extra 对应的依赖可能会被移除。
这也是为什么这里建议把 CPU 和 CUDA 共有的核心依赖版本同时写进 dependencies,再通过 sources 控制不同平台实际从哪个索引下载。
下面是当前项目采用的一种可行配置:
dependencies = [
"swanlab>=0.6.13",
"transformers>=4.57.1",
"torch>=2.9.0",
"torchvision>=0.24.0",
]
[tool.uv]
conflicts = [
[
{ extra = "cpu" },
{ extra = "cuda" },
],
]
[project.optional-dependencies]
cpu = [
"torch>=2.9.0",
"torchvision>=0.24.0",
]
cuda = [
"torch>=2.9.0",
"torchvision>=0.24.0",
]
[[tool.uv.index]]
name = "pytorch-cu126"
url = "https://download.pytorch.org/whl/cu126"
explicit = true
[[tool.uv.index]]
name = "pytorch-cu126_c"
url = "https://mirrors.nju.edu.cn/pytorch/whl/cu126"
explicit = true
[[tool.uv.index]]
name = "pytorch-cpu"
url = "https://download.pytorch.org/whl/cpu"
explicit = true
[tool.uv.sources]
torch = [
{ index = "pytorch-cu126_c", extra = "cuda" },
{ index = "pytorch-cpu", extra = "cpu" },
]
torchvision = [
{ index = "pytorch-cu126_c", extra = "cuda" },
{ index = "pytorch-cpu", extra = "cpu" },
]
简化理解 uv 在这里做了什么
注: uv的extra机制有一点混乱,上面的官方示例有一些问题,使用uv sync --extra flag 安装包,之后每次添加或者移除包执行uv add/remove 或者uv sync会导致extra对应的包被移除,需要重新执行一遍uv sync --extra flag 来安装对应的包.
解决办法是再dependencies里面添加torch cpu 和 CUDA 共通的依赖版本.如下面案例所示.
注: UV extra的解析机制,UV 会做这么几件事情:
-
Configuration Validation(配置校验)
- 检查 extras 是否互斥
- 检查 conflicts 是否自洽
- 检查 pyproject.toml 是否结构正确
- 检查 index 配置是否冲突
-
Dependency Resolution(依赖解析)
- 合并依赖
- 合并 extras(已启用的), dependencies中的依赖会被默认启用,但是extra中的默认不启用,只有加入extra flag才会启用.
- 选择版本
- 生成锁定图
- 类似的命令 uv pip compile pyproject.toml
-
Installation(安装)
- 下载 wheel/sdist
- 安装到 .venv
uv remove
会修改 pyproject.toml uv 必须确保修改后的项目配置是“合法的”所以会先执行 Configuration Validation这一步会检查 extra conflicts即使 extras 没启用,也会检查 conflicts 是否自洽,所以会报错.但是这个报错又不影响安装.
uv sync
不修改 pyproject.toml
uv 不需要重新验证配置
uv 默认不启用 extras
所以不会触发 conflicts 检查
直接进入 dependency resolution → installation
但是dependencies中是最小依赖,所以不会重新安装,而如果dependencies中没有torch,默认的uv sync 不会解析extra,就会移除extra中的torch,所以需要重新执行uv sync --extra flag 来安装对应的包.
(这实在是有点混乱了,也许以后会改,总而言之下面的配置是目前最佳实践)
可以把它粗略分成三步:
- 配置校验:检查
pyproject.toml、extras、conflicts和索引配置是否合理。 - 依赖解析:合并默认依赖与启用的
extra,然后解析版本。 - 执行安装:下载 wheel 或 sdist,并安装到虚拟环境中。
一个很重要的区别是:
uv remove会修改项目声明,因此会先做完整的配置校验uv sync不修改项目声明,默认也不会启用额外的extra
这就会导致看起来“不报错但包没了”的现象。理解这一点以后,很多看似奇怪的行为就容易解释了。
检查当前 PyTorch 是否支持 CUDA
import torch
print(torch.cuda.is_available())
print(torch.version.cuda)
登录 SwanLab
训练脚本里虽然保留了 --use_wandb 这个参数名,但实际导入和使用的是 swanlab。因此同步完依赖后,建议先完成登录:
swanlab login
这样后续运行训练脚本时,实验日志才能正常记录。
Pretrain 导言
这一章的目标,不是立刻进入大模型的细节,而是先回答一个更基础的问题:当我们说“从零开始理解一个 LLM 的预训练流程”时,到底需要先想清楚哪些问题?
我现在越来越觉得,直接进入训练代码很容易陷入局部细节,比如某个张量 shape、某个配置项、某一层的实现方式。但如果没有先建立整体框架,这些局部细节很难真正串起来。所以这一章会先从问题出发,再逐步进入模型定义和代码实现。
这一章我准备分成两个部分, 第一部分先介绍模型是什么这个概念,准备围绕下面这些问题展开:
- 什么是 Language Model?为什么说 LLM 本质上仍然是 Language Model?
- 为什么进入 LLM 之前,需要先理解 Attention 和 Transformer?
- Transformer 相比更早的 NLP 模型,到底解决了什么问题?
- 一个LLM在通常由哪些模块组成?它的Pretrain训练流程又是什么样子的?
- Embedding、Attention、FFN、Norm、RoPE 这些模块分别在做什么?
- 为什么很多模型结构上的选择,看起来像“工程细节”,但实际上会影响训练效果和推理效率?
- 如果把目光放回 MiniMind,这个项目是如何把这些概念落实成可运行代码的?
这一章的组织方式会尽量按照 QA 的形式展开。也就是说,每一节开头都会先列出一组核心问题,然后围绕这些问题组织内容,而不是一开始就按教科书式定义平铺直叙。
目前这一章模型部分先分为四个部分:
- 背景部分:从 Language Model、Attention、Transformer 的发展脉络出发,建立整体认识。
- 模型总览:先不急着推公式,而是先回答“一个预训练模型由哪些部分组成”。
- Attention 专题:把最核心、也最容易在概念和实现之间脱节的部分单独展开。
- MiniMind 实践入口:回到项目本身,看看这些概念在代码和训练流程里是怎么落地的。
至于训练目标、loss、优化器、learning rate、混合精度这些问题,我准备放到后续单独开一个部分单独展开。因为这些内容一旦开始讲,重心就会从“模型是什么”切到“模型怎么训练”,适合单独成节。
背景: 从 Language Model 到 Transformer
这一节先不急着进入代码,而是先回答几个最基础的问题:
- 什么是 Language Model?
- 为什么说 LLM 仍然是 Language Model,而不是一个完全不同的东西?
- 为什么学习 LLM 时,往往要先回到 NLP 的发展脉络?
- 从 NLP 的视角看,LLM 和经典 NLP 流程之间是什么关系?
- 从 NLP 的视角看,一个 Language Model 的输入和输出到底是什么?
- Transformer 相比之前的方法,到底解决了什么问题?
Q1: 什么是 Language Model?
如果先忽略 “Large” 这个词,LLM 首先是一个 Language Model。
Language Model 的核心任务可以粗略理解为:给定前面的文本,预测后面的文本出现的概率。
更准确地说,假设一个 token 序列写成:
$$ x_1, x_2, \dots, x_T $$
其中:
- $x_t$ 表示第 $t$ 个 token
- $T$ 表示整个序列的长度
那么一个语言模型想做的事情,是建模这个序列的联合概率:
$$ P(x_1, x_2, \dots, x_T) $$
通常我们会把它按链式法则改写成:
$$ P(x_1, x_2, \dots, x_T) = \prod_{t=1}^{T} P(x_t \mid x_1, x_2, \dots, x_{t-1}) $$
这个式子背后的意思很直接:整个句子的概率,可以拆成“每一步根据前文预测下一个 token”的概率连乘。
所以从这个角度看,LLM 的核心并没有变。它仍然是在做:
- 给定前文
- 预测下一个 token 的分布
只是它的模型规模更大,训练数据更多,结构设计更强,最终表现出了更强的泛化能力和涌现能力。
Q2: 为什么说 LLM 仍然是 LM?
很多时候我们会觉得 LLM 已经像一个“会聊天、会推理、会写代码”的复杂系统了,于是很容易忽略它最基础的一层:它依然是一个 next-token predictor。
这点在代码层面会体现得非常明显:
- 输入通常是一串 token id
- 模型输出通常是一组 logits
- logits 经过 softmax 之后变成词表上的概率分布
- 然后根据这个分布选择下一个 token
也就是说,不管外面包了多少对话模板、system prompt、tool call、采样策略,模型内部最核心的计算目标依然没有变。
所以如果不先理解 Language Model 这件事,就很容易把很多“高层能力”看得过于神秘。
Q3: 为什么学习 LLM 时,往往要先回到 NLP 的发展脉络?
如果直接从今天的 LLM 出发,很容易碰到一种情况:术语很多,模块很多,训练技巧很多,结果所有东西都像是平铺在一起的。
但如果把视角往前退一步,就会发现很多关键问题其实都是沿着 NLP 的发展脉络一步一步演化出来的。
我觉得一个比较自然的主线大概是:
word2vec -> word embedding -> seq2seq -> attention -> transformer -> GPT 系列 -> ChatGPT / 当代 LLM
如果再加上一些标志性的时间节点,会更容易形成整体印象:
- 2013 年前后:
word2vec让“词向量”真正成为神经网络 NLP 里的基础部件 - 2014 年:Attention 机制被明确提出,用来缓解 seq2seq 中的信息瓶颈问题
- 2017 年:Transformer 提出,用 attention 作为主干结构
- 2018 年:BERT 让预训练语言模型成为 NLP 的主流范式之一
- 2019 年:GPT-2 展示出大规模自回归语言模型的潜力
- 2020 年:GPT-3 让 in-context learning 成为一个无法忽视的现象
- 2022 年:InstructGPT、ChatGPT 让 “pretrain + alignment” 这条路线成为主流产品形态
如果把时间线继续往后推,2023 到 2026 这一段我觉得还可以再看到两条很重要的支线:
一条是“对齐 / RL / 偏好优化”的演化,另一条是“工具使用 / agent 化”的演化。
2023-2026: 对齐、RL 与偏好优化
- 2023 年:GPT-4 进一步强化了 “大规模预训练 + 后训练对齐” 这条路线
- 2023 年:DPO(Direct Preference Optimization)开始被广泛讨论,它把原来比较复杂的 RLHF 流程做了更直接的改写
- 2024 年:像 DeepSeekMath 这样的工作把 GRPO 这类方法带进更具体的推理训练场景
- 2025-2026 年:推理能力、可验证任务、偏好优化和 RL 的结合变得越来越重要,尤其是在数学、代码和复杂决策任务上
这一条线的核心变化可以概括成一句话:
模型不再只是“先预训练,再简单微调”,而是越来越强调如何通过偏好数据、可验证反馈和后训练过程,把模型的行为进一步往目标能力上推。
2022-2026: tool use 与 agent 化
- 2022 年:ReAct 把“推理”和“行动”放到一个统一框架里讨论
- 2023 年:Toolformer、OpenAI function calling 这类工作和产品,让“模型调用外部工具”开始变成一个明确方向
- 2024 年:Anthropic 发布 computer use,开始把模型直接操作屏幕、鼠标和键盘这类能力产品化
- 2024 年底:MCP(Model Context Protocol)提出,把模型连接外部工具和数据源这件事进一步标准化
- 到 2025-2026 年:我更倾向于把这一阶段概括成 agent 系统快速升温。重点不再只是“模型能回答什么”,而越来越是“模型能不能调用工具、维持状态、分解任务并执行多步流程”
这里最后一句是我的概括,不是某一篇论文的单点结论。
如果只看过去几年最明显的变化,我觉得确实可以把它理解成:LLM 的发展正在从“更强的语言模型”逐步走向“更强的推理、工具使用和行动系统”。
这条发展线重要的地方,不是让我们去背年份,而是帮助回答两个更核心的问题:
- 每一个新方法最初是在解决什么问题?
- 后来的方法又是如何对前者进行改进的?
比如:
- 为什么需要从 one-hot 走向 embedding?
- 为什么 seq2seq 会遇到长距离依赖和信息压缩的问题?
- 为什么 attention 会成为关键突破?
- 为什么 Transformer 能逐渐取代以 RNN/LSTM 为核心的主干结构?
- 为什么今天的 LLM 虽然规模大得多,但依然能够在 NLP 的历史中找到清晰来源?
所以我更倾向于把 LLM 看成是 NLP 发展链条上的延续,而不是一个与之前工作完全断裂的新东西。
如果这些问题不清楚,那么后面再看 Multi-Head Attention、RoPE、GQA、KV Cache,就很容易只看到“又多了一堆模块”,而不知道它们是在解决什么。
如果把这条线继续往后展开,到 RL、偏好优化、tool use 和 agent 的发展,我另外单独整理了一节:历史脉络: 从 NLP 到 LLM, 再到 Agent。
Q4: 从 NLP 的视角看,LLM 和经典 NLP 流程之间是什么关系?
很多时候我们会以为,LLM 出现之后,之前 NLP 里的很多基本处理流程就不重要了。其实不是。
如果从一个更传统的 NLP 视角看,一条典型链路大致是:
原始文本 -> 文本切分 / tokenization -> id 化表示 -> 向量表示 -> 模型编码 -> 输出层 -> 任务目标
放到今天的 LLM 里,这条线依然成立,只是其模型编码环节被统一到了自回归模型(AR)框架里。
例如:
- 文本仍然要先经过 tokenizer,变成离散 token
- token 仍然要变成 embedding,才能进入神经网络
- embedding 之后仍然要经过多层变换,只是今天这部分主干通常是 Transformer block
- 模型最后仍然要通过输出层,把隐藏状态映射回词表空间
也就是说,今天的 LLM 虽然在模型规模、训练数据和能力表现上已经和早期 NLP 模型很不一样,但它内部的处理流程并不是凭空出现的。
从“文本如何变成可计算对象”到“模型如何输出词表上的分布”,这条主线依然和经典 NLP 工作一脉相承。
这也是为什么我更倾向于从 NLP 的视角引入大模型。因为这样很多问题会变得自然:
- tokenizer 为什么重要?
- token id 为什么不能直接用于表示语义,而要先变成 embedding?
- 为什么输出不是一个词,而是一整个词表上的 logits?
- 为什么很多老问题,比如表示学习、上下文建模、长距离依赖,到今天依然还在,只是换了一套更强的结构来处理?
Q5: 从 NLP 的视角看,LM 的输入和输出是什么?
如果从 NLP 的角度看,Language Model 的输入输出其实可以分成两个层面:
- 从“数据接口”的角度看,输入是 token id,输出是词表上的分数或概率。
- 从“模型内部表示”的角度看,输入会先变成 embedding,输出则会经过 language modeling head 变成 logits。
一个比较常见的处理流程可以先写成:
文本 -> tokenizer -> token id -> embedding -> transformer -> logits -> 概率分布
这里可以逐步理解:
- 原始输入首先是文本
- tokenizer 把文本切成 token,并映射成整数 id
- token id 再通过 embedding 层变成连续向量
- 模型主体对这些向量做一系列变换
- 最后输出 logits
其中 logits 可以理解成:
模型对词表中每个候选 token 给出的原始分数,它还不是概率。
如果词表大小记作 $V$,那么对于序列中的某个位置,模型最终输出的往往是一个长度为 $V$ 的向量:
$$ z \in \mathbb{R}^{V} $$
其中:
- $V$ 表示词表大小
- $z_i$ 表示第 $i$ 个 token 对应的原始分数
再经过 softmax,才会变成真正的概率分布:
$$ P(x_t = i \mid x_{<t}) = \frac{e^{z_i}}{\sum_{j=1}^{V} e^{z_j}} $$
所以如果只抓住最关键的一层,可以把 LM 的输入输出理解成:
- 输入:前文对应的 token 序列
- 输出:下一个 token 在整个词表上的概率分布
而 embedding、hidden states、logits 这些概念,就是这条链路中间的内部表示。
Q6: Transformer 相比之前的方法解决了什么问题?
在进入 Transformer 之前,很多 NLP 模型依赖 RNN、LSTM 这类按时间步递归处理序列的结构。它们当然有自己的价值,但也存在一些明显限制:
- 序列计算难以并行
- 长距离依赖难处理
- 信息需要跨很多时间步传递,优化困难
Attention 的核心思想可以粗略理解成:
在处理当前位置时,不必只依赖一个压缩过的历史状态,而是可以直接去“看”整段上下文里和当前最相关的部分。
Transformer 更进一步,直接把 attention 放到模型的中心位置,用它来完成序列内部的信息交互。这带来了几个非常关键的好处:
- 更容易并行计算
- 更容易建模长距离依赖
- 在工程上更适合大规模训练
这也是为什么今天在讲 LLM 时,虽然表面上会讨论各种新结构,但真正的主干依然是 Transformer 这一套范式。
这一节之后要带着哪些问题往下看?
如果这一节只留下几个最重要的问题,我觉得是下面这些:
- 既然 LLM 本质上还是 Language Model,那么它的输入和输出在代码里具体长什么样?
- 文本是如何一步步变成 token id 的?为什么今天通常不是直接按“词”来切分?
- Transformer 既然是当前 LLM 的主干结构,那么一个 Transformer 模型具体由哪些模块拼起来?
- Attention 为什么会成为整个结构的核心?
所以下一节先单独回答一个更基础的问题:文本到底是怎么变成 token id 的,也就是 tokenizer 在整个流程里扮演什么角色。
历史脉络: 从 NLP 到 LLM, 再到 Agent
这一节想单独整理一个更长一点的历史视角。目标不是把所有论文都列一遍,而是先把主干路线梳理清楚:
- 从传统 NLP 到 Transformer,这条线是怎么发展的?
- 从 Transformer 到当代 LLM,标志性的节点工作有哪些?
- RL、偏好优化和后训练为什么会在近几年变得越来越重要?
- 为什么大家开始越来越多地讨论 tool use 和 agent?
我自己的理解是:
如果把过去十几年压缩来看,大模型的发展并不是突然跳出来的一段孤立历史,而是几条技术路线逐步汇合的结果:
- 表示学习的路线
- 序列建模的路线
- 预训练与对齐的路线
- 工具使用与行动系统的路线
1. 从 NLP 到 Transformer
2013 前后: word2vec 与词向量
这一阶段最重要的变化之一,是“词的表示”开始从离散 one-hot 走向连续向量。
这件事非常关键,因为它让 NLP 里的很多问题第一次可以比较自然地接进神经网络框架。
从今天回头看,embedding 已经像是理所当然的部件,但在当时,它其实代表了一种非常重要的范式转换:
- 文本不再只是符号
- 词也不再只是一个离散编号
- 而是可以嵌入到一个连续空间里
这也是为什么我一直觉得,哪怕今天在讲 LLM,embedding 这件事依然应该放回 NLP 历史里看。
参考:
2014: Attention 机制
Attention 的出现,最初并不是为了“做一个更强的大模型”,而是为了缓解 seq2seq 中的信息瓶颈问题。
在更早的 encoder-decoder 结构里,输入序列往往会被压缩成一个固定长度的中间表示。这种做法在短序列上还可以,但序列一长,信息损失和长距离依赖问题就会变得明显。
Attention 带来的核心想法是:
- 在生成当前输出时
- 不要只依赖一个压缩后的全局状态
- 而是允许模型动态地去看输入中更相关的位置
从今天回头看,这一步几乎可以说是后面 Transformer 和 LLM 整条路线的关键前置条件。
参考:
2017: Transformer
2017 年的《Attention Is All You Need》可以说是整个历史里的分水岭之一。
它的重要性不只是“提出了一个新模型”,而是把 attention 从一个辅助机制推到了主干结构的位置。
Transformer 的几个关键影响是:
- 放弃了 RNN 式的递归主干
- 把序列内部的信息交互交给 attention
- 更适合并行训练
- 更适合大规模扩展
这也是为什么今天再看 LLM,虽然工程细节变化很多,但主干结构依然基本建立在 Transformer 这一套范式之上。
参考:
2018-2020: 预训练语言模型成为主线
这一阶段一个很重要的变化是:
“先做大规模预训练,再针对任务适配” 逐渐成为 NLP 的主流思路。
其中有几个非常关键的节点:
- 2018 年:BERT 让预训练语言模型成为 NLP 的核心方法之一
- 2019 年:GPT-2 展示出更大规模自回归语言模型的潜力
- 2020 年:GPT-3 让 in-context learning 成为一个无法忽视的现象
如果说 2017 年 Transformer 解决的是“主干结构”问题,那么 2018 到 2020 年这段则更像是在回答:
- 这种结构怎样在大规模文本上训练?
- 训练出来以后,它会不会自动长出一些更一般的能力?
参考:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018)
- Language Models are Few-Shot Learners / GPT-3 (2020)
2. 从 LLM 到对齐: 2022 之后为什么变化这么快?
2022: InstructGPT 与 ChatGPT
如果说 GPT-3 让大家重新认识了大模型的规模效应,那么 2022 年之后,一个更明显的变化是:
大家开始越来越重视“模型是否符合人类期望”。
InstructGPT 这一类工作带来的影响是:
- 不再只强调预训练本身
- 而是强调如何让模型更符合指令、更符合偏好、更符合期望行为
这也是为什么“预训练 + 后训练 / 对齐”逐渐成为一个更完整的产品和研究框架。
从产品侧看,ChatGPT 则让这条路线真正变成大众可见的主流形态。
参考:
2023: GPT-4 与 post-training 路线强化
GPT-4 的一个重要信号是:
大模型的发展已经不只是“堆更大的预训练”,而是越来越依赖预训练和后训练的结合。
从技术叙述上看,这时候一个越来越清晰的框架是:
pretrain -> instruction tuning / preference tuning -> 更强的行为质量
也就是说,模型的基础能力和模型的行为方式,开始被更明确地区分成不同阶段来处理。
参考:
3. RL、偏好优化与推理训练
RLHF: 为什么它重要?
RLHF 之所以重要,不是因为 “reinforcement learning” 这几个字听起来高级,而是因为它提供了一种方式,让模型不只是拟合文本分布,还能借助偏好信号进一步调整行为。
简单说,RLHF 的意义在于:
- 预训练回答“模型学到了什么语言分布”
- 对齐回答“模型该如何表现得更符合我们的目标”
所以从历史上看,RLHF 可以理解成“让大模型从会说话,进一步走向更可控”的关键一步。
2023: DPO
到了 2023 年,DPO 之所以引起很多关注,是因为它把原来比较复杂的 RLHF 过程,改写成了一种更直接的偏好优化形式。
它的重要性不一定在于“从此 RL 消失了”,而在于它让大家更清楚地看到:
- 偏好优化本身可以有不同实现路径
- 不一定每次都要走完整的 reward model + PPO 流程
所以从这之后,“偏好优化” 和 “RLHF” 这两个概念虽然仍然高度相关,但也开始出现更细的技术分化。
参考:
2024-2026: 可验证任务、推理能力与 RL 再升温
如果再往后看,RL 在近几年重新升温,一个很重要的原因是:
大家越来越多地把模型放到数学、代码、证明、规划这类“结果更可验证”的任务上。
在这些任务里,光靠静态偏好数据往往不够,因为:
- 任务本身有明显对错
- 中间过程可能涉及多步推理
- 最终目标可以通过程序、测试、规则或答案校验来提供反馈
这时候,RL 和偏好优化的结合就变得更有吸引力。
像 DeepSeekMath 这类工作里出现的 GRPO,可以看成这条线上的代表之一。
它的重要性不只是某一个具体算法,而是说明了一件事:
- 当任务结果可验证时
- 训练模型推理能力这件事,会越来越自然地和 RL 重新结合起来
这也是为什么我会把 2025-2026 这段概括成:
“推理能力、可验证反馈和后训练强化正在进一步汇合。”
参考:
4. Tool Use 与 Agent 为什么会爆发?
2022-2023: 从 reasoning 到 acting
在很多早期讨论里,大模型更多被看成“生成文本的系统”。
但从 ReAct 开始,一个越来越明确的方向是:
- 模型不只是要生成答案
- 还要在推理过程中和环境交互
- 要能调用工具、获取信息、执行动作
ReAct 的重要性就在于,它把 reasoning 和 acting 放进了一个统一框架里讨论。
参考:
2023: Toolformer 与 function calling
到 2023 年,工具使用这条线开始变得更具体。
一方面,Toolformer 从研究角度强调:
语言模型可以学习什么时候调用工具、调用什么工具、以及如何使用返回结果。
另一方面,OpenAI 在 2023 年推出 function calling,则从产品和开发接口层面,把“模型调用外部工具”这件事做成了开发者可直接使用的能力。
这一步非常重要,因为它意味着:
- 工具使用不再只是论文里的设想
- 而开始成为真实系统设计里的默认选项
参考:
- Toolformer: Language Models Can Teach Themselves to Use Tools (2023)
- Function calling and other API updates (OpenAI, 2023-06-13)
2024-2026: 从工具调用到 agent 系统
如果继续往后看,到 2024 年之后,一个更明显的变化是:
讨论重点开始从“模型能不能调用一个工具”,逐渐转向“模型能不能作为一个系统,维持状态、规划步骤、调用多个工具并完成更长任务”。
这里有几个很典型的节点:
- 2024 年:Anthropic 发布 computer use,把模型直接操作屏幕、鼠标和键盘的能力产品化
- 2024 年底:Anthropic 提出 MCP,尝试把模型接入外部数据源和工具这件事标准化
- 到 2025-2026 年:agent 系统开始快速升温,重点越来越多地转向多步任务执行、外部工具协作和环境交互
最后一句是我的总结,不是某一篇论文单独给出的结论。
如果只看过去几年的变化,我觉得完全可以把它概括成:
- 早期重点是“更强的语言建模”
- 后来重点变成“更强的对齐和推理”
- 再往后则越来越走向“更强的工具使用和行动系统”
参考:
- Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku (Anthropic, 2024-10-22)
- Introducing the Model Context Protocol (Anthropic, 2024-11-25)
5. 这一节最重要的主线是什么?
如果只保留最核心的一条主线,我觉得是:
- LLM 不是突然出现的新物种,它延续了 NLP 里表示学习、序列建模和预训练的主线。
- Transformer 提供了今天主流大模型的结构核心。
- 2022 之后,后训练、偏好优化和 RL 让模型不只是“会预测文本”,而开始更强调“如何表现”。
- tool use 和 agent 的爆发,则让模型从“语言系统”逐渐走向“行动系统”。
所以如果后面再看 MiniMind 这样的项目,我会更倾向于把它放在这样一条连续历史里理解:
它不是凭空在讲一个模型,而是在今天这整条技术演化链上,选了一个足够小、足够清晰、足够能动手的切入点。
Tokenizer: 文本如何变成 token id?
这一节准备先回答下面几个问题:
- 字符串是如何被输入到 LLM 中的?
- token 到底是什么?它和“字”或“词”是什么关系?
- 为什么今天的大模型通常不直接按 word level 处理,而更常见是 subword level?
Q1: 字符串是如何被输入到 LLM 中的?
这是这一节最核心的问题。
模型本身并不能直接理解字符串。
从计算的角度看,神经网络最终能处理的是:
- 数值
- 向量
- 张量
而原始文本首先只是字符序列。
所以在把文本送入模型之前,必须先把它变成可以计算的离散符号,再进一步变成数值表示和连续向量。
如果把这条链路写完整,可以先记成:
字符串 -> tokenizer -> token -> token id -> embedding -> 模型主体
这里面其实包含了几层不同的对象:
- 原始字符串
- tokenizer 切分后的 token
- token 在词表中的编号,也就是 token id
- token id 经过 embedding 层后得到的向量
这几层非常容易混在一起,所以最好拆开看。
第一步: 字符串先被切成 token
tokenizer 的第一件事,是把原始字符串切成模型使用的离散单位,也就是 token。
例如,一段文本不会直接进入 Transformer,而是先被 tokenizer 拆成一串 token。
这些 token 不一定等于“一个字”,也不一定等于“一个完整单词”,它们只是 tokenizer 定义出来的基本处理单位。
第二步: token 再映射成 token id
模型内部不会直接处理 token 字符串,而会处理它们在词表中的编号。
这里就会引出一个很重要的概念:词表,也就是 vocab。
词表可以理解成:
- tokenizer 允许使用的那一套离散符号集合
- 以及这些符号到整数 id 的映射关系
也就是说,词表本质上是在维护:
token <-> token id
例如,一个非常简化的词表可以写成:
"我" -> 0
"喜欢" -> 1
"学习" -> 2
"AI" -> 3
"<unk>" -> 4
这里:
- 左边是 token
- 右边是 token 对应的整数 id
所以 tokenizer 输出的通常不是 embedding,而是一串 token id。
第三步: token id 再通过 embedding 层变成向量
到了这一步,离散的 token id 才会进入 embedding 层,被映射成连续向量。
如果词表大小记作 $V$,embedding 维度记作 $d$,那么 embedding 矩阵通常可以写成:
$$ E \in \mathbb{R}^{V \times d} $$
其中:
- $V$ 表示词表大小
- $d$ 表示 embedding 维度
这个式子的直觉非常重要。它表示:
- 词表里一共有 $V$ 个 token
- 每个 token 都对应 embedding 矩阵中的一行向量
所以从实现角度看,一个 token id 进入 embedding 层,本质上就是在 embedding 矩阵中“查一行”。
例如,如果一个 token 的 id 是 17,那么 embedding 层返回的就是 embedding 矩阵第 17 行对应的向量。
vocab 和 embedding 的关系到底是什么?
这部分非常值得单独说清楚,因为很多时候最容易混淆的就是这里。
可以简单概括成:
- vocab 决定“有哪些 token,以及它们分别编号是多少”
- embedding 决定“这些 token 被表示成什么向量”
也就是说:
- vocab 是离散符号空间
- embedding 是连续表示空间
两者一一对应,但不是一回事。
更进一步说:
- tokenizer 负责把字符串变成 token
- vocab 负责把 token 变成 token id
- embedding 层负责把 token id 变成向量
所以 tokenizer 的工作并不是“直接产生语义向量”,而是先把文本送进模型可以处理的离散接口中。
为什么 embedding 层本身也很重要?
虽然 embedding 层看起来像“查表”,但它其实已经是模型参数的一部分。
因为 embedding 矩阵中的每一行向量,都会在训练过程中被更新。
也就是说,模型不仅在学习“怎么组合 token”,也在学习:
- 哪些 token 的表示更接近
- 哪些 token 在语义或统计关系上更相似
所以如果用一句话总结这个核心问题,我觉得可以写成:
字符串先经过 tokenizer 被切成 token,再通过词表映射成 token id,最后经过 embedding 层变成模型真正处理的连续向量。
一个最小例子
如果只看抽象定义,token -> token id -> embedding 这条链很容易停留在概念层面。
所以不妨先看一个非常简化的例子。
假设原始输入字符串是:
我喜欢AI
现在假设某个 tokenizer 把它切成了下面三个 token:
["我", "喜欢", "AI"]
再假设它对应的词表是:
"我" -> 0
"喜欢" -> 1
"AI" -> 2
"<unk>" -> 3
那么这一步之后,字符串就会被表示成 token id 序列:
[0, 1, 2]
接下来,假设 embedding 维度是 4,那么 embedding 矩阵可以写成:
$$ E \in \mathbb{R}^{4 \times 4} $$
其中:
- 第一个 $4$ 表示词表大小
- 第二个 $4$ 表示 embedding 维度
为了方便说明,假设这个 embedding 矩阵的每一行分别是:
$$ E = \begin{bmatrix} 0.2 & -0.1 & 0.5 & 0.7 \ 0.9 & 0.3 & -0.4 & 0.1 \ -0.2 & 0.8 & 0.6 & -0.5 \ 0.0 & 0.0 & 0.0 & 0.0 \end{bmatrix} $$
那么:
- token id
0对应"我",取出第 0 行 - token id
1对应"喜欢",取出第 1 行 - token id
2对应"AI",取出第 2 行
于是输入序列 [0, 1, 2] 进入 embedding 层之后,就会变成下面三个向量:
$$ \begin{aligned} e_0 &= [0.2, -0.1, 0.5, 0.7] \ e_1 &= [0.9, 0.3, -0.4, 0.1] \ e_2 &= [-0.2, 0.8, 0.6, -0.5] \end{aligned} $$
到了这一步,模型真正看到的就不再是字符串 "我喜欢AI",也不再是离散编号 [0, 1, 2],而是这些连续向量组成的矩阵。
如果把它写成更紧凑的形式,就是:
$$ X \in \mathbb{R}^{3 \times 4} $$
其中:
- $3$ 表示序列长度,也就是 token 个数
- $4$ 表示 embedding 维度
这个例子虽然非常简化,但它已经把最关键的几层关系串起来了:
- 原始字符串
- token 序列
- token id 序列
- embedding 向量序列
后面进入 Transformer 之前,模型真正处理的就是这些向量,而不是原始文本本身。
Q2: token 到底是什么?
token 可以先粗略理解成:
模型在文本处理中使用的基本离散单位。
但这个单位不一定等于“一个字”,也不一定等于“一个完整单词”。
例如在不同 tokenizer 里,一个 token 可能是:
- 一个汉字
- 一个英文单词
- 一个单词的一部分
- 一个标点
- 一个空格相关的片段
所以更准确地说,token 是 tokenizer 根据某种规则切分出来的文本片段。
这也是为什么“token 数”和“字数”或“单词数”通常并不相等。
Q3: 为什么今天通常是 subword,而不是直接按词切分?
如果完全按单词切分,看起来很自然,但会遇到很多问题:
- 词表会非常大
- 生僻词、新词、拼写变化很难处理
- 多语言场景下词表管理会非常麻烦
所以现在更常见的做法,是让 tokenizer 处理到 subword 级别,也就是“比单词更小,但又不是纯字符”的单位。
这样做的好处通常包括:
- 词表规模更可控
- 未登录词更容易被拆解处理
- 可以在表达能力和词表大小之间做折中
例如一个较长的英文单词,可能会被拆成多个更常见的片段;而中文里,很多 tokenizer 的行为又会更接近字级别,但不一定严格等于“每个汉字一个 token”。
所以从实际效果上看,subword tokenizer 更像是一种工程上非常有效的折中方案。
Q4: 这一节之后最重要的收获是什么?
如果只保留最关键的几件事,我觉得是:
- 字符串进入 LLM 之前,要先经过
token -> token id -> embedding这条链路。 - token 不等于“字”或“词”,它是 tokenizer 定义出来的离散单位。
- vocab 是 token 到整数 id 的映射,它决定了系统内部的离散符号空间。
- embedding 层负责把 token id 变成连续向量,它和 vocab 一一对应,但和 tokenizer 不是同一个层次的东西。
- 今天的大模型通常更常用 subword tokenizer,因为它在词表大小和表达能力之间更平衡。
下一节再继续回到模型结构本身,讨论一个预训练模型通常由哪些部分组成。
初步理解 Attention 机制
这一节准备集中回答下面这些问题:
- Attention 的直觉到底是什么?
- Q、K、V 分别在表示什么?
- Self-Attention 里的 self 是什么意思?
- Attention 的矩阵形式到底是怎么写出来的?
- Attention Mask 在做什么?为什么 GPT 和 BERT 的处理不一样?
- Attention 里有哪些训练和实现细节?为什么它的复杂度又这么值得关注?(计算复杂度和数值稳定性)
- Multi-Head Attention 为什么不是简单重复,而是真的有意义?
Q1: Attention 的直觉是什么?数学期望
\[ \mathrm{Attention}(q, X) = \sum_{i=1}^{n}\alpha_i x_i,\quad \alpha_i = \frac{\exp(s(q, x_i))}{\sum_{j=1}^{n}\exp(s(q, x_j))} \]
其中:
- \( X = [x_1, x_2, \dots, x_n] \) 表示一个序列里的向量表示;
- \( x_i \) 表示序列中第 \( i \) 个位置对应的向量;
- \( q \) 表示当前位置拿来和整个序列做匹配的查询向量;
- \( s(q, x_i) \) 表示相似度分数,最常见的情况就是点积;
- \( \alpha_i \) 表示归一化之后的权重。
如果把 \( \alpha_i \) 看成一个概率,那么 attention 的输出也可以写成:
\[ \mathrm{Attention}(q, X) = \mathbb{E}_{ X \sim \alpha | q}[\mathbf{X}] \]
也就是说,attention 最后得到的其实是一个在权重分布下的加权平均,也可以理解成一个condition on q 的条件“期望”。
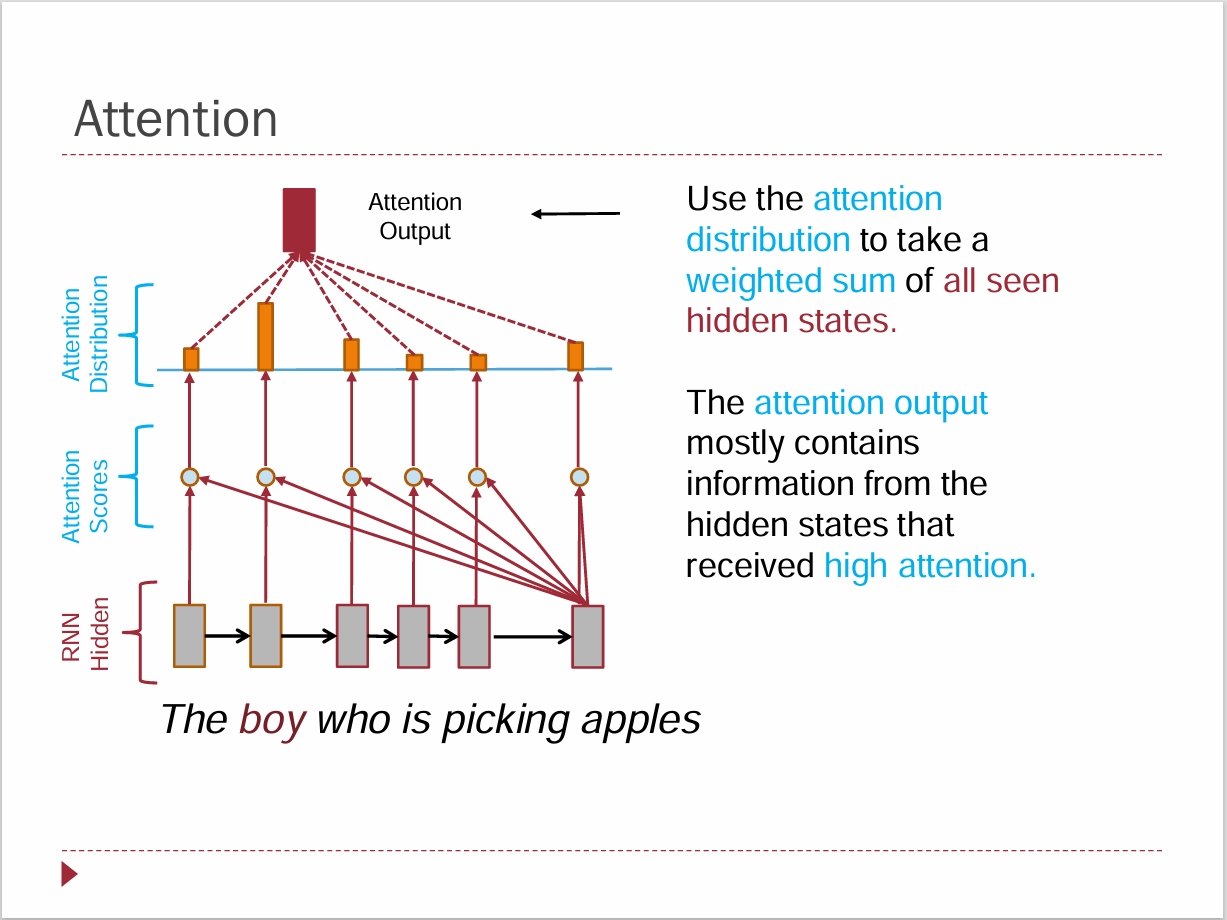
图示来源:Shanghaitech CS 274A, Natural Language Processing, Kewei Tu.
如果从刚才我们前一节提到的 NLP 发展脉络来看,attention 的核心想法其实非常直接,也非常自然。毕竟Self-Attention最初于2014年就被提出时要解决的问题本身也很明确。
放到当时的背景里,attention 是在 sequence to sequence 的问题下提出来的。当时主干模型还是 RNN。简单来说,当时模型面对的是这样一个问题:
- 输入是一个 embedding sequence;
- 输出通常还是一个 embedding sequence;
- 每个词先会被表示成 embedding;
- 但我现在希望得到的,不只是当前位置自己的 embedding,而是“当前位置和整个序列之间关系”之后形成的一个新表示。
也就是说,attention 最初要解决的问题可以理解成:
我当前这个位置的表示,和整个句子里的所有位置到底是什么关系?我希望得到的这个新表示,能够反映“当前这个词和整个句子之间的关系”。
所以它本质上做了两件事。
第一部分是强调“相关性”。
我想知道,我当前这个词的表示,和序列里其他位置的表示,哪个更相关。最自然的数学操作就是内积,也就是点积。因为点积本来就是一个很常见的相似性度量。将向量的相关性转化为一个标量.
第二部分是把这些相关性分数变成真正可用的权重。
因为最后 attention 还是要输出一个新的向量表示,所以我需要把“相关性分数”变成“权重”,然后对整个序列的信息做加权求和。这里最自然的做法就是 softmax。softmax 会把这些分数归一化成一组非负、和为 1 的权重。这样一来,这组权重就既可以理解成概率,也方便后面做加权平均。
所以从这个角度看,attention 可以很自然地被类比成一个数学期望。
我先根据相关性构造出一个分布,再在这个分布下,对整个序列里的表示做加权平均。这个理解我自己现在会觉得特别顺,因为它既符合直觉,也符合数学表达。
所以这一块如果只保留最核心的一句话,我会更倾向于这么说:
attention 的本质,就是先计算“当前位置应该关注谁”,再把整个序列的信息按这个关注分布做加权平均,得到当前位置新的表示。
Q2: Q、K、V 分别表示什么?
从这个角度理解 attention 之后,QKV 其实就会比一开始好理解很多。
我之前看很多材料的时候,Q、K、V 这三个字母会越看越晕。后来我慢慢感觉,问题不在于这三个符号本身有多难,而在于如果前面没有先把 attention 理解成“相关性 + 概率分布 + 期望”。
如果沿着刚才的思路往下看,Q、K、V 其实只是把 attention 里不同功能拆开命名了。
严格说,完全可以直接拿原始的 embedding 去做这件事:我用当前位置的向量和整个序列里的向量做相似性计算,再对整个序列做加权平均。这在概念上是完全说得通的。
但是在深度学习里,通常不会直接这样做,而是会再经过一层可学习的线性变换,把不同功能交给模型自己去学。也就是说:
- 哪个表示更适合拿来做匹配;
- 哪个表示更适合拿来被聚合;
- 哪个表示更适合描述“我现在想找什么”。
这些都交给模型自己学。
所以就有了这三个记号:
- Query,记作 \( Q \)
- Key,记作 \( K \)
- Value,记作 \( V \)
如果按我现在的理解方式来讲:
- Query 可以理解成“当前位置拿什么去问”;
- Key 可以理解成“序列中每个位置拿什么去响应这个问题”;
- Value 则是“这个位置真正携带、最后要被加权聚合的内容”。
换句话说,Q 和 K 的作用主要是构造相关性,或者说构造匹配分数。V 的作用则是:在这个分数对应的概率分布下面,提供最后被求期望、被加权平均的对象。
所以从这个角度看,QKV 不是三个孤立的神秘符号,而是 attention 里三个不同的功能角色。
如果再贴着“期望”这个理解去说,会更顺一些:
- Q、K 负责定义一个分布;
- V 负责定义这个分布下要聚合的随机变量取值。
这样一来,为什么最后是“先算 QK 的相关性,再去加权 V”,就会自然很多。
当然,在教材或者资料里,最常见的直觉表达还是:
- Query:当前位置“想找什么”
- Key:每个位置“能提供什么索引”
- Value:每个位置“真正携带的内容”
这个说法本身没有问题,而且很常用。只是对我自己来说,如果把它和“相关性 + 概率分布 + 数学期望”这条线连起来,QKV 会清楚很多。
这也解释了为什么像 RoPE 这样的位置信息,通常作用在 \( Q/K \) 上,而不是直接作用在 \( V \) 上。因为位置关系首先影响的是“怎么匹配”,而不是“内容本身是什么”。
Q3: Self-Attention 里的 self 是什么意思?
Self-Attention 里的 self,意思是:
- Query、Key、Value 都来自同一个输入序列。
也就是说,整个 attention 是作用在“这个序列对自己”的关系上的。
换句话说,你输入的是一个序列,最后输出的也还是一个序列。只不过输出序列里每个位置对应的表示,已经不再只是它自己原来的 embedding,而是“当前位置和整个序列发生关系之后”的一个新表示。
这个理解我觉得很重要,因为它其实就是后面 score、attention map 这些东西的基础。
如果把这个过程写成最简单的 tensor shape 伪代码,可以先这么看:
seq_in : [batch_size, seq_len, embedding_dim]
seq_out : [batch_size, seq_len, embedding_dim]
seq_out = attention(seq_in)
这里最关键的是:
- 输入是一个序列;
- 输出还是一个序列;
- 但每个位置的输出,都已经带上了它和整个序列之间的关系。
如果把输入序列记成:
\[ X \in \mathbb{R}^{n \times d} \]
其中:
- \( n \) 表示序列长度;
- \( d \) 表示 hidden dimension。
那么通常会先通过三个线性变换得到:
\[ Q = XW_Q,\quad K = XW_K,\quad V = XW_V \]
其中:
- \( W_Q, W_K, W_V \) 是可学习参数矩阵。
因为它们都来自同一个输入 \( X \),所以这叫 self-attention。
所以 self-attention 这一层可以理解成:把一个序列,变成另一个同长度的序列;但新序列中每个位置的表示,都已经融合了它对整个序列的关注关系。
Q4: Attention 的矩阵形式到底是怎么写出来的?
前面如果是按“一个位置去关注整个序列”来理解的,那么到矩阵形式时,本质上只是把这个过程一次性并行算完。
先把输入序列记作:
\[ X \in \mathbb{R}^{n \times d} \]
其中:
- \( n \) 表示 sequence length;
- \( d \) 表示 hidden size。
这里有一个细节很值得先说清楚:在这套写法里,\( X \) 的feature 维度是行向量.这个记号和很多线性代数教材里“列向量是feature”的写法不完全一样,但在深度学习实现里这样写会更自然,因为 tensor 的 shape 通常就是 [..., seq_len, hidden_dim]。相当于在这个矩阵前面拼接batch维度,所以 feature 维度在后面。如果按照列向量的写法,反而会让后面矩阵乘法的 shape 对不上.
数学表达是 \( x_i \in \mathbb{R}^d \) 列向量表示feature. feature做列向量的feature矩阵为:
$$ X = [x_1, x_2, \dots, x_n] \in \mathbb{R}^{d \times n} $$ 如果按照行向量的写法,\( x_i \in \mathbb{R}^d \) 作为行向量表示feature. $$ X = (x_1^\top, x_2^\top, \dots, x_n^\top)^\top \in \mathbb{R}^{n \times d} $$
Q,K,V是X经过三个线性投影变换得到的:
\[ Q = XW_Q,\quad K = XW_K,\quad V = XW_V \]
其中:
- \( W_Q \in \mathbb{R}^{d \times d_k} \)
- \( W_K \in \mathbb{R}^{d \times d_k} \)
- \( W_V \in \mathbb{R}^{d \times d_v} \)
于是得到:
- \( Q \in \mathbb{R}^{n \times d_k} \)
- \( K \in \mathbb{R}^{n \times d_k} \)
- \( V \in \mathbb{R}^{n \times d_v} \)
接下来 attention 最经典的矩阵形式就是:
\[ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V \]
注 : Attention 写成对每个\(q^\top \in \mathbb{R}^{1 \times d_k} \)的形式 \[ \mathrm{Attention}(q, K, V) = \mathrm{softmax}\left(\frac{q^\top K^\top}{\sqrt{d_k}}\right)V \]
这个公式可以按顺序拆开看:
- \( QK^\top \):计算所有 query 和所有 key 的两两相似度,得到一个 \( n \times n \) 的分数矩阵;
- 除以 \( \sqrt{d_k} \):做缩放;
softmax:把每一行变成一个权重分布(这个矩阵的每一行是一个分布,如果是q, softmax 后 shape 是 \(1 \times n\),依然是最后一个维度/行维度表示);- 再乘 \( V \):按这个权重分布对整个序列的 value 做加权求和。(输出的shape是 \( n \times d_v \),n 表示序列,d_v 表示每个位置新的embedding维度)
如果把 shape 一并写出来,会更直观:
\[ QK^\top \in \mathbb{R}^{n \times n} \]
其中第 \( t \) 行第 \( i \) 列,表示“第 \( t \) 个位置对第 \( i \) 个位置”的关注分数。
然后:
\[ A = \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right),\quad A \in \mathbb{R}^{n \times n} \]
最后:
\[ Y = AV,\quad Y \in \mathbb{R}^{n \times d_v} \]
所以这一整套东西本质上就是:从一个 sequence 出发,先变成 Q/K/V,再变成 attention score matrix,最后再变成新的 sequence 表示。
在实际代码里,Q/K/V 的 shape 往往会写成:
[bsz, num_heads, seq_len, head_dim]
这也是很多主流实现采用的形式。用这个 shape 时,torch.matmul() 会在最后两个维度上做矩阵乘法,而前面的 batch 和 head 维度自动对齐。
Q5: Attention Mask 在做什么?为什么 GPT 和 BERT 的处理不一样?
前面那个公式其实还少写了一个在实现里非常关键的东西,就是 attention mask。
因为 attention 默认是“当前位置可以看整个序列”,但这件事在不同模型里并不总是成立。
如果是 BERT 这种双向编码器,它本来就允许一个位置同时看左边和右边,所以通常不需要 causal mask。它做的是“整个句子一起编码”,目标不是逐 token 地自回归生成。
但如果是 GPT 这种自回归语言模型,情况就不一样了。GPT 的训练目标是根据前文预测下一个 token,所以当前位置不能提前看到未来的位置,否则就相当于剧透了答案。
这时就需要一个下三角 mask。也就是说:
- 第 1 个位置只能看第 1 个位置;
- 第 2 个位置只能看前 2 个位置;
- 第 \( t \) 个位置只能看前 \( t \) 个位置。
如果把它写进公式里,通常会变成:
\[ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^\top + M}{\sqrt{d_k}}\right)V \]
其中:
- \( M \in \mathbb{R}^{n \times n} \) 表示 mask 矩阵;
- 允许关注的位置加上 0;
- 不允许关注的位置加上一个非常小的数,比如负无穷附近的数。
具体来说
- 下三角(含对角线)= 0 → 允许看到过去和当前 token
- 上三角 = -inf → 不允许看到未来 token
这样一来,softmax 之后,被 mask 掉的位置权重就会接近 0。
所以 attention mask 本质上并不是在“改变 attention 的定义”,而是在约束“哪些位置允许参与注意力分布”。
Q6: Attention 里有哪些训练和实现细节?为什么它的复杂度又这么值得关注?
到了这一步,就会进入一些很典型的技术细节。
第一个就是为什么要有 scaled attention,也就是公式里那个 \( \sqrt{d_k} \)。
原因其实很直接。如果 \( d_k \) 很大,那么点积 \( QK^\top \) 的数值也会变得比较大。这样一来,softmax 很容易进入特别尖锐的区域,导致梯度变小,训练不稳定。
所以要除以 \( \sqrt{d_k} \) 来做缩放。这个缩放本质上是在控制数值范围,让 softmax 前面的分数不要过大,从而让训练更稳定。
第二个就是 attention 的计算复杂度。
Attention 最核心的计算量来自 \( QK^\top \) 这一步。
假设:
- \( n \) 表示序列长度;
- \( d \) 表示每个 head 的特征维度。
那么每个 query 都要和全部 \( n \) 个 key 做一次长度为 \( d \) 的点积,所以总复杂度可以粗略写成:
\[ O(n^2 d) \]
这里最关键的不是公式本身,而是这个 \( n^2 \)。
也就是说,attention 的代价会随着序列长度平方级增长。序列一长,算力和显存压力都会上来。这也是为什么大家会在 attention 上花很多力气去做优化,因为它几乎就是整个 Transformer 里最“烧资源”的部分之一。
所以这一节如果只从直觉层面说,可以先记住:
- attention 非常强;
- 但 attention 很贵;
- 序列越长,它越贵;
- 后面很多工程优化,本质上都是围绕这里展开的。
Q7: Multi-Head Attention 为什么不是简单重复,而是真的有意义?
Multi-Head Attention 的基本想法是:
不要只在一个表示子空间里做一次 attention,而是在多个子空间里并行地做 attention。
如果把 hidden size 记作 \( d \),head 数记作 \( h \),并且设每个 head 的维度是 \( d_h = d / h \),那么第 \( j \) 个 head 可以写成:
\[ \mathrm{head}_j = \mathrm{Attention}(Q_j, K_j, V_j) \]
其中:
\[ Q_j = XW_Q^{(j)},\quad K_j = XW_K^{(j)},\quad V_j = XW_V^{(j)} \]
如果按单个 head 来看,这几组参数的 shape 通常是:
- \( W_Q^{(j)} \in \mathbb{R}^{d \times d_h} \)
- \( W_K^{(j)} \in \mathbb{R}^{d \times d_h} \)
- \( W_V^{(j)} \in \mathbb{R}^{d \times d_h} \)
也就是说,每个 head 都是把输入的 hidden size \( d \),投影到一个更小的子空间 \( d_h \) 里,再在这个子空间里做 attention。
最后所有 head 的结果拼接起来,再乘一个输出投影矩阵:
\[ \mathrm{MultiHead}(X) = \mathrm{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h)W_O \]
其中:
- \(head_j \in \mathbb{R}^{n \times d_h} \)
- \( \mathrm{Concat}(\mathrm{head}_1, \dots, \mathrm{head}_h) \in \mathbb{R}^{n \times (hd_h)} = \mathbb{R}^{n \times d} \)
- \( W_O \in \mathbb{R}^{d \times d} \)
所以从数学结构上看,multi-head attention 可以理解成:
- 先用多组 \( W_Q^{(j)}, W_K^{(j)}, W_V^{(j)} \) 把输入投影到多个不同子空间;
- 每个子空间各自做一次 attention;
- 再把这些结果拼接起来;
- 最后再用 \( W_O \) 投影回原来的 hidden size。
这里直观上可以理解成:
- 不同 head 关注的关系模式可能不一样;
- 有的 head 更关注局部邻近位置;
- 有的 head 更关注长距离依赖;
- 有的 head 更偏语法结构,有的更偏语义关联。
而且对我来说,multi-head 还有一个很重要的意义是:如果只有单头 attention,那么整个映射结构会显得比较单一。引入多个 head 之后,相当于先把输入投影到多个不同的子空间里,再分别做 attention,最后再融合回来。这样模型就有机会学习到更丰富的表示变化。
严格说,nonlinearity 主要还是来自 FFN、softmax 这些部分,但 multi-head 确实让 attention 这一层本身的表示能力更强了,不再只是“在一个单一空间里做一次线性风格很强的变换”。
如果从实际实现的角度看,代码里通常不会真的写成“for 循环一个 head 一个 head 地分别乘一次矩阵”。更常见的做法是,把多个 head 的投影参数先拼成一个大矩阵,一次性把所有 head 的 Q、K、V 都算出来。
比如在很多实现里,会直接用一个大的线性层得到:
\[ Q \in \mathbb{R}^{n \times (hd_h)},\quad K \in \mathbb{R}^{n \times (hd_h)},\quad V \in \mathbb{R}^{n \times (hd_h)} \]
然后再通过 reshape / view,把它们整理成按 head 拆开的 tensor。常见的写法就是:
[bsz, num_heads, seq_len, head_dim]
所以如果 multi‑head attention 的所有 head 的维度加起来等于原始的 d_model,那么 MHA 和单头 Attention 的参数量完全一样。
这样做的好处是,多个 head 的计算可以直接打包成一个 tensor 运算,让底层库一次性并行完成,而不是在 Python 层面做很多小矩阵乘法。也就是说,从数学定义上看,multi-head 像是很多个 head 分别算;但从工程实现上看,它通常会被组织成一次大的张量计算来加速。
最后再回到一个很自然的问题:为什么通常是拼接,而不是相加?
我现在更倾向于这样理解:
- 拼接能保留每个 head 独立学到的信息;
- 相加会过早把不同 head 的信息混在一起;
- 拼接之后再用一个线性层统一融合,表达能力更强,也更灵活。
这一节之后最重要的收获是什么?
如果只保留这一节最重要的几件事,我觉得是:
- Attention 的核心是“动态地从上下文中检索和聚合信息”。
- Q/K/V 不是孤立的三个字母,而是“匹配”和“取内容”这两个步骤的拆分。
- Attention 可以理解成一个数学期望:先构造分布,再做加权平均。
- Attention 的矩阵形式,本质上是在并行地计算“整个序列里每个位置对所有位置的关注关系”。
- GPT 这类自回归模型必须用 mask,避免当前位置提前看到未来信息。
- Attention 的 \( O(n^2 d) \) 复杂度解释了为什么它值得被重点优化。
- Multi-Head Attention 的意义不只是重复算很多次,而是让模型在多个子空间里学习不同的关系模式。
下一节回到 MiniMind 项目本身,看看这些概念在实践中是怎么真正组织起来的。
模型总览: 一个预训练模型由哪些部分组成?
这一节的目标,是先把一个基础的 LLM 模型到底是什么这件事整理清楚。
先不进入训练、loss、优化器这些内容,而是只回答一个更基础的问题:如果只看模型结构,一个预训练语言模型到底由哪些部分组成?这些部分分别在做什么?常见的设计取舍又是什么?
这一节准备围绕下面这些问题来组织:
- 一个预训练模型大体可以划分为哪些部分?
- Embedding 层和位置编码层分别在做什么?
- 激活函数、Norm、Dropout 这类“看起来像细节”的设置,为什么其实很重要?
- FFN 和 Attention 这两个核心模块分别在做什么?
- 后来的改进,比如 RoPE、FlashAttention、GQA、KV Cache,又分别是在解决什么问题?
Q1: 一个预训练模型大体可以划分为哪些部分?
如果先把训练流程、数据处理、优化器这些东西都放到一边,只看“模型定义”本身,那么一个典型的 GPT 类预训练模型,大致可以分成下面几部分:
- 输入嵌入层(Embedding)
- 位置信息注入(Position Encoding / Positional Representation)
- 多层 Transformer Block
- 输出投影层(LM Head)
如果把这条链路写成最简化的形式,可以先记成:
token id -> embedding -> 多层 transformer block -> logits
进一步展开,可以写成:
token id [n,]
-> token embedding [n , dim]
-> 注入位置信息 [n, dim]
-> 重复多层 [attention + norm + ffn] [n,dim]
-> 最终 hidden state [n, dim]
-> 词表投影 [n, V]
-> logits [n, V]
这个流程图本身是对的,但如果只停在这一步,还是会有一个问题:
我们知道模型“经过了哪些部分”,却还不知道每一层到底接收什么、输出什么、以及发生了什么变换。
所以接下来最好把这个流程进一步写成一个更正式的“整体定义”。
MiniMind 里这条主链路的骨架也写得很直接。模型主干
MiniMind_Dense负责Embedding、多层MiniMindBlock和最后的Norm;MiniMindForCausalLM再在外面包一层lm_head,把 hidden states 投影回词表空间。对应实现来自 model_minimind.py 和 model_minimind.py。
MiniMind: 模型主干与 LM head
class MiniMind_Dense(torch.nn.Module):
"""
Dense模型的定义
"""
def __init__(self, config: MiniMindConfig):
super().__init__()
self.config = config
self.vocab_size, self.num_hidden_layers = (
config.vocab_size,
config.num_hidden_layers,
)
# Embedding
self.embed_tokens = nn.Embedding(
config.vocab_size, config.hidden_size
) # [vocab_size , embedding_size]
# Dropout and norm
self.dropout = nn.Dropout(config.dropout)
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# Attention Layers
self.layers = nn.ModuleList(
[MiniMindBlock(l, config) for l in range(self.num_hidden_layers)]
)
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
config_class = MiniMindConfig
def __init__(self, config: MiniMindConfig = None):
self.config = config or MiniMindConfig()
super().__init__(self.config)
self.model = MiniMind_Dense(self.config)
self.lm_head = nn.Linear(self.config.hidden_size, self.config.vocab_size, bias=False)
self.model.embed_tokens.weight = self.lm_head.weight
self.OUT = CausalLMOutputWithPast()
整体定义
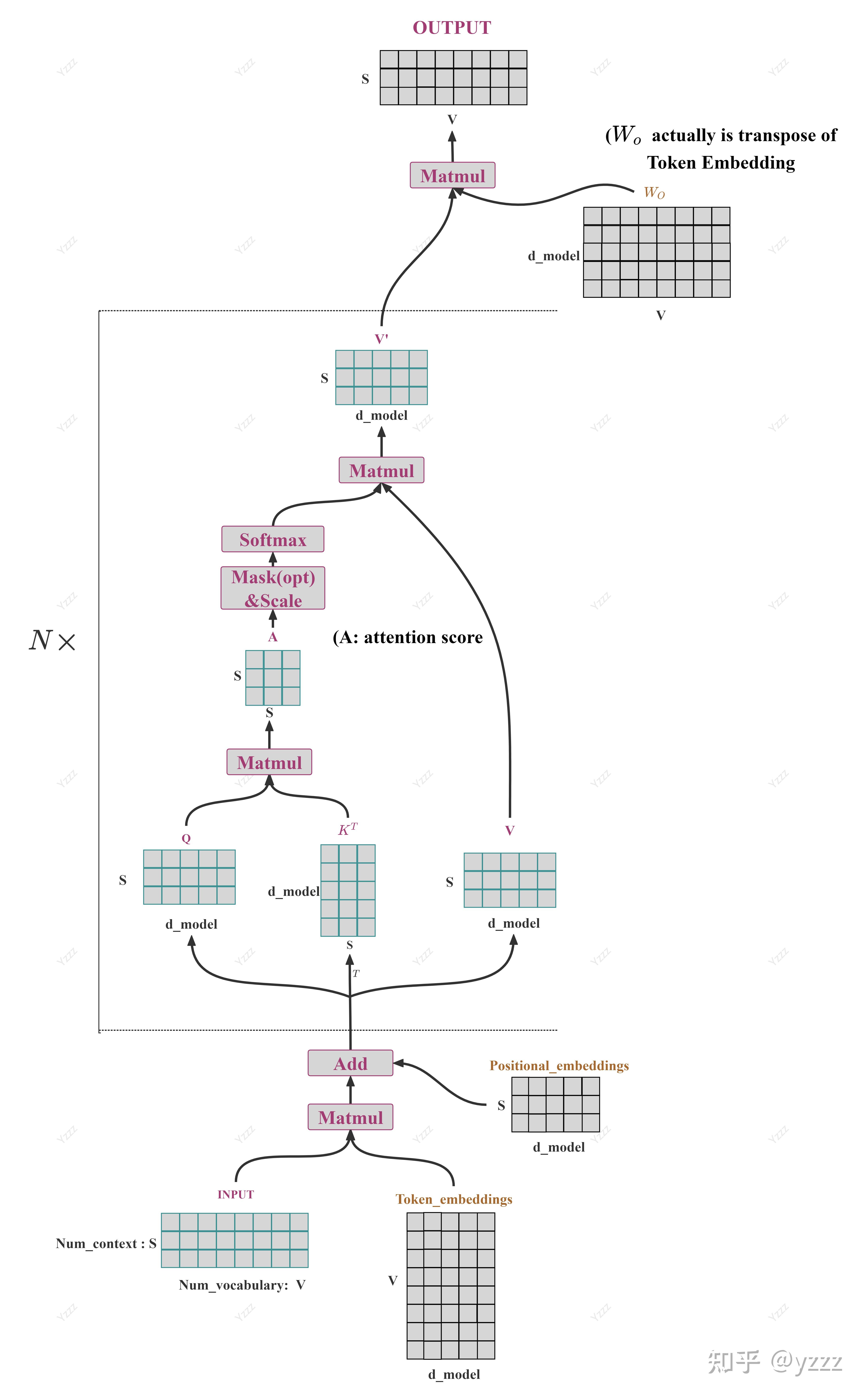
如果只从函数角度看,一个不带 LM head 的 Transformer 模型可以理解成下面这个映射:
$$ f_\theta(t_1,t_2\dots t_n) \in \mathbb{R}^{n\times d} $$
其中:
- \( \theta \) 表示整个模型的参数
- \( d \) 表示 hidden size
- \( n \) 表示输入序列长度
- \( V \) 表示词表大小
这个式子的意思是:
-
输入是一串长度为 \( n \) 的 token id
-
每个 token id 的取值范围在 \( 0 \) 到 \( V-1 \) 之间
-
输出是一个形状为 \( [n, d] \) 的矩阵,用 hidden state 表示整个序列在各个位置上的编码结果
-
最后再经过具体的 LM head,比如使用一个 \( [d, V] \) 的投影矩阵,把它变成形状为 \( [n, V] \) 的 logits 张量,再经过 softmax 变成概率分布。这就是最基本的语言模型
-
不同任务下,最后接的 head 也可能不一样
模型的整体输入是什么?
$$ t_1, t_2, \dots, t_n $$
表示输入 token 序列,其中:
- \( t_i \) 表示第 \( i \) 个 token 的 id
- \( n \) 表示序列长度
在实际代码里,如果考虑 batch 维,通常更常见的 shape 是:
$$ T \in \mathbb{N}^{B \times n} $$
其中:
- \( B \) 表示 batch size
- \( n \) 表示序列长度
也就是说,输入本质上是一批 token id 序列,而不是原始字符串,也不是 embedding 向量。
每一层的输入输出 shape 和发生的变换
1. token id -> token embedding
Embedding 层接收离散 token id:
$$ T \in \mathbb{N}^{B \times n} $$
输出连续表示:
$$ X^{(0)} \in \mathbb{R}^{B \times n \times d} $$
其中:
- \( d \) 表示 hidden size,也就是 embedding 维度
这一层发生的变换,本质上是:
- 对每个 token id 查 embedding 矩阵中的一行
- 把离散符号变成连续向量
到这一步之后,输入已经从 token id 变成了连续向量。后面的大部分计算,基本都不会再改动它的 shape ([n,d]),而是在同一个表示空间里不断做变换,让这些向量逐渐混入上下文信息。从这个角度看,Transformer 这个名字其实很直观,它后面一直在做的就是“变换表示”这件事。
MiniMind 里这一层的实现也很直接,就是一个
nn.Embedding,然后在forward里把input_ids查表成[batch_size, seq_len, hidden_size]。对应实现来自 model_minimind.py 和 model_minimind.py。
MiniMind: Embedding 的定义与前向输入输出
# Embedding
self.embed_tokens = nn.Embedding(
config.vocab_size, config.hidden_size
) # [vocab_size , embedding_size]
# Embedding 要过Dropout!
# [batch_size , seq_len] -> [batch_size , seq_len , hidden_size] -> [batch_size , seq_len , hidden_size]
hidden_states = self.dropout(self.embed_tokens(input_ids))
2. token embedding -> 注入位置信息
如果使用最基本的位置表示思路,那么这一层的输入和输出 shape 都仍然是:
$$ X^{(0)} \in \mathbb{R}^{B \times n \times d} $$
和
$$ \tilde{X}^{(0)} \in \mathbb{R}^{B \times n \times d} $$
这一层发生的事情不是改 shape,而是把位置信息注入表示里。
Position embedding 的重要性在于,模型不只需要知道“有哪些 token”,还需要知道“它们出现在哪些位置”。
如果用 RoPE 这类方案,那么位置信息不一定直接加在输入 embedding 上,而可能延后到 attention 的 Q/K 计算阶段再进入。
MiniMind 没有使用固定Position Embedding,而是使用了RoPE,先预计算 RoPE 所需的
freqs_cos和freqs_sin,再在forward里按当前位置切出来传给各层 attention。RoPE请参考RoPE小节的代码实现, 对应实现来自 model_minimind.py 和 model_minimind.py。
MiniMind: RoPE 位置向量的预计算与切片
# RoPE vector
freqs_cos, freqs_sin = precompute_freqs_cis(
dim=config.hidden_size
// config.num_attention_heads, # dim for each attention heads
end=config.max_position_embeddings,
rope_base=config.rope_theta,
rope_scaling=config.rope_scaling,
)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
# [seq_len,]
position_embeddings = (
self.freqs_cos[start_pos : start_pos + seq_length],
self.freqs_sin[start_pos : start_pos + seq_length],
)
3. 多层 Transformer Block
Transformer 层是模型的核心模块。它由许多结构相同的 Transformer block 重复堆叠起来,对序列表示一层一层地继续做变换。Transformer 的层数本身也是一个很重要的超参数,而每一层的输入输出 shape 通常都保持一致,这样这个变换过程才能持续往下传。
假设模型一共有 \( L \) 层 Transformer block,那么第 \( \ell \) 层可以写成:
$$ X^{(\ell+1)} = \mathrm{Block}^{(\ell)}\left(X^{(\ell)}\right) $$
其中:
- \( \ell = 0,1,\dots,L-1 \)
- 每一层的输入输出 shape 通常都保持不变
也就是说:
$$ X^{(\ell)} \in \mathbb{R}^{B \times n \times d} $$
这一层内部虽然会发生很多计算,比如:
- attention
- residual
- norm
- ffn
但从外部看,最重要的事情是:
- shape 基本保持不变
- 表示的语义不断被更新
- 上下文信息逐层混合进每个位置的表示里
4. 最终 hidden state -> 词表投影
经过最后一层 Transformer block 后,得到最终 hidden state:
$$ H \in \mathbb{R}^{B \times n \times d} $$
接下来就要进入语言模型最后那一层,也就是常说的 LM head。
对于最基本的语言模型来说,LM head 的作用很直接:
把每个位置的 hidden state 映射成“这个位置对整个词表的预测分数”。
如果只写单个位置的形式,可以记成:
$$ z_i = h_i W_{\text{lm}} + b $$
其中:
- \(h_i\) 表示第 \(i\) 个位置的 hidden state,这里的\(h_i \in \mathbb{R}^{1 \times d} \) 实际是一个行向量. 这是为了方便之后把batch维度加到它前面.
- \(W_{\text{lm}}\) 表示输出投影矩阵
- \(b\) 表示偏置项
- \(z_i\) 表示这个位置对应的词表分数向量,也就是 logits,即还没有经过 softmax 的原始分数(raw scores)
如果一次处理整个序列,那么经过 LM head 之后,最后一个维度就会从 hidden size 变成词表大小:
$$ Z \in \mathbb{R}^{B \times n \times V} $$
也就是说,这一层发生的事情可以理解成:
- 对每个位置的 hidden state
- 输出它对整个词表中每个 token 的原始分数
这些原始分数就是 logits表示未经过 softmax 的原始分数(raw scores).
这里其实可以顺手记住一句话:
- Transformer block 负责得到“上下文化之后的表示”
- LM head 负责把这个表示重新翻译成词表上的分数
为什么这里叫 LM head?
因为这是 Language Model head,也就是语言模型任务对应的输出头。
最基本的语言模型任务是 next-token prediction。
也就是说,模型最后必须回答这样一个问题:
- 给定当前位置之前的上下文
- 下一个 token 最可能是词表中的哪一个?
所以最自然的输出方式,就是对整个词表打分。
LM head 正是在完成这一步。
为什么任务变了,head 也会跟着变?
这里也能顺手看出一个很重要的事实:
模型主体和最后的输出头,其实是两层不同的东西。
模型主体负责提取表示,而最后的 head 负责把表示变成某个具体任务需要的输出。
所以如果任务变了,最后这一层也经常会跟着变:
- 对于基础语言模型:输出是词表上的 logits,所以使用 LM head
- 对于分类任务:最后可能只需要输出几个类别分数,所以会换成分类 head
- 对于回归任务:最后可能只输出一个或几个连续值,所以也会换成别的输出层
也就是说,LM head 不是“所有模型最后一层的唯一形式”,而是“语言模型任务最基本、最自然的输出头”。
模型的整体输出是什么?
如果先不考虑 batch 维,那么模型对一个长度为 \( n \) 的输入序列,输出可以写成:
$$ Z \in \mathbb{R}^{n \times V} $$
其中:
- 第一个维度对应序列中的位置
- 第二个维度对应词表中的 token 数目
- 矩阵的每一项表示“这个位置对应这个 token 的预测分数(logit)”
如果把 batch 维也补上,更完整的写法通常是:
$$ Z \in \mathbb{R}^{B \times n \times V} $$
其中:
- 第一个维度 \( B \) 是 batch size
- 第二个维度 \( n \) 是序列长度
- 第三个维度 \( V \) 是词表大小
这个张量里的每一个 \( Z_{b,i,:} \),都表示:
- 第 \( b \) 个样本
- 第 \( i \) 个位置
- 对整个词表中每个 token 的预测分数
所以如果用一句话概括最基本的语言模型输入输出,可以写成:
- 输入:形状为 \( [B, n] \) 的 token id 序列
- 输出:形状为 \( [B, n, V] \) 的 logits 张量
而模型中间所有模块,本质上都在做一件事:
把输入 token 序列逐层变成更有上下文信息的隐藏表示,最后再投影回词表空间。
从这个角度看,模型的核心其实是在做两件事:
- 把离散 token id 变成高维连续表示
- 在多层变换中不断让上下文信息彼此交互,最后再投影回词表空间
Q2: Embedding 层在做什么?
Embedding 层的作用,是把离散 token id 映射成连续向量。
如果词表大小记作 \( V \),隐藏维度记作 \( d \),那么 token embedding 矩阵通常可以写成如下的形式。事实上,Embedding 层一般就是这个矩阵,它本身也是模型参数的一部分,会参与训练。对于比较小的模型,embedding 矩阵甚至会占参数量的大头:
$$ E \in \mathbb{R}^{V \times d} $$
其中:
- \( V \) 表示词表大小
- \( d \) 表示 hidden size,也可以理解成 embedding 维度
当一个 token id 输入 embedding 层时,本质上就是在这个矩阵里取出对应的一行。
如果输入序列长度是 \( n \),那么 embedding 层的输出可以写成:
$$ X \in \mathbb{R}^{n \times d} $$
从直觉上看:
- 词表决定“有哪些离散符号”
- embedding 决定“这些离散符号如何在连续空间里表示”
经验问题 1: embedding 维度通常设多少?
这件事通常不会单独决定,而是直接跟整体 hidden size 绑定。
在大多数 Transformer 里,token embedding 维度通常直接等于 hidden size,也就是:
$$ d_{\text{embed}} = d_{\text{model}} $$
原因也很直接:
- embedding 输出之后,后面所有 Transformer block 都在同一个维度空间里工作
- 如果 embedding 维度和 hidden size 不一致,就需要额外投影层
所以在大多数 decoder-only Transformer 里,embedding 维度通常就直接等于模型主干的 hidden size。
这里直有几组真实模型配置:
| 模型 | 参数规模 | embedding / hidden size | attention heads | 配置 |
|---|---|---|---|---|
| GPT-2 | 124M | 768 | 12 | config |
| GPT-2 Medium | 355M | 1024 | 16 | config |
| GPT-2 Large | 774M | 1280 | 20 | config |
| GPT-2 XL | 1.5B | 1600 | 25 | config |
| Llama-2-7B | 7B | 4096 | 32 | config |
| Llama-3-8B | 8B | 4096 | 32 | config |
| Qwen2.5-7B | 7B | 3584 | 28 | config |
从这些配置里可以直接看到两件事:
- embedding 维度通常就是 hidden size,本身并不会单独设成另一套数
- hidden size 的取值通常会和头数严格对齐,保证 \( d_{\text{model}} / n_{\text{heads}} \) 是一个整齐的整数
经验问题 2: hidden size 一般怎么定?
这一节里,最值得记住的不是“hidden size 有什么经验最优值”,而是它其实是一个被多种约束一起卡住的量。先看最直接的一条结构约束:
$$ d_{\text{model}} = n_{\text{heads}} \cdot d_{\text{head}} $$
其中:
- \(d_{\text{model}}\) 表示 hidden size
- \(n_{\text{heads}}\) 表示注意力头数
- \(d_{\text{head}}\) 表示每个 head 的维度
也就是说,hidden size 首先要和注意力结构对齐,而不是随便写一个数。除此之外,它还会非常直接地影响参数量。粗略看:
- attention 里的投影矩阵参数大致和 \(d_{\text{model}}^2\) 同阶
- FFN 的参数大致和 \(d_{\text{model}} \cdot d_{\text{ff}}\) 同阶
- 如果 \(d_{\text{ff}} \approx 4 d_{\text{model}}\),那么 FFN 参数通常也会近似随 \(d_{\text{model}}^2\) 增长
所以 hidden size 不是线性地影响模型大小,而往往会以接近平方的方式影响参数量、显存占用和计算量。
如果真要落到操作上,我觉得比较实用的顺序是:
-
先定模型总规模 比如是 20M、100M,还是 1B 以上。这个规模先把 hidden size 的上限大致卡住。
-
再定层数和头数 同样的总参数量,可以做成更宽更浅,也可以做成更窄更深,所以 hidden size 不能脱离层数单独看。
-
最后让 \( d_{\text{model}} \) 和 \( n_{\text{heads}} \) 对齐 也就是让它能自然整除,这样 \( d_{\text{head}} \) 会比较规整,实现也更自然。
如果只是做教学模型或者小模型,那么最实用的结论其实可以压缩成一句话:先定模型规模,再定层数和头数,最后让 hidden size 去匹配 attention 结构。
经验问题 3: 输出层为什么常常和 embedding 共享权重?
很多 GPT 类模型里,会把输入 embedding 矩阵和输出投影层权重做共享 (直接作为LM head 的投影矩阵),也就是常说的 weight tying。
如果输出层写成:
$$ z = h W_{\text{out}} + b $$
其中:
- \( h \in \mathbb{R}^{1 \times d} \) 表示某个位置的 hidden state
- \( W_{\text{out}} \in \mathbb{R}^{d \times V} \) 表示输出投影矩阵
其正好就是Embedding矩阵的转置,这个操作在数学上也可以理解成,输出的hidden state直接和embedding矩阵的行做内积,得到每个词的分数就是在衡量和此表里面每个词的相似度.也就是说embedding不但在编码时刻进行训练,同样也在输出的时候受到约束.
$$ W_{\text{out}} = E^\top $$
这样做的好处通常包括:
- 参数更省
- 输入表示空间和输出词表空间更一致
- 在实践中常常有不错的效果
所以 embedding 层虽然看起来很基础,但它其实已经和模型参数规模、输出层设计直接连在一起了。
MiniMind 这里也直接使用了
weight tying,也就是让输入 embedding 的权重和lm_head共享。对应实现来自 model_minimind.py。
MiniMind: 输入 embedding 和 LM head 共享权重
self.model = MiniMind_Dense(self.config)
self.lm_head = nn.Linear(self.config.hidden_size, self.config.vocab_size, bias=False)
self.model.embed_tokens.weight = self.lm_head.weight
Q2.1: 位置编码层在做什么?
如果只有 token embedding,而没有位置信息,那么模型虽然能知道“有哪些 token”,却不知道“它们以什么顺序出现”。
这也是为什么位置表示是必须的。
假设 token embedding 序列写成:
$$ X = [x_1, x_2, \dots, x_n] $$
其中:
- \( x_i \in \mathbb{R}^{d} \) 表示第 \( i \) 个位置的 token embedding
最早的一种思路,是直接构造位置向量:
$$ p_1, p_2, \dots, p_n $$
然后做相加:
$$ \tilde{x}_i = x_i + p_i $$
这种思路很直观:
token 内容由 \( x_i \) 提供,位置信息由 \( p_i \) 提供。
经验问题 1: 为什么今天很多模型不再用最早那种绝对位置 embedding?
这个问题其实也可以直接从真实模型配置里看出来。
| 模型 | 位置方案 | 相关配置 |
|---|---|---|
| GPT-2 | learned absolute position embedding | n_positions = 1024,config |
| Llama-3-8B | RoPE | max_position_embeddings = 8192, rope_theta = 500000.0,config |
| Qwen2.5-7B | RoPE | max_position_embeddings = 131072, rope_theta = 1000000.0,config |
从这些配置里可以很直接地看到:早期 GPT-2 这一类模型更接近“给每个位置单独学一个位置向量”;而更现代的 Llama、Qwen 这类模型,已经转向了和 attention 计算绑定得更紧的 RoPE。
绝对位置 embedding 当然也能工作,但它有几个比较明显的局限:
- 位置表示通常和最大上下文长度绑定
- 超出训练长度时泛化可能较弱
- 位置关系是“加在输入上”的,不是直接进入 attention 匹配过程
这也是为什么后来越来越多模型转向 RoPE 这类位置表示方式。
不过 RoPE 本身已经不只是“位置编码层的一个小变体”了,它和 attention 的计算过程紧密绑定,所以我把它单独拆成了一节:RoPE: 位置编码如何进入 Attention?
Q3: 激活函数、Norm、Dropout: FNN的重要细节?
FNN 在 LLM 里不只是一个“顺手接在 attention 后面的两层线性层”,它往往占据了大量参数,也承担了非线性表达能力。
所以在真正进入 FNN 结构本身之前,先把和它密切相关的几个细节讲清楚是很有必要的:激活函数、Norm 和 Dropout。
这些东西看起来像细节,但它们其实直接影响:
- 模型是否容易训练
- 梯度是否稳定
- 参数能不能有效发挥作用
- 最终收敛出来的效果如何
3.1 激活函数: 为什么今天更常见是 GELU、SiLU、SwiGLU?
经验上,今天的语言模型更常见的选择往往不是最早期的 ReLU,而是:
- GELU
- SiLU / Swish
- 或者进一步用于 gated MLP 的 SwiGLU
它们更常见,通常不是因为“名字更新”,而是因为在大模型训练里,它们往往表现得更平滑、更稳定,也更适合和现代 FFN 结构配合。
GELU
GELU(Gaussian Error Linear Unit)常见写法是:
$$ \mathrm{GELU}(x)=x ,\Phi(x) $$
其中:
- \( \Phi(x) \) 表示标准高斯分布的累积分布函数
实践中常见的近似写法是:
$$ \mathrm{GELU}(x)\approx 0.5x\left(1+\tanh\left(\sqrt{\frac{2}{\pi}}\left(x+0.044715x^3\right)\right)\right) $$
这也是很多代码里真正实现时更常看到的形式。
SiLU / Swish
SiLU 的形式写成:
$$ \mathrm{SiLU}(x)=x \cdot \sigma(x) $$
其中:
- \( \sigma(x) \) 表示 sigmoid 函数
也就是说:
$$ \sigma(x)=\frac{1}{1+e^{-x}} $$
所以 SiLU 也可以展开写成:
$$ \mathrm{SiLU}(x)=\frac{x}{1+e^{-x}} $$
SwiGLU
SwiGLU 常见于更现代的 gated FFN 结构里。它的一个常见写法可以记成:
$$ \mathrm{SwiGLU}(x,W,V)=\mathrm{SiLU}(xW)\odot(xV) $$
其中:
- \( W, V \) 表示两组不同的投影矩阵
- \( \odot \) 表示逐元素乘法
它的直觉是:
一条分支负责产生门控,另一条分支负责提供内容,最后逐元素相乘,让 FFN 的表达更细致。
一个经验性结论
如果只说一个非常实用的结论,我会更倾向于这么记:
- 小模型时代,ReLU 很常见
- 现代 LLM 里,更主流的是 GELU、SiLU,以及进一步用于 gated MLP 的 SwiGLU
3.2 Norm: 为什么它几乎是必须的?
Norm 的核心作用,是稳定训练过程。
如果没有这一步,随着层数加深,表示的尺度和梯度都更容易失控。
在真实的 LLM 代码里,Norm 并不是作用在一个孤立的“抽象向量”上,而通常是作用在形状为:
$$ X \in \mathbb{R}^{B \times n \times d} $$
的张量上,其中:
- \( B \) 表示 batch size
- \( n \) 表示序列长度
- \( d \) 表示 hidden size
对于 Transformer 里的 LayerNorm 或 RMSNorm,最常见的做法都是:
对最后一个维度 \( d \) 做归一化,也就是对每个 batch、每个位置对应的那一个 hidden vector 单独归一化。
也就是说,如果把某个位置的表示记成:
$$ x_{b,t,:} \in \mathbb{R}^{d} $$
那么 Norm 实际上是分别作用在每一个 \( x_{b,t,:} \) 上,也就是只沿着 feature 维度做归一化,而不会跨 batch 维或跨序列位置去做。这一点和 CNN 里的 BatchNorm、InstanceNorm 很不一样。一个直观理解是:在语言模型里,真正对应“同一个位置内部特征”的是最后这个 feature 维度;而 batch 维和序列位置维本身并不是应该拿来混在一起做归一化的量。
LayerNorm
如果先只看某一个位置的 hidden vector,可以写成:
$$ x=(x_1,x_2,\dots,x_d) $$
其中:
- \( d \) 表示特征维度
那么 LayerNorm 里先计算均值和方差:
$$ \mu=\frac{1}{d}\sum_{i=1}^{d}x_i,\qquad \sigma^2=\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2 $$
再做归一化:
$$ \mathrm{LayerNorm}(x)_i=\gamma_i\frac{x_i-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta_i $$
其中:
- \( \gamma_i,\beta_i \) 是可学习参数
- \( \epsilon \) 是数值稳定项
如果放回真实张量 \( X \in \mathbb{R}^{B \times n \times d} \) 来看,那么 LayerNorm 做的事情就是:
- 固定 \( b ) 和 \( t \)
- 对 \( X_{b,t,:} \) 这个长度为 \( d \) 的向量求均值和方差
- 再对这个向量本身做归一化
所以它是“对每个 token 的特征维度做归一化”,而不是“在整段序列上做归一化”。
RMSNorm
在很多较新的 LLM 里,RMSNorm 更常见。它通常不显式减去均值,而是直接根据均方根来做缩放:
$$ \mathrm{RMS}(x)=\sqrt{\frac{1}{d}\sum_{i=1}^{d}x_i^2} $$
$$ \mathrm{RMSNorm}(x)_i=\gamma_i\frac{x_i}{\mathrm{RMS}(x)+\epsilon} $$
其中:
- \( \gamma_i \) 是可学习缩放参数
- \( \epsilon \) 是数值稳定项
如果放回真实张量形状去理解,它和 LayerNorm 一样,最常见的也是对:
$$ X_{b,t,:} \in \mathbb{R}^{d} $$
这个最后一维向量逐个做处理。
为什么很多现代 LLM 喜欢 RMSNorm?
经验上,RMSNorm 常被认为:
- 形式更简单
- 参数和计算都更省一点
- 在大模型里表现很稳定
所以如果你在 MiniMind 或更现代的开源模型里看到 RMSNorm,这通常不是偶然,而是今天常见的设计取向。
Norm 在训练和推理时有区别吗?
对于 LayerNorm 和 RMSNorm 这类 Transformer 里常见的 Norm 来说,训练和推理阶段的行为通常没有本质区别。
也就是说:
- 训练时怎么按当前输入算
- 推理时也还是怎么按当前输入算
它不像 BatchNorm 那样会显式依赖“训练时统计量”和“推理时统计量”的切换。
这也是为什么在 Transformer / LLM 里,LayerNorm 和 RMSNorm 会比 BatchNorm 自然得多。
MiniMind 里 Norm 的实现和这里的讨论是直接对应的。它既保留了
RMSNorm,也额外实现了一个LayerNorm版本,两者都清楚标了[batch_size, seq_len, dim]这类 shape。对应实现来自 model_minimind.py。
MiniMind: RMSNorm 和 LayerNorm 的实现
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
"""
dim: embedding dim
weights: [dim,]
"""
super().__init__()
self.eps = eps
self.weights = nn.Parameter(torch.ones(dim))
def _norm(self, x):
# [batch_size, seq_len, dim] * [batchsize, seq_len , 1]
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
"""
x [batch_size, seq_len, dim]
return [barch_size,seq_len,dim]
"""
return self.weights.type_as(x) * self._norm(x.float()).type_as(
x
) # 处理不同的类型转化很重要
class LayerNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.beta = nn.Parameter(torch.zeros(dim))
self.gamma = nn.Parameter(torch.ones(dim))
def _norm(self, x):
mean = torch.mean(x, -1, keepdim=True) # [batchsize, seq_len , 1]
var = (x - mean).pow(2).mean(-1, keepdim=True) # [batchsize, seq_len , dim]
inv_std = torch.rsqrt(var + self.eps) # [batchsize, seq_len , dim]
return (x - mean) * inv_std
def forward(self, x):
"""
x [batch_size, seq_len, dim]
return [barch_size,seq_len,dim]
"""
norm_x = self._norm(x.float()).type_as(x)
return self.beta.type_as(x) + self.gamma.type_as(x) * norm_x
3.3 Dropout: 它到底在控制什么?
Dropout 的作用更偏向训练阶段的正则化。
它最粗略的形式可以写成:
$$ \tilde{x}=m\odot x $$
其中:
- \( x \) 表示输入
- \( m \) 表示随机 mask
- \( \odot \) 表示逐元素乘法
如果把保留概率写成 \( 1-p \),那么训练时更常见的写法可以记成:
$$ m_i \sim \mathrm{Bernoulli}(1-p) $$
并且常常还会做缩放:
$$ \tilde{x}_i=\frac{m_i}{1-p}x_i $$
这样做的目的是让训练和推理阶段的期望尺度更一致。
Dropout 的经验性设置
Dropout 最值得问的问题,通常是:
- 放在哪些位置?
- 比例设多少?
- 在今天的小模型和大模型里,这个设置是不是一致?
经验上:
- 早期 Transformer 往往更依赖 dropout
- 今天很多大模型,尤其数据量非常大时,dropout 可能会设得很小,甚至某些位置干脆不用
所以 dropout 并不是“越多越安全”,而是要和模型规模、数据规模、训练稳定性一起考虑。
需要注意的是,Dropout可能会在很多地方被使用,它虽然简单,但是出现的位置却很可能对训练稳定性有很大的影响,不得不进行注意,下面是Dropout可能会出现的几个位置
- Embedding Dropout(输入扰动)
- Attention Dropout(注意力权重扰动)
- Residual Dropout(残差连接前的扰动)
- FFN Dropout(前馈网络内部)
- Output Dropout(输出层前)
MiniMind 里实际上用到了下面这几种:
Embedding DropoutAttention DropoutResidual DropoutFFN Dropout
如果严格对照前面那张列表,它没有再单独定义一个额外的 Output Dropout;输出侧主要是直接接 lm_head 做词表投影。
对应实现都在 model_minimind.py 里:
MiniMind_Dense.dropout:embedding 后的 dropout,见 model_minimind.pyAttention.attn_dropout:attention 权重上的 dropout,见 model_minimind.pyAttention.resid_dropout:o_proj之后、回到残差支路之前的 dropout,见 model_minimind.pyFeedForward.dropout:FFN 内部、down_proj输出后的 dropout,见 model_minimind.py
MiniMind: Dropout 的几个实际位置
class FeedForward(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
...
self.dropout = nn.Dropout(config.dropout)
...
def forward(self, x: torch.Tensor):
...
return self.dropout(
self.down_proj(middle)
) # [...,hidden_dim] -> [..., intermediate_dim]
class Attention(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
...
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
...
def forward(...):
...
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
...
output = self.resid_dropout(
self.o_proj(output)
) # -> [batch_size, seq_len_q ,hidden_dim]
class MiniMind_Dense(torch.nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
...
self.dropout = nn.Dropout(config.dropout)
...
def forward(...):
...
hidden_states = self.dropout(self.embed_tokens(input_ids))
Dropout 在训练和推理时分别怎么表现?
这是一个非常值得单独说清楚的问题。
在训练阶段:
- Dropout 会随机把一部分神经元输出置零
- 同时对保留下来的部分做缩放
- 这样做的目的,是减少特征之间过度共适应,增强泛化
在推理阶段:
- Dropout 会被关闭
- 不再随机丢弃任何神经元
- 模型会直接使用完整的前向路径
也就是说,Dropout 在推理时通常不会继续“随机掉点”。
这也是为什么我们会在代码里看到:
model.train()时 Dropout 生效model.eval()时 Dropout 关闭
Dropout 对推理有什么影响?
从直接机制上说:
- 推理阶段 Dropout 本身通常是关闭的
- 所以它不会也不应该在推理时继续引入随机性
这一小节最值得记住什么?
如果只保留最关键的结论,我会更倾向于这样总结:
- 激活函数不是一个无关紧要的小选择,它直接影响 FFN 的非线性表达方式。
- Norm 不是“锦上添花”,而几乎是深层 Transformer 稳定训练的基础部件;而且Transformer的Norm一般都是作用在
[B, n, d]张量的最后一个feature维度上面. - Dropout 也不是固定模板,它和模型规模、数据规模、训练目标都有关系;并且它通常只在训练时生效,在推理时会被关闭。
所以这一节虽然在讲“细节”,但这些细节本身就是现代 LLM 能不能稳定训练起来的重要组成部分。
Q4: FFN / MLP 层在做什么?
Attention 负责不同 token 之间的信息交互,但如果只有 attention,模型的非线性表达能力还是不够。
Transformer block 里通常还会有一个前馈网络,也就是 FFN 或 MLP。最基础的形式可以写成:
$$ \mathrm{FFN}(x) = W_2\phi(W_1 x + b_1) + b_2 $$
其中:
- \( x \in \mathbb{R}^{d_{\text{model}}} \)
- \( W_1 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}} \)
- \( W_2 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}} \)
- \( d_{\text{ff}} \) 表示 FFN 中间层维度
可以把它粗略理解成:
- Attention 负责“跨 token 聚合信息”
- FFN 负责“在每个 token 自己的特征维度上做更强的非线性变换”
经验问题 1: FFN 中间层为什么通常更大?
因为 FFN 的核心作用,就是先把表示映射到一个更高维空间里做变换,再投回原维度。
所以很多实现里都会取:
$$ d_{\text{ff}} \approx 4 d_{\text{model}} $$
标准 Transformer 里,\( d_{\text{ff}} \approx 4d_{\text{model}} \) 是最经典的一条经验规则。到了更现代的 gated MLP 设计里,这个具体比例会变化,但核心思路没有变:中间层通常都会明显大于 hidden size。
直接看几组真实配置会更具体:
| 模型 | hidden size | intermediate size | 比值 \( d_{\text{ff}} / d_{\text{model}} \) | 激活 | 配置 |
|---|---|---|---|---|---|
| Llama-2-7B | 4096 | 11008 | 2.69 | SiLU / SwiGLU 系 | config |
| Llama-3-8B | 4096 | 14336 | 3.5 | SiLU | config |
| Qwen2.5-7B | 3584 | 18944 | 5.29 | SiLU | config |
这里最值得注意的不是“所有模型都刚好是 4 倍”,而是:
- 标准 Transformer 教科书式的 FFN 比例确实常写成 4 倍
- 到了 Llama、Qwen 这类更现代的结构里,具体数字会变
- 但中间层显著大于 hidden size 这件事基本没变
经验问题 2: 为什么第二个线性变换后通常不再接激活函数?
最基本的 FFN 写成:
$$ \mathrm{FFN}(x) = W_2\phi(W_1x+b_1)+b_2 $$
从这个形式可以看到:
- 第一层线性变换 \( W_1 \) 先把表示投影到更高维空间
- 中间的激活函数 \( \phi \) 提供非线性
- 第二层线性变换 \( W_2 \) 再把表示投影回 hidden size
也就是说,真正负责“打破纯线性结构”的关键步骤,已经发生在中间那一个激活函数上了。
第二个线性层更像是在做“重新压回原维度”和“重新组织特征”的工作。
这是 LLM 里一个很有意思的设计。它的思路更像是:先把表示投影到一个更适合做非线性变换的空间里,做完之后再投影回来,而不是单纯从“多堆几层 FNN 就能拟合任意函数”这种角度去理解。这个结构之所以一直被保留下来,核心还是因为它在长期实践里被证明是有效而且稳定的。
如果在第二个线性层后面再立刻接一个激活函数,通常会带来几个问题:
-
会改变残差连接希望接收的表示分布
Transformer block 里 FFN 的输出一般要和残差分支相加,所以最后输出如果再经过一次非线性,往往会让这一层的接口变得没那么干净。更准确地说,到了这一步,我们通常更希望拿到的是一个已经组织好的 feature 表示,而不是再额外套一层激活去继续改它的分布。 -
非线性已经够用了
两层线性层中间插一个激活函数,本身就已经让 FFN 具备了足够的非线性表达能力,通常不需要在最后再补一次。 -
工程上最稳定的主流结构就是这种形式
现代 Transformer / LLM 的主流 FFN 结构,基本都是“线性 -> 激活 / 门控 -> 线性”,而不是“线性 -> 激活 -> 线性 -> 激活”。
所以这里更准确的说法不是“绝对不能再接激活”,而是主流 LLM 基本都不这么做,因为没有明显收益,而且会让和残差分支的对接变得更别扭。
经验问题 3: FNN 一般做几层?
如果说最经典的 Transformer FFN,它本质上就是一个 两层 MLP:
$$ x \rightarrow W_1x \rightarrow \phi(\cdot) \rightarrow W_2(\cdot) $$
也就是说,最常见的答案其实非常简单:
- 标准 FFN 一般就是两层线性变换
这也是为什么大家平时说 Transformer 里的 FFN,默认通常就是在说这种“两层结构”。更复杂的变体当然也有,比如:
- gated MLP(例如 GLU、SwiGLU)
- 更复杂的 MoE 前馈层
但即使这些结构看起来更复杂,它们大多数也还是围绕“先升维做变换,再回到 hidden size”这个核心思路在发展。
如果只从实践经验出发,可以把结论压缩成:
- 对于标准 Transformer / GPT 类模型,FFN 默认就是两层
- 真正更值得花时间调的,通常不是“FFN 要不要做三层还是四层”,而是
- 中间层宽度多大
- 用什么激活函数
- 是否使用 gated FFN
也就是说,在现代 LLM 里,FFN 的“深度”通常不是首要可调项,FFN 的“宽度”和“具体结构形式”反而更关键。
MiniMind 这里的 FFN 不是最朴素的两层 MLP,而是更接近 LLaMA 系列的 gated FFN:gate_proj 和 up_proj 做逐元素乘法,再经过 down_proj 投回 hidden size。激活函数和 Dropout 也都在这里落地了。对应实现来自 model_minimind.py。
MiniMind: FeedForward / gated FFN 的实现
class FeedForward(nn.Module):
"""
GLU Gate Linear Unit的变体
From LLaMA 系列
LLaMA2 首次引入这种结构作为默认 FFN
Meta 的论文中称之为 Gated Linear Units with SiLU activation
更强的非线性建模能力:门控乘法能动态调节信息流
更好的训练稳定性:SiLU 激活 + 无 bias + 64 对齐
更高的参数利用率:相比单路径 FFN,双路径乘法更充分利用中间维度
"""
def __init__(self, config: MiniMindConfig):
super().__init__()
if config.intermediate_size is None:
intermediate_size = int(config.hidden_size * 8 / 3)
# 64 padding!
config.intermediate_size = 64 * ((intermediate_size + 64 - 1) // 64)
self.gate_proj = nn.Linear(
config.hidden_size, config.intermediate_size, bias=False
)
self.up_proj = nn.Linear(
config.hidden_size, config.intermediate_size, bias=False
)
self.down_proj = nn.Linear(
config.intermediate_size, config.hidden_size, bias=False
)
self.dropout = nn.Dropout(config.dropout)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x: torch.Tensor):
"""
x: [batch_size,seq_length,hidden_dim]
hidden_states already applied post_layernorm
Retuen: [batch_size,seq_length,hidden_dim]
"""
middle = self.up_proj(x) * self.act_fn(
self.gate_proj(x)
) # [...,hidden_dim] -> [..., intermediate_dim]
return self.dropout(
self.down_proj(middle)
) # [...,hidden_dim] -> [..., intermediate_dim]
Q5: Attention + FNN = Transformer层模型的核心!
到这一步,其实整个模型的架构已经基本清楚了。此时再回头看 Transformer 的结构,就会发现它的主干并不复杂:Attention + FFN 就构成了一个基本的 Transformer block,然后这些 block 一层一层堆起来,像是千层饼一样形成整个模型的 Transformer 主干。
关于 Attention 的更完整直觉和历史背景,可以参考 理解 Attention 机制。
在这一节里,我们只抓住模型定义里最关键的部分:每个 Transformer block 的输入和输出 shape 都保持一致,模型始终在同一个 hidden space 里不断做变换。
也就是说,随着层数增加,真正变化的不是 shape,而是表示本身:
- token 的编码会不断更新
- 上下文信息会不断混合进去
- 每个位置的 hidden state 会越来越“知道”整段序列里发生了什么
Attention 的核心公式
先只看单头 attention。
给定某一层的输入表示:
$$ X \in \mathbb{R}^{n \times d_{\text{model}}} $$
通常先通过三个线性变换得到:
$$ Q = XW_Q,\qquad K = XW_K,\qquad V = XW_V $$
其中:
- \( W_Q, W_K \in \mathbb{R}^{d_{\text{model}} \times d_k} \)
- \( Q, K \in \mathbb{R}^{n \times d_k} \)
- \( V \in \mathbb{R}^{n \times d_v} \)
最经典的 scaled dot-product attention 写成:
$$ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$
这个公式的含义可以拆成两步:
- 用 \( QK^\top \) 计算每个位置和其它位置的相关性(Attention Score),再通过 softmax 转成权重(概率)
- 再按这个权重对 \( V \) 做加权求和(期望)
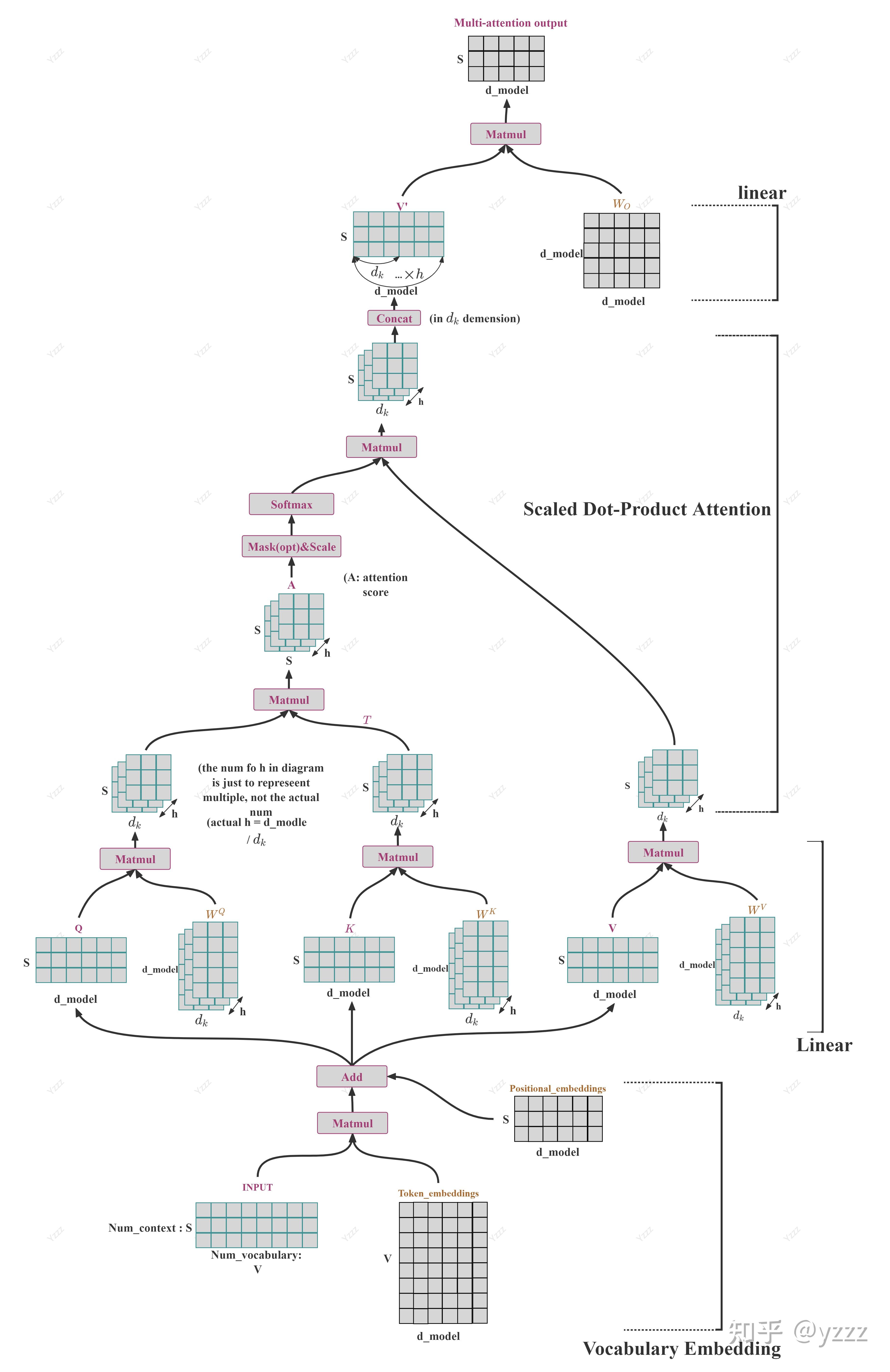
多头注意力
单头 attention 当然可以工作,但通常不够。
现代 Transformer 更常见的是多头注意力,也就是把 hidden size 切成多个 head,并行地在不同子空间里做 attention。
如果头数记作 \( h \),每个 head 的维度记作 \( d_{\text{head}} \),那么通常有:
$$ d_{\text{model}} = h \cdot d_{\text{head}} $$
这时我们不再只得到一组 \( Q,K,V \),而是得到每个 head 各自的一组表示。
如果把它们写成张量形式,再加上 batch 维,那么在真实代码里更常见的形式是:
$$ Q_i, K_i, V_i \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} $$
其中:
- \( d_{\text{head}} \) 表示每个 head 的维度
对每个 head,attention 的计算形式其实和单头时完全一样:
$$ \mathrm{head}_j=\mathrm{Attention}(Q_j,K_j,V_j) $$
其中:
- \( j = 1,2,\dots,h \)
- \( \mathrm{head}j \in \mathbb{R}^{n \times d{\text{head}}} \)
把所有 head 的结果拼接起来:
$$ \mathrm{Concat}(\mathrm{head}_1,\dots,\mathrm{head}h)\in \mathbb{R}^{n \times (h\cdot d{\text{head}})} $$
由于:
$$ h\cdot d_{\text{head}} = d_{\text{model}} $$
所以拼接之后的结果又会回到 hidden size 对应的维度。
最后再经过一个输出投影矩阵:
$$ W_O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}} $$
得到最终输出:
$$ \mathrm{MHA}(X)=\mathrm{Concat}(\mathrm{head}_1,\dots,\mathrm{head}_h)W_O $$
多头注意力虽然内部切成了很多 head,但最后输出还是会被重新投影回原来的 hidden size,所以输入输出 shape 仍然保持一致。
经验问题 1: head_dim 一般怎么选?
head_dim 往往不会单独拍脑袋定,而是直接由 hidden size 和头数一起确定:
$$ d_{\text{head}} = \frac{d_{\text{model}}}{n_{\text{heads}}} $$
直接看配置会更直观:
| 模型 | hidden size | attention heads | head dim |
|---|---|---|---|
| GPT-2 | 768 | 12 | 64 |
| GPT-2 Medium | 1024 | 16 | 64 |
| GPT-2 Large | 1280 | 20 | 64 |
| GPT-2 XL | 1600 | 25 | 64 |
| Llama-2-7B | 4096 | 32 | 128 |
| Llama-3-8B | 4096 | 32 | 128 |
| Qwen2.5-7B | 3584 | 28 | 128 |
从这些真实模型里可以直接看到一个很明显的现象:
- GPT-2 这一系的 head dim 基本固定在 64
- Llama、Qwen 这一类更现代的模型里,head dim 很常见的是 128
所以实践里通常不是“先定一个 head_dim,再凑别的参数”,而是先定 hidden size 和头数,再让它们自然相除。不能整除虽然理论上可以用投影矩阵去弥补,但是实际中鲜有采用.
head_num 一般怎么选?
这个问题和 head_dim 是绑在一起的。更实际的顺序通常是:
- 先定 hidden size
- 再选一个能整除 hidden size 的 head 数
- 看最后得到的 head dim 是否落在主流实现里常见的范围内
从上面的例子看,真实模型里最常见的结果其实很集中,通常就是 64 或 128 这两档。
经验问题 2: 为什么多头结果通常是拼接,而不是相加?
直觉上可以这样理解:
- 每个 head 都在不同子空间里学习不同关系
- 拼接能保留各个 head 的独立信息
- 然后再通过一个输出投影统一融合
如果一开始就直接相加,会发生什么?
-
各个 head 的信息会过早混在一起
这样模型还没来得及在输出投影层里统一组织这些信息,就已经把它们揉平了。 -
很难保留“每个 head 各学各的”这件事
多头注意力的一个核心好处,就是不同 head 可以在不同子空间里建模不同类型的关系。拼接能把这些差异先保留下来,相加则更容易把它们平均掉。 -
输出层的表达空间也会变小
拼接之后再接 \( W_O \),相当于给模型一个更大的融合空间;如果先相加,后面的输出投影能操作的信息就少很多。
所以从结构上看:
- 拼接更像是“先分别学,再统一融合”
- 相加更像是“过早合并”
而现代 Transformer 明显更偏向前者。
如果只给一个很直观的总结,我会更倾向于这么记:
- 多头注意力的意义,不只是“多算几遍 attention”
- 更关键的是让不同 head 的结果先独立存在
- 然后再通过输出投影把这些结果重新组织起来
这也是为什么主流实现几乎都会选择 concat,而不是直接 sum。
经验问题 3: Attention 复杂度为什么总被强调?
因为它最核心的计算通常来自:
$$ QK^\top $$
假设:
- \( n \) 表示序列长度
- \( d \) 表示 head 维度
那么复杂度通常可以粗略写成:
$$ O(n^2 d) $$
这也是为什么:
- 序列长度一上去,attention 代价会迅速上升
- 后面才会有 FlashAttention、长上下文优化等一系列工作
这也是为什么 attention 的复杂度总会被单独强调。
它不是一个只存在于公式里的理论问题,而是会立刻体现在:
- 训练速度
- 显存占用
- 长上下文推理代价
上。
如果再结合 attention score 的 shape 去看,这件事会更直观。因为:
$$ QK^\top \in \mathbb{R}^{n \times n} $$
所以只要序列一长,这个中间结果本身就会迅速变大。
从工程角度看,大家后来不断去做各种 attention 相关优化,基本都是在围绕这个瓶颈展开。
大方向上看,常见优化通常是在解决下面几类问题:
-
怎么减少真实计算和访存开销
例如 FlashAttention,核心不是改数学定义,而是改高效实现方式。 -
怎么降低长上下文带来的代价
也就是为什么长上下文优化会变成一个持续存在的主题。 -
怎么让推理阶段不要重复算
例如 KV cache,本质上也是在避免把已经算过的 K/V 重复计算。
所以如果只保留一个最重要的结论,我会更倾向于这么写:
- attention 很强,是因为它能让任意位置直接和其它位置交互
- attention 也很贵,是因为这种“全连接式交互”天然会带来 \( n^2 \) 级别的代价
这也是为什么后面的 RoPE、FlashAttention、GQA、KV cache、长上下文优化这些主题,虽然看起来各不相同,但很多都可以追溯到 attention 的这一个核心瓶颈。
如果只看这节正文真正对应的“标准 attention 主线”,MiniMind 里最值得看的有两段代码。
第一段是
MiniMindBlock:它把input_layernorm -> self_attn -> residual -> post_attention_layernorm -> mlp这条主路径写得很清楚。对应实现来自 model_minimind.py。
MiniMind: 一个 Transformer block 的主路径
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: MiniMindConfig):
super().__init__()
self.num_attention_heads = config.num_attention_heads
self.hidden_size = config.hidden_size
self.head_dim = config.hidden_size // config.num_attention_heads
self.self_attn = Attention(config)
self.layer_id = layer_id
self.input_layernorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(
config.hidden_size, eps=config.rms_norm_eps
)
assert not config.use_moe, "Moe not implemented "
# self.mlp = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
self.mlp = FeedForward(config)
def forward(
self,
hidden_states,
position_embeddings,
past_key_value=None,
use_cache=False,
attention_mask=None,
):
"""
hidden_states: torch.Tensor [batch_size, seq_length, hidden_dim]
input embeddings.
position_embeddings: (freqs_cos,freqs_sin) [seq_length,hidden_dim]
"""
residual = hidden_states
hidden_states, present_key_value = self.self_attn(
self.input_layernorm(hidden_states),
position_embeddings,
past_key_value,
use_cache,
attention_mask,
)
hidden_states += residual
hidden_states = hidden_states + self.mlp(
self.post_attention_layernorm(hidden_states)
)
return hidden_states, present_key_value
第二段是
Attention.forward里和本节主线最直接对应的部分。这里只保留了Q/K/V投影、RoPE 注入、softmax 权重和输出重排这些和正文公式一一对应的部分;MiniMind 里实际还包含KV cache、repeat_kv这些更偏后续专题的实现,这里先不展开。对应实现来自 model_minimind.py。
MiniMind: Attention 核心计算路径
bsz, seq_len, _ = x.shape
# [...,# q_heads * head_dim] [...,# kv_heads * head_dim] [...,# kv_heads * head_dim]
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
# [seq_length,head_dim],[seq_length,head_dim]
cos, sin = position_embeddings
# No RoPE on V
xq, xk = apply_rotary_pos_emb(xq, xk, cos[:seq_len], sin[:seq_len])
# xq xk xv
# [bsc, seq_length, #q_heads , head_dim]
xq, xk, xv = (
xq.transpose(1, 2),
xk.transpose(1, 2),
xv.transpose(1, 2),
)
# xq xk xv 标准的Attention输入
# [bsc, #q_heads, seq_length , head_dim]
# 手写Attention计算实现:
# Q @ K^T / sqrt(d)
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(
self.head_dim
) # [bsc, #q_heads, seq_length_q , seq_length_kv]
scores = F.softmax(scores.float(), dim=-1).type_as(
xq
) # [batch_size, num_heads, seq_len_q, seq_len_k] 数值变成softmax 权重
scores = self.attn_dropout(scores)
# scores: [bsc, #num_heads, seq_len_q , seq_len_k]
# xv : [bsc, #num_heads, seq_len_k, head_dim]
output = scores @ xv # -> [bsc, #num_heads, seq_len_q, head_dim]
# Reshape for output
output = output.transpose(
1, 2
) # [batch_size, num_heads, seq_len_q, head_dim] -> [batch_size, seq_len_q ,num_heads,head_dim]
output = output.reshape(
bsz, seq_len, -1
) # -> [batch_size, seq_len_q ,num_heads * head_dim]
output = self.resid_dropout(
self.o_proj(output)
) # -> [batch_size, seq_len_q ,hidden_dim]
Q6: 更多后期改进和优化?
这一节到这里,基础的模型结构就已经基本讲完了。在主干结构之外,后面还有很多继续优化的方向,它们的目标通常也比较明确:
- 更省显存
- 更快训练
- 更快推理
- 支持更长上下文
- 在不明显损伤表达能力的前提下,把这些优化做进去
这些后续的改进和优化,大多不是把主干结构整个改写掉,而是在已有结构上,围绕某一个明确目标继续往前做。也正因为如此,我会把它们先从主线里拿出来,放到后面的附属小节里单独讲。
这样处理,主要是为了让正文的结构更清楚一点。主线部分先回答“一个基础的预训练模型到底由哪些部分组成”,把最核心的结构梳理清楚;而这些后续优化,更像是一组并列展开的专题。它们之间当然也有关联,但整体上不是那种必须严格按前后顺序读下来的关系。
所以我觉得,这部分内容更适合按问题去读,而不是按顺序去读。比较自然的方式是先想清楚:自己现在更关心的到底是哪一类问题,比如是显存、推理速度,还是长上下文能力;然后再去挑对应的小节来看。
后面我也准备把更多相关的方法逐步补充到这一组专题里。比如:
- 有的在改位置信息进入 attention 的方式,比如 RoPE: 位置编码如何进入 Attention?
- 有的在改 attention 的底层实现方式,比如 FlashAttention: attention 为什么还能更快?
- 有的在改多头结构本身,比如 GQA: 为什么 Query head 和 KV head 可以不一样?
- 有的在改推理阶段的缓存方式,比如 KV Cache: 自回归推理为什么能避免重复计算?
- 有的在改长上下文扩展能力,比如 Long Context: 长上下文能力通常在改什么?
本小节总结.
这一节主要回答的是一个很基础的问题:如果只从模型结构出发看,一个预训练语言模型到底由哪些部分组成。
正文里,我是沿着一条比较顺的主线把这件事梳理下来的:先看模型整体的输入输出,再看输入侧的 Embedding 和位置表示是怎么进入模型的;然后再往里走,到 Transformer block 里最核心的 Attention 和 FFN;同时也顺手把激活函数、Norm、Dropout 这些看起来像细节、但实际上很影响训练和实现的部分一起交代清楚。
如果把这一节压缩成一句话,那么我觉得可以这样记:一个基础的 LLM,本质上就是把输入的 token id 先变成连续表示,再在同一个 hidden space 里经过多层 Transformer block 不断做上下文化变换,最后通过 LM head 投影回词表空间。
后面的小节,则是在这个主干结构的基础上,继续展开各个模块的细节,以及围绕显存、速度、长上下文等目标继续做的优化。也就是说,后续内容大多不是在改“LLM 的主干到底是什么”,而是在这个已经相对稳定的主干上继续做结构和工程上的改进。
进阶部分导言
这一节原本是放在 model basic 里的一个子章节,但后来随着相关内容越来越多,我把它单独拆了出来,作为一个独立章节来整理。
这一章主要记录的是围绕模型技术结构展开的一些后续改进与优化。例如,如何减少显存开销、如何提升训练或推理速度,以及如何支持更长上下文等。这些内容和基础模型主线的关系,更像是“专题展开”,而不是“主线必读”。
因此,这一章的阅读顺序和其他章节不太一样。它不需要在一开始就完整读完,下面各个小节也不是按照严格的先后顺序组织的。更合适的阅读方式是:当你在学习或实现中遇到某个具体问题时,再回到这里查阅对应的专题。
后面我也会继续把更多和模型结构优化相关的内容逐步补充到这一章里,让它慢慢成为一个围绕“模型改进点”的专题索引。
RoPE: 位置编码如何进入 Attention?
这一节单独把 RoPE 拿出来讲,因为它虽然属于“位置表示”这个主题,但它实际是直接作用在 attention 计算过程里的,而不是一个简单加在输入 embedding 上的小补丁。
这一节准备按下面三个层次展开:
- 核心思路:RoPE 为了解决什么问题提出?
- 数学定义:RoPE 在公式上到底是什么?
- 细节逻辑:它和 absolute positional embedding 有什么不同?为什么只作用在 \( Q/K \) 上?而没有出现在\( V \)上面?
Q1: 核心思路: RoPE 为了解决什么问题提出?
先看最早、最直观的位置编码思路。
设
- \( x_m \in \mathbb{R}^{d_{\text{model}}} \) 表示第 \( m \) 个位置的 token embedding
- \( p_m \in \mathbb{R}^{d_{\text{model}}} \) 表示第 \( m \) 个位置的位置向量
那么最朴素的 absolute positional embedding 写法是:
\[ \tilde{x}_m = x_m + p_m \]
这个做法当然能告诉模型“当前位置是第几个位置”,但它有一个特点:
- 位置信息是在输入层注入的
后面 attention 要怎么使用这些位置信息,还得依赖模型自己在训练中学出来。
RoPE 想解决的正是这里的问题。
它不满足于“先把位置混进输入里,再让模型自己想办法用”,而是进一步追问:
- 能不能让位置信息直接进入 attention score 的计算?
因为 attention 的核心就是:
\[ QK^\top \]
如果位置信息不能更直接地进入这一步,那么位置和匹配关系之间始终隔着一层“模型自己去学”的间接过程。
所以 RoPE 的核心思路可以先概括成一句话:
- 不在输入层加位置向量,而是在 \( Q/K \) 上做位置相关变换,让位置直接进入 attention 的匹配过程
从这个角度看,RoPE 想解决的不是“序列有没有顺序”这么泛的问题,而是一个更具体的问题:
- 在 attention 机制里,位置信息应该如何进入打分过程
Q2: 数学定义: RoPE 在公式上到底是什么?
先只看单个 attention head。
设
- \( x_m \in \mathbb{R}^{d_{\text{head}}} \) 表示第 \( m \) 个位置的输入表示
- \( W_Q, W_K \in \mathbb{R}^{d_{\text{head}} \times d_{\text{head}}} \) 表示 Query / Key 的投影矩阵
- \( q_m = x_m W_Q \)
- \( k_m = x_m W_K \)
在普通 attention 里,第 \( m \) 个位置和第 \( n \) 个位置之间的打分通常写成:
\[ s_{m,n} = \frac{q_m^\top k_n}{\sqrt{d_{\text{head}}}} \]
RoPE 做的事情是:
在计算 attention score 之前,先对 \( q_m \) 和 \( k_n \) 做一个和位置相关的旋转变换。
如果记位置 \( m \) 对应的旋转算子为 \( R_m \),那么:
\[ \tilde{q}_m = R_m q_m,\qquad \tilde{k}_n = R_n k_n \]
于是打分变成:
RoPE 的关键不在“旋转”这个词,而在于这个旋转是按二维子空间成对做的。
如果 \( d_{\text{head}} \) 是偶数,可以把一个向量拆成若干个二维块。
例如把 \( q_m \) 写成:
\[ q_m = (q_m^{(1)}, q_m^{(2)}, \dots, q_m^{(d_{\text{head}}/2)}) \]
其中每个 \( q_m^{(i)} \in \mathbb{R}^2 \)。
对第 \( i \) 个二维块,RoPE 使用一个二维旋转矩阵:
\[ R(m\theta_i)= \begin{bmatrix} \cos(m\theta_i) & -\sin(m\theta_i) \\ \sin(m\theta_i) & \cos(m\theta_i) \end{bmatrix} \]
这里:
- \( m \) 表示位置索引
- \( \theta_i \) 表示第 \( i \) 个频率
于是整个 \( R_m \) 可以理解成由这些二维旋转块拼成的分块对角矩阵:
\[ R_m = \mathrm{diag}\big(R(m\theta_1), R(m\theta_2), \dots, R(m\theta_{d_{\text{head}}/2})\big) \]
如果把 batch 和多头维度也写上,真实代码里更常见的张量形状是:
\[ Q, K \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} \]
RoPE 作用后 shape 不变,仍然是:
\[ \tilde{Q}, \tilde{K} \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} \]
也就是说,RoPE 改变的不是张量形状,而是 \( Q/K \) 在不同位置上的取值方式。
Q3: 细节逻辑: 它和 absolute positional embedding 有什么不同? 为什么只作用在 \( Q/K \) 上?
先看它和 absolute positional embedding 的区别。
两者最根本的差异,不是“一个新一个旧”,而是位置信息进入模型的位置不同:
- absolute positional embedding:位置先进入输入 \( \tilde{x}_m = x_m + p_m \)
- RoPE:位置直接进入 \( Q/K \) 的构造和打分
这意味着:
- absolute positional embedding 是“把位置信息交给模型后续去利用”
- RoPE 是“让位置信息直接参与 attention 匹配”
RoPE 更关键的一点在于,它会让 attention score 自然依赖相对位置。
因为二维旋转矩阵满足:
\[ R_m^\top R_n = R_{n-m} \]
所以:
这个式子很重要。
它说明 RoPE 后的内积,不再只是“第 \( m \) 个绝对位置”和“第 \( n \) 个绝对位置”各自挂了一个标签,而是它们的相对位移 \( n-m \) 直接进入了匹配过程。
这也是为什么 RoPE 经常会被说成“更适合 attention”的位置编码方式。
因为它不是停留在输入层,而是把位置关系带进了 attention score 本身。
再看为什么它只作用在 \( Q/K \) 上,而不作用在 \( V \) 上。
attention 的核心可以拆成两步:
- 用 \( Q \) 和 \( K \) 计算相关性
- 用这个相关性权重去加权 \( V \)
也就是说:
- \( Q/K \) 决定“当前应该关注谁”
- \( V \) 提供“被取回来的内容”
RoPE 想解决的是“位置信息如何进入匹配关系”这个问题,所以它自然作用在 \( Q/K \) 上。
如果把同样的旋转硬套到 \( V \) 上,反而会把“位置匹配”与“内容表示”混在一起。
所以更准确的说法不是“RoPE 恰好只做在 \( Q/K \) 上”,而是:
- 它本来就是为 \( Q/K \) 的匹配过程设计的
这一节之后最重要的收获是什么?
- RoPE 的提出,是为了让位置信息直接进入 attention score,而不是只停留在输入层。
- 它的数学定义是:对每个位置的 \( Q/K \) 做位置相关的二维分块旋转,再参与 attention 打分。
- 它和 absolute positional embedding 的关键区别,在于位置信息进入模型的位置不同。
- 它只作用在 \( Q/K \) 上,因为它首先要解决的是“如何匹配”,而不是“内容本身是什么”。
FlashAttention: attention 为什么还能更快?
这一节单独把 FlashAttention 拿出来讲,因为它特别容易让人误会成“另一种 attention 算法”。
但它真正重要的地方,其实不是改公式,而是改实现。
这一节准备回答几个问题:
- FlashAttention 到底在解决什么问题?
- 它有没有改变 attention 的数学定义?
- 为什么 attention 明明公式很清楚,工程上还是会很慢、很吃显存?
- 理解 FlashAttention 时,最值得记住的结论是什么?
Q1: FlashAttention 到底在解决什么问题?
先回到最普通的 scaled dot-product attention:
设
- \( Q \in \mathbb{R}^{n \times d_k} \)
- \( K \in \mathbb{R}^{n \times d_k} \)
- \( V \in \mathbb{R}^{n \times d_v} \)
那么 attention 写成:
$$ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$
这套数学定义本身没有问题,问题主要出在实现上。
因为如果直接按这个式子展开,往往会显式构造一个 shape 为 \( n \times n \) 的 attention score 矩阵:
$$ S = QK^\top \in \mathbb{R}^{n \times n} $$
当序列一长,这个中间结果就会很大:
- 显存占用会迅速上升
- 读写这个大矩阵本身也会变慢
- 训练和推理都容易被 memory bandwidth 卡住
所以 FlashAttention 主要解决的不是“attention 会不会算错”,而是:
- attention 能不能少存一些中间结果
- attention 能不能少做一些低效的显存读写
- 在不改数学结果的前提下,把实现做得更贴近 GPU
Q2: 它有没有改变 attention 的数学定义?
通常没有。
这是理解 FlashAttention 时最重要的一点之一。
它并不是把 attention 换成了另一个近似很强的新公式,而是尽量保持输出和标准 attention 一致,只是换了一种更高效的计算路径。
也就是说,下面这个目标没变:
$$ \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$
变的是“如何得到它”:
- 不再粗暴地把所有中间矩阵一次性完整落到显存里
- 而是更倾向于分块计算、边算边归约、尽量减少中间结果回写
所以一个更准确的说法是:
- FlashAttention 首先是 attention 的高效实现方案
- 而不是一种彻底改写定义的注意力机制
Q3: 为什么 attention 明明公式很清楚,工程上还是会很慢、很吃显存?
因为真正贵的,常常不是公式看起来有多复杂,而是中间张量有多大、数据搬运有多频繁。
以最基本的 attention 为例,中间会涉及:
- \( QK^\top \in \mathbb{R}^{n \times n} \)
- softmax 后的权重矩阵 \( A \in \mathbb{R}^{n \times n} \)
- 再和 \( V \) 相乘得到输出
所以当 \( n \) 变大时,问题不只是计算量接近 \( O(n^2 d) \),还包括:
- 中间激活会很大
- 显存读写会变重
- kernel 之间来回搬运数据会带来额外开销
这也是为什么很多 attention 优化工作,看起来都像是在“做实现细节”,但实际上影响很大。
因为在大模型里,底层实现细节本身就会直接决定吞吐、显存和可训练长度。
Q4: 理解 FlashAttention 时,最值得记住的结论是什么?
如果只保留最重要的几点,我觉得是:
- FlashAttention 主要优化的是 attention 的实现方式,而不是它的基本数学定义。
- 它之所以重要,是因为标准 attention 的中间结果很大,显存和带宽会很快成为瓶颈。
- 理解它最好的角度不是“新机制”,而是“更高效地把同一个机制跑起来”。
所以如果后面在代码里看到 flash_attn 这一类实现,第一反应不应该是“模型换结构了”,而更应该是:
- 这通常是在解决 attention 太慢、太吃显存的问题
GQA: 为什么 Query head 和 KV head 可以不一样?
这一节单独把 GQA 拿出来讲,因为它特别适合帮助我们理解一个现实问题:
- 为什么 attention 的很多改进,看起来是在改结构,实际上是在为推理效率和 KV cache 服务?
这一节准备回答几个问题:
- 标准多头注意力里,Q/K/V 的 head 数通常是什么关系?
- GQA 在改什么?
- 为什么很多模型会让 Query head 数多于 Key/Value head 数?
- GQA 和 KV cache 有什么关系?
Q1: 标准多头注意力里,Q/K/V 的 head 数通常是什么关系?
在最标准的 multi-head attention 里,通常会默认:
- Query 的 head 数和 Key 的 head 数一样
- Key 的 head 数和 Value 的 head 数一样
如果把 head 数记作 \( h \),那么常见写法是:
$$ Q, K, V \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} $$
这里:
- \( B \) 表示 batch size
- \( n \) 表示序列长度
- \( h \) 表示 head 数
- \( d_{\text{head}} \) 表示每个 head 的维度
这也是最容易理解的形式,因为每个 Query head 都能直接对应一个 Key/Value head 去做 attention。
Q2: GQA 在改什么?
GQA 的核心想法是:
- 不一定要让 Query head 数和 Key/Value head 数完全一样
更具体一点,可以记成:
$$ h_q > h_{kv} $$
其中:
- \( h_q \) 表示 Query 的 head 数
- \( h_{kv} \) 表示 Key/Value 的 head 数
这意味着模型会保留更多的 Query heads,但让多个 Query heads 共享同一组 Key/Value heads。
从“数学形式”上看,这不是把 attention 完全改写了。
从“工程含义”上看,它是在做一个非常现实的权衡:
- 尽量保留 Query 侧的表达能力
- 同时减少 Key/Value 侧的存储和缓存开销
Q3: 为什么很多模型会让 Query head 数多于 Key/Value head 数?
这里最值得记住的直觉是:
- Query 是当前时间步动态计算出来的
- Key / Value 在自回归推理时是可以缓存的
也就是说,在生成第 \( t \) 个 token 时:
- 当前 token 的 \( Q_t \) 需要重新算
- 历史 token 的 \( K_{1:t} \)、\( V_{1:t} \) 往往已经在 cache 里
所以很多实现会更愿意把“节省资源”的重点放在 K/V 上。
因为真正会被长期存起来、并且随着上下文变长不断累积的,是 K/V cache。
从这个角度看,保留更多 Query heads 的动机通常是:
- 尽量保留多头注意力在不同子空间建模的能力
减少 Key/Value heads 的动机通常是:
- 降低 KV cache 的显存占用
- 降低推理时和 K/V 相关的访存与计算开销
所以一个很实用的记法是:
- 保留更多 Q heads,主要是在保表达力
- 减少 K/V heads,主要是在省缓存和推理成本
Q4: GQA 和 KV cache 有什么关系?
它们的关系其实非常直接。
如果标准多头注意力中:
$$ K, V \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} $$
那么缓存这些 K/V 时,显存占用会直接和 \( h \) 成正比增长。
而如果改成 GQA,让 Key/Value 的 head 数变成 \( h_{kv} \),那么缓存张量更接近:
$$ K, V \in \mathbb{R}^{B \times h_{kv} \times n \times d_{\text{head}}} $$
只要 \( h_{kv} < h_q \),KV cache 的占用就会明显下降。
这也是为什么 GQA 经常和 KV cache 一起讨论。
它不只是一个“结构设计小技巧”,而是会直接影响:
- 长上下文推理时的显存压力
- 大 batch 推理时的吞吐
- 部署时能不能把模型跑起来
这一节之后最重要的收获是什么?
如果只保留最重要的几点,我觉得是:
- 标准多头注意力通常默认 Q/K/V head 数相同,但这不是不可动的规则。
- GQA 的核心是在尽量保留 Query 侧表达能力的同时,减少 Key/Value 侧的缓存成本。
- 它之所以重要,不只是因为“结构有点不一样”,而是因为它直接影响推理时最昂贵的 KV cache。
所以如果后面在代码里看到:
num_attention_headsnum_key_value_heads
这往往就是在告诉我们:
这个模型已经不再使用最朴素的标准 MHA,而是在朝着 GQA 这样的推理友好结构靠拢。
KV Cache: 自回归推理为什么能避免重复计算?
这一节单独把 KV Cache 拿出来讲,因为它几乎是理解 LLM 推理效率时绕不过去的一步。
很多人第一次看生成代码时会疑惑:
- 为什么模型不是每生成一个 token,就把整个前缀全部重新算一遍?
KV Cache 就是在回答这个问题。
这一节准备回答几个问题:
- KV Cache 到底缓存了什么?
- 为什么它能减少推理开销?
- 它会带来什么代价?
- 为什么它和 GQA 经常一起出现?
Q1: KV Cache 到底缓存了什么?
在 attention 里,给定某一层输入 \( X \),通常会先得到:
$$ Q = XW_Q,\qquad K = XW_K,\qquad V = XW_V $$
在自回归生成时,如果当前已经生成到第 \( t \) 个位置,那么第 \( t \) 步最关心的是:
- 当前 token 的 Query
- 历史所有 token 的 Key 和 Value
也就是说,当前步真正要拿来做 attention 的通常是:
$$ Q_t,\quad K_{1:t},\quad V_{1:t} $$
其中最适合缓存的是:
- 历史位置已经算好的 \( K \)
- 历史位置已经算好的 \( V \)
所以 KV Cache 本质上就是:
- 把历史 token 的 K/V 保留下来
- 下一步只增量追加当前 token 对应的新 K/V
Q2: 为什么它能减少推理开销?
如果没有 KV Cache,那么每生成一个新 token,都要把整个前缀重新过一遍 attention。
前缀越长,重复计算越多。
而有了 KV Cache 之后,生成第 \( t \) 个 token 时:
- 不需要重新计算前 \( 1 \sim t-1 \) 个位置的 K/V
- 只需要计算当前新位置的 K/V
- 再把当前 Query 和历史缓存过的 K/V 做 attention
从直觉上看,它做的事情很简单:
- 把“整段前缀重复算”变成“历史结果复用 + 当前步增量算”
所以 KV Cache 的直接收益通常就是:
- 降低重复计算
- 降低单步生成延迟
- 让长文本生成更可接受
Q3: 它会带来什么代价?
KV Cache 不是白来的。
它省下了重复计算,但会把压力转移到缓存占用上。
如果某层的 K/V 形状写成:
$$ K, V \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} $$
那么随着生成长度 \( n \) 增加,缓存也会持续变大。
而且这是每一层都要存的,所以总占用会很可观。
这也是为什么在推理阶段,我们经常会同时关心:
- 序列长度
- 层数
- head 数
- \( d_{\text{head}} \)
- dtype
因为这些都会直接影响 KV cache 的总大小。
Q4: 为什么它和 GQA 经常一起出现?
因为 KV Cache 里存的就是 K/V。
所以只要能减少 Key/Value 的 head 数,就能直接减少缓存开销。
这就是 GQA 重要的地方之一。
如果标准多头注意力缓存的是:
$$ K, V \in \mathbb{R}^{B \times h \times n \times d_{\text{head}}} $$
而 GQA 改成:
$$ K, V \in \mathbb{R}^{B \times h_{kv} \times n \times d_{\text{head}}} $$
并且 \( h_{kv} < h \),那 KV cache 的显存占用就会跟着下降。
所以很多时候:
- KV Cache 回答的是“为什么推理不用反复重算”
- GQA 回答的是“既然要缓存,怎样把缓存做得更省”
这一节之后最重要的收获是什么?
如果只保留最重要的几点,我觉得是:
- KV Cache 缓存的是历史 token 的 Key 和 Value,而不是整个模型的所有中间结果。
- 它的核心价值是把重复前缀计算改成增量计算,从而降低生成延迟。
- 它省的是算力,换来的是显存占用,所以推理优化常常会围绕 KV cache 展开。
如果后面在代码里看到:
past_key_valuesuse_cache=True
基本就可以直接联想到:
这里正在利用 KV cache 做自回归推理加速。
Long Context: 长上下文能力通常在改什么?
这一节单独把“长上下文”拿出来讲,因为它很容易被说成一个单一问题,但实际上它往往是好几类问题叠在一起:
- 序列变长之后,attention 本身更贵了
- 位置信息如何表示会变得更敏感
- 推理时 KV cache 会更大
- 模型在超出原训练长度后,表现还可能明显退化
这一节准备回答几个问题:
- 为什么长上下文会变成单独的优化方向?
- 长上下文问题通常不只是“attention 太慢”这么简单
- YaRN 这一类工作大致在改什么?
- 看长上下文优化时,应该抓住哪些主线?
Q1: 为什么长上下文会变成单独的优化方向?
因为序列一长,很多原本不明显的问题会一起放大。
比如:
- attention 的中间矩阵更大
- 训练和推理的显存压力更高
- KV cache 更容易成为瓶颈
- 原本的位置表示方式未必还能稳定工作
所以“把上下文从 2k 拉到 32k、128k,甚至更长”并不是一个只改配置文件的小动作。
它通常会牵涉到:
- 位置建模
- attention 实现
- 推理缓存
- 训练分布和泛化能力
Q2: 长上下文问题通常不只是“attention 太慢”这么简单
如果只从计算复杂度看,attention 的一个核心瓶颈是:
$$ QK^\top \in \mathbb{R}^{n \times n} $$
所以随着 \( n \) 增长,计算和存储压力都会迅速上升。
但在真实模型里,长上下文问题往往至少有两层:
- 能不能算得动
- 算得动之后,结果还好不好
第一层偏工程:
- 显存够不够
- attention 是否足够高效
- KV cache 会不会爆
第二层偏建模:
- 位置关系在更长范围里还能不能稳定表达
- 模型有没有在训练时真正见过足够长的上下文
- 超出原训练长度后性能会不会快速掉下去
所以长上下文优化不能只盯着一个公式看,而要同时看“算力”和“表示能力”。
Q3: YaRN 这一类工作大致在改什么?
像 YaRN 这一类方法,通常可以粗略理解成:
- 它们不是重新定义 Transformer
- 而是在想办法让已有的位置建模方式,尤其是像 RoPE 这样的方案,更平滑地扩展到更长上下文
换句话说,它们更关心的是:
- 长度拉长后,位置表示如何继续保持可用
- 如何减少超出原训练长度后的性能退化
所以如果把它和 FlashAttention、KV Cache 放在一起看,会发现它们关注的重点并不一样:
- FlashAttention 更偏实现效率
- KV Cache 更偏推理复用
- YaRN 这类方法更偏长上下文下的位置建模与泛化
Q4: 看长上下文优化时,应该抓住哪些主线?
如果只保留几个最核心的观察,我会更倾向于抓下面几条:
- 长上下文首先是一个系统问题,而不是某个单一模块的问题。
- 很多工作表面都在讲“支持更长长度”,但实际可能分别在改:
- 位置表示
- attention 实现
- 推理缓存
- 训练策略
- 判断一种长上下文方案时,至少要同时问两件事:
- 它让模型更长,是因为更省资源了?
- 还是因为位置建模本身更稳了?
这一节之后最重要的收获是什么?
如果只保留最重要的几点,我觉得是:
- 长上下文不是一个单点技巧,而是一组互相耦合的问题。
- 它既涉及 attention 的计算效率,也涉及位置表示和训练泛化。
- 像 YaRN 这样的工作,更适合放在“长上下文扩展”这条线上理解,而不是和所有 attention 优化混成一类。
所以如果后面看到“长上下文优化”这类说法,最好先追问一句:
- 这次优化主要是在解决算不动,还是在解决拉长之后不稳定?
Pretrain 训练导言
终于进入激动人心的训练部分了。
前面几节更多是在回答“模型是什么”:Language Model 是什么,Transformer 是什么,Attention 怎么算,Tokenizer 如何把文本变成 token id。可是只知道这些定义,和真正把一个模型训练出来,中间还隔着很长的一段路。
这也是我觉得 MiniMind 很有价值的地方。它不只是给出一段模型结构代码,而是提供了一个真实、完整、又足够小的训练入口。以前我也通过 NLP 课程和各种文章学过很多概念,比如语言模型、交叉熵、优化器、学习率、梯度下降。单独看每个概念,好像都能理解;但一旦离开上下文,很快又会变得模糊。直到真正跑起 MiniMind 的 pretrain 流程,这些东西才开始连成一条线。
模型训练本身是一件非常复杂的事情。它当然有理论基础,但工程上还有大量经验性的细节:数据怎么组织,loss 怎么算,学习率怎么调,梯度为什么会爆,混合精度为什么会出 NaN,断点恢复到底保存了什么,训练日志里哪些指标真正值得看。这些问题如果只停留在抽象层面,很难形成直觉;只有真的训练一次,才会发现训练不是“调用一个脚本”这么简单。
不过也需要先说明边界。这里的讨论主要基于 MiniMind 这样的个人可复现实验,以及一类相对小规模的模型训练经验。对于真正工业级的大模型,训练规模、数据规模、并行策略和工程复杂度都会高很多。所以这一章里的结论不能直接外推到所有大模型训练场景。更合理的态度是:把 MiniMind 当成一个最小但完整的观察窗口,通过它理解 pretrain 的核心问题和常见坑。
这一章我仍然会尽量用 QA 的方式来组织。因为训练部分最适合从问题出发:为什么 pretrain 的 loss 是交叉熵?为什么不是 BCE?为什么要做梯度累积?GradScaler 到底在缩放什么?loss 下降是不是就代表模型变好了?这些问题看起来很细,但它们恰好组成了训练代码里最关键的骨架。
这一节之后,Pretrain 训练部分会先按“理论问题”和“实际操作”两条线展开。
理论部分会尽量先回答训练到底涉及哪些核心问题:
- 损失函数是什么:pretrain 为什么是 next token prediction,为什么用 Cross Entropy Loss,以及代码里的
loss_mask如何影响 loss。 - 优化器是什么:参数更新到底在做什么,为什么大模型训练里常见的是 AdamW。
- Learning Rate 如何设置和调整:学习率为什么重要,为什么需要 schedule,MiniMind 里的 cosine decay 对应什么含义。
- 数据如何设置:数据集质量、数据分布、
max_seq_len、padding、truncation、batch size 和有效 batch size 会如何影响训练。 - 训练过程中如何评估效果:training loss、validation loss、perplexity 和生成样例分别能说明什么。
这些内容都会拆成不同的小节展开。Loss 会单独成节,优化器、学习率和数据设置会放在一节里,Eval 也会单独成节。
实际操作部分则更关注训练能不能稳定跑起来,包括分布式训练、混合精度、梯度累积、梯度缩放、梯度裁剪、seed、checkpoint、可视化和断点恢复。这些内容不只是工程实现,也常常是训练中最容易踩坑的地方。
最后再回到 MiniMind 的实际训练流程,记录数据准备、训练命令、输出目录和实验现象。
我也建议在阅读训练部分之前,先把 MiniMind 的最小训练流程跑起来。哪怕模型效果很弱,哪怕输出还前言不搭后语,只要完整跑过一次,后面再看 loss、optimizer、AMP、checkpoint 和 eval,就会有完全不同的感觉。
Pretrain 的训练目标和 Loss
这一节先回答 Pretrain 中最核心的理论问题:
- 模型到底在学什么,loss 是怎么定义的?
- 为什么 MiniMind 的 pretrain 用的是 Cross Entropy Loss?
- LLM真的使用了交叉熵Loss吗?如何严格的推导损失函数的形式?
以及一个非常现实,但却能极大的方便理解的问题:
- 实际的训练数据集是什么样子的?
Q1: Pretrain 阶段模型到底在预测什么?
以 GPT 类自回归语言模型为例,pretrain 的核心任务是 next token prediction,也就是根据前面的 token 预测下一个 token。
假设一段文本经过 tokenizer 之后得到 token 序列:
\[ x_1, x_2, \cdots, x_T \]
其中,\(x_t\) 表示第 \(t\) 个 token id,\(T\) 表示序列长度。
自回归语言模型会把整段文本的联合概率拆成一连串条件概率:
\[ p(x_1, x_2, \cdots, x_T) = \prod_{t=1}^{T} p(x_t \mid x_1, x_2, \cdots, x_{t-1}) \]
也就是说,模型不是一次性预测整段文本,而是在每个位置上预测“下一个 token 应该是什么”。这是一个自回归(AutoRegressive)的过程,所以只需要有任何无标注的自然文本(只需要把文本往后错一位,作为预测的ground truth即可),就可以进行自监督学习(Self‑Supervised Learning).这是模型可以scaling up的基石.
但是需要注意的是,对于一个句子,模型并不是依次预测 \(x_1\) (根据上下文预测第一个 token),\(x_2\) (根据上下文预测第二个 token),一直到 \(x_T\) (根据上下文预测最后一个 token),而是并行预测所有token作为loss整体计算,也就是说模型不但学习了如何预测下一个词,同时也是被隐式约束了如何预测整个句子.
Q1.1 实际训练数据的样子?
这是Minimind中预训练数据集的示例,实际上预训练数据集非常大,即使是纯文本数据,也有几个GB的规模,并且高质量数据集是模型效果好的重要条件.
{"text": "如何才能摆脱拖延症?治愈拖延症并不容易,但以下建议可能有所帮助。"}
{"text": "清晨的阳光透过窗帘洒进房间,桌上的书页被风轻轻翻动。"}
{"text": "Transformer 通过自注意力机制建模上下文关系,是现代大语言模型的重要基础结构。"}
在代码里,这个思想通常会被实现成输入和标签错开一位:
# src/minimind_learning/dataset/lm_dataset.py
input_ids = encoding.input_ids.squeeze()
loss_mask = (input_ids != self.tokenizer.pad_token_id)
X = torch.tensor(input_ids[:-1], dtype=torch.long)
Y = torch.tensor(input_ids[1:], dtype=torch.long)
loss_mask = torch.tensor(loss_mask[1:], dtype=torch.long)
return X, Y, loss_mask
这里的 X 是去掉最后一个 token 的输入序列,Y 是去掉第一个 token 的目标序列。于是模型在位置 \(t\) 看到的是 \(x_1, \cdots, x_t\),要预测的是 \(x_{t+1}\)。
Q2: 为什么 Pretrain 用 Cross Entropy Loss?
根据上文思想,模型是在一个离散的Vocab Size的词表上进行多分类,并且输出的是每个分类的上面的概率,即输出了一个概率分布.我们希望最大化正确分类的的概率,所以这相当于需要优化整个分布,所以这个Loss中有 Entropy这个名称.虽然他看起来好像只是在最优化选择正确的概率,但实际上这只是这个分布式离散的onehot分布产生的错觉. 下面给出 Cross Entropy Loss 的定义。
假设真实分布是 \(p\),模型预测分布是 \(q\),词表大小为 \(V\)。对于一个离散分类问题,交叉熵定义为:
\[ H(p, q)=-\sum_{i=1}^{V}p_i \log q_i \]
其中,\(p_i\) 表示真实分布中第 \(i\) 个类别的概率,\(q_i\) 表示模型预测第 \(i\) 个类别的概率。
在 pretrain 的 next token prediction 里,真实标签通常是一个 one-hot 分布。也就是说,真实的下一个 token 只有一个正确类别。假设真实 token id 是 \(y\),那么:
\[ p_i = \begin{cases} 1, & i = y \\ 0, & i \ne y \end{cases} \]
代入交叉熵公式后,只有正确类别 \(y\) 那一项会保留下来:
\[ H(p, q)=-\log q_y \]
所以从表面上看,Cross Entropy Loss 好像只是在最大化正确 token 的概率;但更准确地说,它是在比较两个离散分布:真实的 one-hot 分布和模型预测出来的词表概率分布。只是因为真实分布是 one-hot,公式最后才简化成了 \(-\log q_y\)。
具体来说在每一个预测位置上,模型最初的输出的不是一个单独的概率,而是对整个词表的打分。
假设词表大小为 \(V\),模型在第 \(t\) 个位置输出 logits:
\[ z_t \in \mathbb{R}^{V} \]
其中,\(z_{t,i}\) 表示模型认为第 \(i\) 个 token 作为下一个 token 的原始分数。经过 softmax 之后,可以得到模型预测的概率分布:
\[ q_\theta(i \mid x_{\le t}) = \frac{\exp(z_{t,i})}{\sum_{j=1}^{V}\exp(z_{t,j})} \]
其中,\(q_\theta(i \mid x_{\le t})\) 表示参数为 \(\theta\) 的模型,在看到前文 \(x_{\le t}\) 后,认为下一个 token 是 \(i\) 的概率。
真实标签只有一个 token id。假设真实的下一个 token 是 \(y_t\),那么这个位置的交叉熵损失就是:
\[ \ell_t = -\log q_\theta(y_t \mid x_{\le t}) \]
这句话很关键:Cross Entropy Loss 会惩罚模型没有把足够高的概率分给真实 token。
MiniMind 的训练代码里对应的是:
# src/minimind_learning/trainer/train_pretrain.py
loss_fct = nn.CrossEntropyLoss(reduction='none')
with autocast_ctx:
# X: [batch_size, seq_len]
res = model(X)
# res.logits: [batch_size, seq_len, vocab_size]
# 每一个 token 位置都会输出一个 vocab_size 维的 logits,
# 表示模型对“下一个 token 属于词表中每个类别”的原始打分。
loss = loss_fct(
# [batch_size, seq_len, vocab_size]
# -> [batch_size * seq_len, vocab_size]
# 把 batch 维和 seq_len 维合并,把每个 token 位置都看成一个分类样本。
res.logits.view(-1, res.logits.size(-1)),
# Y: [batch_size, seq_len]
# -> [batch_size * seq_len]
# 每个元素是对应位置的真实 next token id。
Y.view(-1)
).view(Y.size())
# loss: [batch_size * seq_len] -> [batch_size, seq_len]
# reduction='none' 表示暂时不求平均,保留每个 token 位置自己的 loss,
# 后面还要用 loss_mask 去掉 padding token。
这里 res.logits 的形状是 [batch_size, seq_len, vocab_size]。也就是说,batch 里的每一个样本、每一个 token 位置,都会输出一个覆盖整个词表的分类分布。
PyTorch 这里容易让人迷惑的一点是:nn.CrossEntropyLoss 当然支持 batch,但它默认把第 2 个维度当成类别维。常见输入形状是 [N, C],其中 \(N\) 是样本数,\(C\) 是类别数;如果是更高维输入,也通常要求形状类似 [N, C, d1, d2, ...]。
但语言模型的 logits 通常是 [batch_size, seq_len, vocab_size],类别维 vocab_size 在最后一维。为了让 CrossEntropyLoss 正确理解“每个 token 位置是一个分类样本,类别数是 vocab_size”,MiniMind 这里选择把前两维展平:
\[ [B, L, V] \rightarrow [B \times L, V] \]
其中,\(B\) 表示 batch size,\(L\) 表示序列长度,\(V\) 表示词表大小。
对应的标签也要从:
\[ [B, L] \rightarrow [B \times L] \]
这样展平之后,CrossEntropyLoss 看到的就是一个标准多分类问题:一共有 \(B \times L\) 个样本,每个样本有 \(V\) 个类别,标签是一个真实 token id。算完后再 .view(Y.size()) 还原回 [batch_size, seq_len],方便后面和 loss_mask 对齐。
MiniMind3 升級的Shifted LM Loss
旧版训练代码中,Dataset 返回 (X, Y, loss_mask),训练脚本手动计算交叉熵:
loss = loss_fct(
# B batch size, L sequence length, V vocab size
# [B,L,V] -> [B*L,V]
res.logits.view(-1, res.logits.size(-1)),
Y.view(-1)
).view(Y.size())
loss = (loss * loss_mask).sum() / loss_mask.sum()
MiniMind 3 更接近 HuggingFace 模型的接口习惯:Dataset 返回 input_ids 和 labels,模型内部完成 shift 和 ignore_index=-100 的 loss 计算。
对应代码在 src/minimind_learning/model/model_minimind.py:
loss = None
if labels is not None:
# shifted LM loss
# B batch size, L sequence length, V vocab size
# logits : [B,L,V] -> [B,L-1,V]
# labels: [B,L] -> [B,L-1]
x = logits[..., :-1, :].contiguous()
y = labels[..., 1:].contiguous()
loss = F.cross_entropy(x.view(-1, x.size(-1)), y.view(-1), ignore_index=-100)
这个变化看起来只是接口变化,但实际影响很大:pretrain、SFT、DPO 都可以围绕同一种模型输出结构来组织,训练脚本不再需要各自手写一套语言模型 loss。
Q3: BCE、Cross Entropy 和 KL 散度有什么关系?
这里先把几个常见 loss 的数学形式放在一起。它们不是完全割裂的东西,而是在不同任务设定下对“分布差异”的不同写法。
KL 散度
假设真实分布是 \(p\),模型预测分布是 \(q\),离散类别数为 \(V\)。KL 散度定义为:
\[ D_{\mathrm{KL}}(p \Vert q)=\sum_{i=1}^{V}p_i \log \frac{p_i}{q_i} \]
其中,\(p_i\) 表示真实分布中第 \(i\) 个类别的概率,\(q_i\) 表示模型预测第 \(i\) 个类别的概率。
KL 散度衡量的是:如果真实分布是 \(p\),但我们用 \(q\) 去近似它,会多付出多少信息代价。
!注意 KL 散度不是一个对称的距离,也就是说 \(D_{\mathrm{KL}}(p \Vert q)\) 和 \(D_{\mathrm{KL}}(q \Vert p)\) 是不一样的。
Cross Entropy
交叉熵定义为:
\[ H(p, q)=-\sum_{i=1}^{V}p_i \log q_i \]
\[ H(p, q)=-\mathbb{E}_{x \sim p}[\log q(x)] \]
它和 KL 散度的关系可以直接展开:
\[ D_{\mathrm{KL}}(p \Vert q)=\sum_{i=1}^{V}p_i \log \frac{p_i}{q_i} =\sum_{i=1}^{V}p_i \log p_i-\sum_{i=1}^{V}p_i \log q_i \]
而真实分布 \(p\) 的熵为:
\[ H(p)=-\sum_{i=1}^{V}p_i \log p_i \]
所以:
\[ D_{\mathrm{KL}}(p \Vert q)=H(p, q)-H(p) \]
也就是:
\[ H(p, q)=H(p)+D_{\mathrm{KL}}(p \Vert q) \]
在训练时,真实数据分布 \(p\) 是固定的,\(H(p)\) 不依赖模型参数 \(\theta\)。因此最小化 Cross Entropy \(H(p, q_\theta)\),等价于最小化 KL 散度 \(D_{\mathrm{KL}}(p \Vert q_\theta)\)。
one-hot 标签下的 CE
在 next token prediction 中,真实标签通常是 one-hot 分布。假设真实类别是 \(y\),则:
\[ p_i = \begin{cases} 1, & i = y \\ 0, & i \ne y \end{cases} \]
代入交叉熵:
\[ H(p, q)=-\sum_{i=1}^{V}p_i \log q_i=-\log q_y \]
所以 PyTorch 里的多分类 CrossEntropyLoss,在 one-hot 标签场景下,最终就变成了对真实类别概率取负对数。(它其实是个distribution loss,而不是最大化某个概率)
这也是语言模型 pretrain 的形式:
\[ \ell_t=-\log q_\theta(y_t \mid x_{\le t}) \]
其中,\(y_t\) 是第 \(t\) 个位置的真实 next token。
BCE
BCE 是 Binary Cross Entropy,也就是二分类交叉熵。二分类时,标签 \(y \in {0, 1}\),模型预测正类概率为 \(\hat{y}\)。
二分类可以看成一个两类分布:
\[ p = [y, 1-y] \]
\[ q = [\hat{y}, 1-\hat{y}] \]
把它代入交叉熵公式:
\[ H(p, q)=-\sum_{i=1}^{2}p_i \log q_i \]
得到:
\[ \mathrm{BCE}(y, \hat{y})=-\left[y \log \hat{y}+(1-y)\log(1-\hat{y})\right] \]
所以 BCE 不是另一种完全独立的 loss,而是 Cross Entropy 在二分类问题下的特例。
小结
这几者的关系可以简化成:
- KL 散度衡量两个分布之间的差异。
- Cross Entropy 和 KL 散度只差一个不依赖模型参数的 \(H(p)\),所以优化 CE 等价于优化 KL。
- one-hot 多分类下,CE 简化为 \(-\log q_y\)。
- 二分类下,CE 就是 BCE。
回到 pretrain,next token prediction 是在整个词表上做多分类,而不是二分类。因此代码中使用的是多分类 Cross Entropy Loss。
Q4: LLM真的使用了交叉熵Loss吗?
LLM真的是交叉熵loss吗? 交叉熵loss其实有点奇怪,一个loss从理论上到论文里实际落地的过程中,一般是先写出模型,明白模型在做什么,然后理论上推导loss的期望形式,最后在实际落地的时候,loss的样本期望又被用样本平均近似,但是仔细推导一下交叉熵loss的这个过程,会觉得比较奇怪. 因为如果直接把交叉熵当作loss,会发现写出样本期望并不是很直观.
我们尝试按照刚才的流程,写模型的优化目标:
假设文本序列来自真实数据分布 \(p_{\text{data}}(x_{1:T})\)。其中,\(x_{1:T}\) 表示一段长度为 \(T\) 的 token 序列,\(x_{<t}\) 表示第 \(t\) 个 token 之前的所有上下文,模型预测分布是 \(q_\theta(x_t \mid x_{<t})\)。
如果进一步展开到“给定上下文后预测下一个 token”的条件分布,然后求CE Loss,整个模型的优化目标可以写成:
(输入的样本是 \( x_{<t} \) 随机变量序列)
这里的 \(p_{\text{data}}(\cdot \mid x_{<t})\) 表示真实数据中“给定上下文 \(x_{<t}\) 后,下一个 token 的条件分布”,\(q_\theta(\cdot \mid x_{<t})\) 表示模型预测的条件分布。 里面的交叉熵实际是一个条件交叉熵.这时候最好把交叉熵协程期望的形式,在写成条件期望的形式,也就是:
把里面的交叉熵继续写成离散形式,就是:
其中,\(\mathcal{V}\) 表示词表。这个求和是在所有可能的 next token 上求和。
但真实的数据分布(next token的分布,即y的分布)我们并不知道,也不可能真的对所有上下文和所有 next token 做完整期望。训练时,我们只有数据集里的有限样本。所以实际训练会用样本平均来近似这个期望。
这就是为什么CE损失函数的绕人的地方,是因为他做了两次样本期望的近似,一次是Batch 中的多条序列样本的期望,另一次是每条序列中next token的样本的期望.所以看起来好像是“期望套期望“.这确实不trival.
具体来说假设一个 batch 中有 \(B\) 条样本,每条样本有 \(L\) 个预测位置,第 \(b\) 条样本第 \(t\) 个位置的真实 next token 是 \(y_{b,t}\),上下文是 \(x_{b,<t}\),那么离散化后的训练 loss 可以写成:
如果把 batch 里的所有有效 token 位置都重新编号为 \(n=1,\cdots,N\),也可以写成更紧凑的形式:
其中,\(N\) 表示参与统计的有效 token 数量,\(c^{(n)}\) 表示第 \(n\) 个训练位置对应的上下文,\(y^{(n)}\) 表示这个位置对应的真实 next token。
另一点更绕的是,从期望形式写出两层Loss时,里面的条件期望并不是上面那种给定 \(x_{<t} \) 后的条件期望, 序列本身也变成了随机变量,更准确的写法是\(X_{<t} \),即这个期望是\(X_{<t} \) 这个随机变量序列的函数:
那么Loss就变成了
这并不是多此一举,只有这样才能使用全期望公式把外层的期望和内层的期望合成一个期望: \[ E[X] = E[E[X|Y]] \\ E[X|Y] = E[E[X|Y,Z]|Y] \\ \]
这里的两个下下标实际暗示进行了两次采样,一次对序列,来自batch,构造context,一次在序列中对nexttoken
返璞归真
很多时候自回归语言模型的理论训练目标可以写成,下面这个简单形式,它的下标只表示了对不同的序列Batch进行了采样,实际来自已经样本化的CE loss.这个式子并不向它表面那么trival:
这个公式的意思是:从真实数据分布中采样一段文本,然后让模型在每个位置都预测当前 token,并把所有位置的负对数概率加起来。训练的目标就是让这个期望尽可能小。
但是如果我们忽略掉之前所有的推导,尤其是CE的部分,我们会发现,实际我们模型建模的是整个序列的联合分布,即 \[ p_\theta(x_{1:T}) = \prod_{t=1}^{T} q_\theta(x_t \mid x_{<t}) \] 我们的样本是一系列序列,所以优化目标实际应该写成:
如果要最大化这个目标函数,可以等效于最小化\(-\log p_\theta(x_{1:T})\),也就是:
正好就是我们之前写的那个公式。也就是说,虽然我们在推导过程中引入了交叉熵、条件分布、期望等概念,但最终的训练目标其实就是最大化模型对真实数据序列的联合概率。这个视角比使用交叉熵清晰的多得多得多,也许代码里使用交叉熵损失函数,只是这个api适合通过token index选择对应的概率,这功能恰巧和交叉熵损失函数一致了。
但这确实是两个完全不同的视角,前者是从“分布差异”的角度出发,强调模型预测分布和真实分布之间的关系;后者是从“概率最大化”的角度出发,强调模型对真实数据的拟合程度 虽然它们最终等价,但前者更适合理解为什么使用交叉熵损失,而后者更适合理解模型的最终优化目标。
- 分布拟合视角(Cross‑Entropy / KL)
- 最大似然视角(Maximize joint probability)
更深层的角度 📌 最大似然、KL 散度与交叉熵的统一视角
在统计学中有一个非常重要的普适定理:
这并不是语言模型特有的性质,而是所有概率模型都成立的基本等价关系。
KL 散度与最大似然的等价性
对任意真实分布 \(p_{\text{data}}\) 和模型分布 \(p_\theta\),KL 散度定义为:
注意到:
- 第一项 \(\mathbb{E}[\log p_{\text{data}}(x)]\) 与模型参数 \(\theta\) 无关
- 因此优化 KL 散度只影响第二项
于是:
右侧正是最大似然(MLE)的目标函数。
结论
最小化 KL(p‖q) 与最大化模型似然完全等价。
这条等价关系在所有概率模型中成立,不限于语言模型。
Q5: loss_mask 在 loss 里起什么作用?
训练时并不是所有位置都应该参与 loss。比如 padding token 只是为了把不同长度的样本补齐到同一个长度,它不应该影响模型训练。
MiniMind 里先让 CrossEntropyLoss(reduction='none') 返回每个位置的 loss,然后再用 loss_mask 过滤:
# src/minimind_learning/trainer/train_pretrain.py
loss = loss_fct(
res.logits.view(-1, res.logits.size(-1)),
Y.view(-1)
).view(Y.size())
# loss 和 loss_mask 的shape都是 [batch_size, seq_len]
loss = (loss * loss_mask).sum() / loss_mask.sum()
这里 loss_mask 中为 1 的位置参与损失计算,为 0 的位置被忽略。最后除以 loss_mask.sum(),表示只对有效 token 的 loss 取平均。
用公式写出来,假设 \(m_t\) 表示第 \(t\) 个位置的 mask,\(m_t = 1\) 表示参与训练,\(m_t = 0\) 表示忽略,那么最终 loss 是:
\[ \mathcal{L}=\frac{\sum_{t=1}^{T}m_t \ell_t}{\sum_{t=1}^{T}m_t} \]
其中,\(\ell_t\) 表示第 \(t\) 个位置的交叉熵损失。
这也是为什么 loss_mask 看起来只是一个工程细节,但实际上它决定了哪些 token 真正参与了模型学习。
优化器、学习率和数据设置
这一节我们进入训练中更偏实践的部分,即训练的优化器和数据部分.这部分非常重要,直接决定了模型能否稳定训练,大模型的训练不是简单的“用个 Adam 就行了”,而是需要对优化器、学习率调度、数据设置等多个方面进行细致调整和理解.才可以保证训练的稳定性. 这一节实际上有很多相关的问题:
- 优化器本身,各种优化器的原理和性质?
- 优化过程中的参数和细节: 学习率、权重初始化、weight decay、warmup,等等,很多这些参数还是变化的.
- 数据的重要性,从数据集如何构建,到训练过程中batch size、epoch,这些数据相关参数的设置.
- 数据视角更进一步的 scaling law,数据量和模型规模的关系,数据质量相关的内容.
这些问题看起来分散,但它们都是决定训练过程是否成功的重要环节.
这一节按照如下顺序组织:
- Warmup、学习率调度、权重初始化、weight decay 这些训练技巧分别在解决什么问题?
- Adam 和 AdamW 优化器到底是什么?为什么 MiniMind 里用 AdamW?
- Lion、Muon 这类新型优化器大概是什么方向?
- Pretrain 数据集需要注意什么?数据质量、数据分布和 scaling law 为什么重要?
- Batch size、epoch、tokens seen 这些概念应该怎么理解?
Q1: 基本的优化模型?
模型训练的最基本更新形式是:
\[ \theta_{t+1}=\theta_t-\eta \nabla_\theta \mathcal{L}(\theta_t) \]
其中,\(\theta_t\) 是第 \(t\) 步的模型参数,\(\eta\) 是学习率,\(\nabla_\theta \mathcal{L}(\theta_t)\) 是 loss 对参数的梯度。
这个公式看起来很简单,但实际训练中会马上遇到很多问题:
- 参数一开始应该怎么初始化?
- 训练刚开始时梯度不稳定怎么办?
- 学习率应该一直不变,还是随着训练变化?
- 参数会不会变得太大?
- 梯度更新要不要考虑历史方向和历史尺度?
- 一个 batch 里应该放多少数据?
- 数据集本身是否足够大、足够干净、分布是否合理?
正如开头所说的,这些因素大致可以被归结为
- 优化训练方面: 如使用什么优化器? Warmup、学习率调度、weight decay、AdamW,数据视角的 batch size、epoch
- 数据层面: 基本的数据集分布
对于后续的问题,我们也会按照训练的流程来组织,从最开始Warmup和权重初始化开始.
Q2: 权重初始化为什么会影响训练?
权重初始化不是“随便随机一下”。它会影响前向传播时激活值的尺度,也会影响反向传播时梯度的尺度。
如果初始化太大,激活值和梯度可能迅速变大,训练容易不稳定。
如果初始化太小,信号在层与层之间传播时可能变得很弱,模型学习速度会变慢。
经典初始化方法,比如 Xavier initialization 和 Kaiming initialization,本质上都是在尝试维持不同层之间的方差稳定。
先看最简单的一类:小方差正态初始化。它会让权重从一个均值为 0、标准差较小的正态分布中采样:
\[ W_{ij}\sim \mathcal{N}(0,\sigma^2) \]
其中,\(W_{ij}\) 表示权重矩阵中的一个元素,\(\sigma\) 是初始化标准差。很多 Transformer 实现会使用类似 \(\sigma=0.02\) 的小标准差初始化。它的直觉很简单:让模型一开始不要输出过大的激活值,避免训练刚开始就数值不稳定。
另一类是 Xavier initialization,也叫 Glorot initialization。它主要希望前向传播和反向传播中的方差都尽量保持稳定。设某一层输入维度为 \(d_{\text{in}}\),输出维度为 \(d_{\text{out}}\),则 Xavier uniform 常写成:
\[ W_{ij}\sim U\left(-\sqrt{\frac{6}{d_{\text{in}}+d_{\text{out}}}},\sqrt{\frac{6}{d_{\text{in}}+d_{\text{out}}}}\right) \]
对应的 Xavier normal 可以写成:
\[ W_{ij}\sim \mathcal{N}\left(0,\frac{2}{d_{\text{in}}+d_{\text{out}}}\right) \]
其中,\(U(a,b)\) 表示在区间 \([a,b]\) 上均匀采样。Xavier 初始化常用于 tanh、sigmoid 或较早期的全连接网络设置,它的核心目标是让信号在层与层之间传播时不要快速放大或缩小。
再看 Kaiming initialization,也叫 He initialization。它主要是为 ReLU 这类激活函数设计的。因为 ReLU 会把一部分负值截断为 0,所以需要稍微调整方差。Kaiming normal 常写成:
\[ W_{ij}\sim \mathcal{N}\left(0,\frac{2}{d_{\text{in}}}\right) \]
对应的 Kaiming uniform 可以写成:
\[ W_{ij}\sim U\left(-\sqrt{\frac{6}{d_{\text{in}}}},\sqrt{\frac{6}{d_{\text{in}}}}\right) \]
它的直觉是:在使用 ReLU 类激活函数时,仍然尽量保持每一层输出的方差稳定。
需要注意的是,上面这些初始化方法并不是“所有参数都这样初始化”。它们主要针对带权重矩阵的可学习层,最典型的是线性层 Linear,也包括卷积层 Conv 这类本质上也是线性变换的层。
在 LLM 里,情况会更复杂一些。Transformer 里大量使用残差连接、LayerNorm、Attention 和 MLP,很多初始化策略还会考虑模型深度。例如有些实现会对残差分支相关参数使用更小的初始化尺度,避免很多层残差叠加后激活值过大。
更具体地说:
- Xavier / Glorot 初始化主要适合
tanh、sigmoid 或比较对称的激活函数场景。它同时考虑fan_in和fan_out,希望前向传播和反向传播的方差都比较稳定。 - Kaiming / He 初始化主要适合 ReLU、LeakyReLU、GELU 这类会改变激活分布的非线性函数。它最初是为 ReLU 设计的,更强调根据
fan_in保持前向激活方差稳定。 - 小方差正态初始化在 Transformer / LLM 里很常见,常用于 embedding、attention projection、MLP projection 等参数。它不一定严格绑定某个激活函数,而是作为一种经验上稳定的初始化尺度。
但有些参数的初始化规则不同:
- bias 通常初始化为 0。
- LayerNorm 的 scale / weight 通常初始化为 1,bias 初始化为 0。
- embedding 矩阵通常也会用正态分布初始化,但它的角色和普通线性层不完全一样。
- RoPE 这类位置编码缓存不是可训练参数,一般不涉及权重初始化。
所以,初始化方法需要结合“参数属于哪一类层”和“后面接什么激活函数”一起理解。对于 Transformer 来说,还要额外考虑这个参数是否处在 attention、MLP、embedding、output head 或残差分支中。
这部分在 MiniMind 的训练脚本里不显眼,因为模型初始化通常封装在模型定义里。但从训练角度看,初始化决定了优化开始时的位置。一个好的初始化不保证模型训练成功,但一个不合适的初始化很容易让训练一开始就出问题。
Q2.1: 为什么不用全 0 初始化?
关于小方差初始化,一个很自然的问题是,如果方差已经很小了,为什么不直接初始化为全 0 呢?
两者还是有关键区别的,如果把所有权重都初始化为 0,会出现一个严重问题:对称性无法打破。
假设一层里有多个神经元,第 \(i\) 个神经元可以写成:
\[ h_i=f(W_i x+b_i) \]
其中,\(W_i\) 是第 \(i\) 个神经元对应的权重,\(b_i\) 是 bias,\(f\) 是激活函数。
如果所有 \(W_i\) 都是 0,所有 \(b_i\) 也一样,那么这些神经元一开始的输出完全一样。反向传播时,它们收到的梯度也会完全一样,于是更新后仍然一样。
也就是说,这一层里虽然有很多神经元,但它们行为上像是同一个神经元的复制品,模型容量被浪费了。
小方差随机初始化则不同:
\[ W_{ij}\sim \mathcal{N}(0,\sigma^2) \]
它的均值仍然是 0,但每个权重会有一点点随机差异。这样不同神经元一开始就不完全一样,反向传播时收到的梯度也会逐渐不同,模型才能学到不同特征。
所以小方差初始化是在折中:
- 随机:打破对称性。
- 均值接近 0:避免整体偏移。
- 方差较小:避免一开始数值爆炸。
bias 倒是经常可以初始化为 0,因为只要权重已经随机了,神经元之间就已经被区分开了。
Q3: Warmup 是什么? 为什么训练初期需要它?
Warmup 指的是:训练刚开始时,不直接使用目标学习率,而是先从一个很小的学习率逐步升高到目标学习率。
第一种最常见的方法是从 0 线性升高到目标学习率。假设目标学习率是 \(\eta_{\max}\),warmup 总步数是 \(T_{\text{warmup}}\),那么第 \(t\) 步的学习率可以写成:
\[ \eta_t=\eta_{\max}\cdot \frac{t}{T_{\text{warmup}}} \]
其中,\(0 \le t \le T_{\text{warmup}}\)。当 \(t=0\) 时,学习率是 0;当 \(t=T_{\text{warmup}}\) 时,学习率升到 \(\eta_{\max}\)。
类似的方法是从一个较小的起始学习率升高到目标学习率。有时我们不希望学习率真的从 0 开始,而是从 \(\eta_{\min}\) 开始逐步升高到 \(\eta_{\max}\)。这时可以写成:
\[ \eta_t=\eta_{\min}+(\eta_{\max}-\eta_{\min})\cdot\frac{t}{T_{\text{warmup}}} \]
其中,\(\eta_{\min}\) 表示 warmup 起始学习率,\(\eta_{\max}\) 表示 warmup 结束后达到的目标学习率。这个形式比从 0 开始更一般:当 \(\eta_{\min}=0\) 时,它就退化成第一种线性 warmup。
实际训练里,warmup 后面通常会接一个学习率衰减策略,比如 cosine decay。于是完整学习率调度会变成两段:前面先 warmup,后面再 decay。
为什么需要它?因为训练刚开始时,模型参数还很随机,激活值和梯度的尺度也可能不稳定。如果一开始就用较大的学习率,参数更新可能过猛,导致 loss 剧烈震荡,甚至直接出现 NaN。
Warmup 相当于给训练一个缓冲期:先小步走,等模型进入相对稳定的区域后,再使用正常学习率。
MiniMind 当前的 pretrain 脚本没有单独实现 warmup,但大模型训练里 warmup 非常常见。是否需要 warmup,通常和模型规模、batch size、初始化方式、优化器和学习率大小有关。
Q4: Learning Rate 调整? Cosine Decay 在做什么?
Learning rate 决定每一步参数更新走多远。我们之前已经提到了Warmup,它是训练初期的一个缓冲机制。Warmup 之后,通常还需要一个学习率衰减策略,让学习率随着训练进度逐渐降低。
如果学习率太大,参数更新可能越过较好的区域,导致 loss 震荡甚至发散。
如果学习率太小,训练虽然稳定,但下降太慢,在有限训练时间内学不到足够的东西。
因此,学习率通常不会固定不变,而是随着训练进度调整。MiniMind 使用的是一个简单的 cosine decay:
# src/minimind_learning/trainer/trainer_utils.py
def get_lr(current_step, total_steps, lr):
return lr / 10 + 0.5 * lr * (1 + math.cos(math.pi * current_step / total_steps))
训练循环中,每一步都会重新设置 optimizer 的学习率:
# src/minimind_learning/trainer/train_pretrain.py
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
用公式写出来,MiniMind 这里的学习率大致是:
\[ \eta_t=\frac{\eta_0}{10}+\frac{1}{2}\eta_0\left(1+\cos\left(\pi\frac{t}{T}\right)\right) \]
其中,\(\eta_t\) 是第 \(t\) 步学习率,\(\eta_0\) 是初始学习率,\(T\) 是总训练步数。
这个公式的直觉是:训练前期学习率较高,帮助模型快速学习;训练后期学习率逐渐降低,让参数更新变得更细。
这里还有一个小细节:MiniMind 这个实现不是从 \(\eta_0\) 严格衰减到 0,而是从大约 \(1.1\eta_0\) 衰减到 \(0.1\eta_0\)。这不影响理解它作为 cosine schedule 的作用,但读代码时需要注意。
Q4.1: 还有哪些常见的学习率调整方式?
学习率调整方式很多,本质上都是在回答同一个问题:训练不同阶段应该用多大的步长更新参数。
1. Constant learning rate
最简单的方法是不调整学习率,整个训练过程都使用同一个值:
\[ \eta_t=\eta_0 \]
这种方式简单,但对于大模型 pretrain 往往不够灵活。训练初期可能需要 warmup,训练后期通常也希望学习率逐渐下降。
PyTorch 中如果不设置 scheduler,其实就是这种形式:
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)
2. Step decay
Step decay 会每隔固定步数把学习率乘上一个系数:
\[ \eta_t=\eta_0\cdot \gamma^{\left\lfloor t/S \right\rfloor} \]
其中,\(S\) 是衰减间隔,\(\gamma\) 是衰减系数。
scheduler = torch.optim.lr_scheduler.StepLR(
optimizer,
step_size=1000,
gamma=0.1,
)
它的特点是学习率呈阶梯状下降,简单直接,但下降点会比较突兀。
3. Exponential decay
Exponential decay 会让学习率按指数形式连续下降:
\[ \eta_t=\eta_0\cdot \gamma^t \]
其中,\(0<\gamma<1\)。
scheduler = torch.optim.lr_scheduler.ExponentialLR(
optimizer,
gamma=0.99,
)
这种方式比 step decay 更平滑,但如果 \(\gamma\) 设置不合适,学习率可能下降得太快或太慢。
4. Linear decay
Linear decay 会让学习率从初始值线性下降到某个最小值。假设总训练步数为 \(T\),最终学习率为 \(\eta_{\min}\),可以写成:
\[ \eta_t=\eta_{\min}+(\eta_0-\eta_{\min})\left(1-\frac{t}{T}\right) \]
def linear_decay_lr(step, total_steps, lr0, lr_min=0.0):
ratio = min(step / total_steps, 1.0)
return lr_min + (lr0 - lr_min) * (1.0 - ratio)
很多训练设置会使用 warmup + linear decay,也就是前面升高,后面线性下降。
5. Cosine decay
Cosine decay 使用余弦曲线让学习率平滑下降:
\[ \eta_t=\eta_{\min}+\frac{1}{2}(\eta_0-\eta_{\min})\left(1+\cos\left(\pi\frac{t}{T}\right)\right) \]
PyTorch 里可以直接使用:
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=total_steps,
eta_min=1e-5,
)
它的优点是下降平滑,训练后期会自然变成小步更新,所以在 Transformer 和 LLM 训练中很常见。
6. Warmup + decay
实际大模型训练里,常见的不是单独一种 decay,而是 warmup 和 decay 组合:
\[ \eta_t= \begin{cases} \eta_{\max}\cdot \frac{t}{T_{\text{warmup}}}, & t<T_{\text{warmup}} \\ \eta_{\text{decay}}(t), & t\ge T_{\text{warmup}} \end{cases} \]
其中,\(\eta_{\text{decay}}(t)\) 可以是 linear decay、cosine decay 或其他衰减函数。
一个简单的 warmup + cosine decay 代码可以写成:
import math
def warmup_cosine_lr(step, total_steps, warmup_steps, lr_max, lr_min=0.0):
if step < warmup_steps:
return lr_max * step / warmup_steps
progress = (step - warmup_steps) / (total_steps - warmup_steps)
progress = min(max(progress, 0.0), 1.0)
return lr_min + 0.5 * (lr_max - lr_min) * (1 + math.cos(math.pi * progress))
这个形式很接近许多大模型训练里常用的学习率 schedule。
7. ReduceLROnPlateau
还有一类方法不是按固定 step 变化,而是根据验证集指标变化来调整学习率。如果 validation loss 长时间不下降,就降低学习率:
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode="min",
factor=0.5,
patience=3,
)
# 每次验证后调用
scheduler.step(val_loss)
这种方式在传统深度学习任务中很常见。不过在大规模 pretrain 里,训练通常更依赖预先设计好的 schedule,因为验证成本高,训练步数也非常大。
Q4.2: 如何判断学习率是否合适?
这是一个很玄学的事情,并且这应该归结到Eval章节,但我还是决定在这里先提一下.后续再更多的展开.
最直接的观察对象仍然是 loss 曲线,但 loss 曲线只能给信号,不能单独证明某个学习率是最优的。
如果学习率太大,常见现象是:
- loss 一开始不下降,或者下降一点后剧烈震荡。
- loss 曲线有很多尖峰,甚至越来越高。
- 出现
NaN/Inf。 - 同样配置多跑几次,训练差异很大。
- 如果记录了 grad norm,通常会看到明显尖峰。
直觉上,这是因为每一步迈得太大,参数更新越过了比较好的区域,甚至破坏了已经形成的结构。
如果学习率太小,常见现象是:
- loss 很稳定,但下降非常慢。
- 曲线长时间几乎没有明显改善。
- 训练看起来很安全,但单位时间或单位 token 的学习效率很低。
- 提大学习率后,如果 loss 仍然稳定下降且下降更快,通常说明原来的学习率偏小。
比较合适的学习率通常表现为:warmup 后 loss 能比较快地下行,曲线允许有 batch-level 抖动,但整体趋势稳定下降;没有频繁的大尖峰,更不会出现 NaN。
一个常用的低成本方法是 LR range test。它不是严格控制变量实验,而是一个预实验,用来粗略测试当前训练系统能承受多大的学习率。
具体做法是:
- 从一个很小的学习率开始,比如 \(10^{-7}\) 或 \(10^{-6}\)。
- 每个 step 或每几个 step,把学习率按指数方式增大。
- 记录每一步的 smoothed loss。
- 一旦 loss 明显发散、剧烈震荡或出现 NaN,就停止。
- 选择 loss 开始快速下降之后、明显发散之前的一段作为候选学习率区间。
指数增长可以写成:
\[ \eta_t=\eta_{\min}\left(\frac{\eta_{\max}}{\eta_{\min}}\right)^{t/T} \]
其中,\(\eta_{\min}\) 是起始学习率,\(\eta_{\max}\) 是测试上限,\(T\) 是测试总步数。
为什么说它不是严格实验?因为模型每一步都在更新,所以不同学习率对应的 loss 并不是在同一个模型状态下测出来的。严格来说,如果要控制变量,应该从同一个 checkpoint 出发,同时用多个学习率分别训练一小段再比较。但这样资源消耗会高很多。
所以实际做法通常是折中:
- 先用 LR range test 快速排除明显不合适的学习率。
- 再从同一个 checkpoint 开 2 到 4 个短跑实验,分别用几个候选学习率训练几百到几千 step。
- 最后选择曲线更稳、下降更快、没有发散迹象的学习率。
因此,LR range test 更准确的理解是:在正式训练前,先用一小段训练过程扫描学习率,粗略摸清这个模型、数据、batch size、optimizer、混合精度配置下的稳定区间。但是这些参数变化后,学习率区间也会变化.
它主要回答的不是“最优学习率是多少”,而是:
- 学习率太小时,loss 是不是几乎不动?
- 学习率进入哪个区间后,loss 开始明显下降?
- 学习率大到什么程度后,loss 开始震荡、上升或 NaN?
- 正式训练的初始学习率应该避开哪些明显危险区域?
Q5: Adam 和 AdamW 优化器是什么? 它们是如何被构造出来的?
Q5.1: GD 族优化器
在介绍 Adam 之前,可以先从最基础的 SGD 看起。
SGD 全称是 Stochastic Gradient Descent,也就是随机梯度下降。它的基本形式是:
\[ \theta_{t+1}=\theta_t-\eta g_t \]
其中,\(\theta_t\) 是第 \(t\) 步的参数,\(\eta\) 是学习率,\(g_t=\nabla_\theta \mathcal{L}_t(\theta_t)\) 是当前 mini-batch 上估计出来的梯度。
需要注意, 深度学习语境下的 SGD 实际上通常指的是 mini-batch SGD. 其本质都是使用不同的样本数来估计梯度的期望.在优化算法里,本质上都是 Gradient Descent(梯度下降)的一族变种:
| 名称 | 含义 | 和 SGD 的关系 |
|---|---|---|
| Batch(全量批次) | 用整个训练集计算一次梯度 | 对应 Batch Gradient Descent |
| Mini‑batch(小批量) | 用训练集的一小部分(如 32、64)计算梯度 | 对应 Mini‑batch SGD(现代默认) |
| SGD(随机梯度下降) | 用单个样本计算梯度 | 对应 Stochastic Gradient Descent |
SGD 的特点是简单直接:当前 batch 给出一个梯度,就沿着负梯度方向走一步。但它也有两个问题:
- 当前 batch 的梯度可能噪声很大,更新方向会抖动。
- 所有参数使用同一个学习率,不会根据不同参数的梯度尺度自适应调整。
为了缓解第一个问题,可以加入 momentum。Momentum SGD 会维护一个速度项 \(v_t\):
\[ v_t=\mu v_{t-1}+g_t \]
\[ \theta_{t+1}=\theta_t-\eta v_t \]
其中,\(\mu\) 是 momentum 系数。直觉上,momentum 会累积过去梯度的方向,让更新方向更平滑,减少 batch 噪声带来的来回震荡。
Q5.2: Adam
Adam 可以看成是在 Momentum SGD 的方向上继续发展:它不只关心梯度方向的滑动平均,还关心梯度平方的滑动平均。也就是说,SGD 主要看当前梯度,Momentum SGD 看历史梯度方向,而 Adam 同时维护梯度的一阶矩和二阶矩。
Adam 的全称是 Adaptive Moment Estimation。它对每个参数都维护两类状态:
- 一阶矩 \(m_t\):梯度的指数滑动平均,可以理解为“带 momentum 的梯度方向”。
- 二阶矩 \(v_t\):梯度平方的指数滑动平均,可以理解为“梯度尺度”的估计。
初始化时通常令:
\[ m_0=0,\quad v_0=0 \]
假设第 \(t\) 步梯度是:
Adam 会先更新一阶矩和二阶矩:
\[ m_t=\beta_1m_{t-1}+(1-\beta_1)g_t \]
\[ v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2 \]
其中,\(\beta_1\) 和 \(\beta_2\) 控制历史信息保留多少。常见默认值是 \(\beta_1=0.9\),\(\beta_2=0.999\)。(看起来是个线性插值/平滑滤波)
因为 \(m_0\) 和 \(v_0\) 都初始化为 0,所以训练初期的 \(m_t\)、\(v_t\) 会偏向 0。Adam 会使用 bias correction 修正这个偏差:
\[ \hat{m}_t=\frac{m_t}{1-\beta_1^t} \]
\[ \hat{v}_t=\frac{v_t}{1-\beta_2^t} \]
然后用修正后的一阶矩和二阶矩更新参数:
\[ \theta_t=\theta_{t-1}-\eta\frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon} \]
其中,\(\eta\) 是学习率,\(\epsilon\) 是一个很小的常数,通常类似 \(10^{-8}\),用于避免除以 0。
这个更新式的直觉是:
- \(\hat{m}_t\) 决定主要更新方向。
- \(\sqrt{\hat{v}_t}\) 根据历史梯度尺度对更新做归一化。
- 梯度长期较大的参数,更新会被缩小。
- 梯度长期较小的参数,更新相对不会被压得太厉害。
所以 Adam 会根据每个参数自己的梯度历史,自适应地调整更新尺度。梯度波动大的参数,更新会更谨慎;梯度相对稳定的参数,更新会更顺滑。
Adam 也有一些需要注意的点:
- Adam 的状态开销比 SGD 大,因为每个参数都要额外保存 \(m_t\) 和 \(v_t\)。
- Adam 对学习率仍然敏感,不是用了 Adam 就不需要调学习率。
- Adam 里的 \(\epsilon\)、\(\beta_1\)、\(\beta_2\) 通常使用默认值,但在极大 batch、混合精度或特殊任务里也可能需要调整。
- 如果直接把 L2 regularization 加进 Adam 的梯度里,它会和自适应缩放混在一起,这也是 AdamW 要解决的问题。
Q5.2.1: \(v_t\) 是严格意义上的二阶矩吗?
这个问题很关键,它揭示了Adam本质上还是一阶优化算法,而不是严格意义上的二阶优化算法(没有使用二阶Hessian矩阵).
严格说,Adam 里的 \(v_t\) 不是完整意义上的二阶矩矩阵,也不是协方差矩阵。它更准确地说是逐元素梯度平方的指数滑动平均,也就是对每个参数维度的 second raw moment estimate。
如果参数 \(\theta\) 的形状是:
\[ \theta \in \mathbb{R}^{d} \]
那么梯度 \(g_t\)、一阶矩 \(m_t\)、二阶矩估计 \(v_t\) 的 shape 都和参数一样:
\[ g_t,m_t,v_t \in \mathbb{R}^{d} \]
Adam 中的二阶矩更新是逐元素的:
\[ v_t=\beta_2v_{t-1}+(1-\beta_2)(g_t\odot g_t) \]
其中,\(\odot\) 表示逐元素乘法。
所以它不是下面这种完整矩阵:
\[ g_tg_t^\top \]
完整二阶矩矩阵或协方差矩阵会包含不同参数维度之间的相关性,计算和存储代价都非常高。Adam 只保留每个参数位置自己的梯度平方历史,所以它更像是一种对角近似:估计每个参数维度自己的梯度尺度,但不建模不同参数维度之间的相关性。
Q5.3: AdamW
AdamW 可以理解为 Adam 加上 decoupled weight decay,也就是把 weight decay 从 Adam 的梯度自适应更新中解耦出来。
先看普通 Adam 如果加入 L2 regularization,常见做法是把正则项加进 loss:
这样梯度会变成:
如果把 \(g’t\) 送进 Adam,那么 \(\lambda\theta{t-1}\) 也会进入一阶矩、二阶矩,并被 Adam 的自适应缩放处理。这样 weight decay 的效果会和参数自己的梯度尺度纠缠在一起。
AdamW 的做法是:Adam 的自适应梯度更新仍然只根据 \(g_t\) 计算,然后在参数更新时单独加上 weight decay。
AdamW 的状态初始化和 Adam 一样:
\[ m_0=0,\quad v_0=0 \]
先计算梯度:
再按 Adam 的方式更新一阶矩、二阶矩和 bias correction:
\[ m_t=\beta_1m_{t-1}+(1-\beta_1)g_t \]
\[ v_t=\beta_2v_{t-1}+(1-\beta_2)g_t^2 \]
\[ \hat{m}_t=\frac{m_t}{1-\beta_1^t},\quad \hat{v}_t=\frac{v_t}{1-\beta_2^t} \]
最后更新参数时,把 Adam 更新和 weight decay 分开:
也可以写成:
这里 \(\lambda\) 是 weight decay 系数。
这就是 AdamW 里 decoupled weight decay 的含义:参数衰减不再作为梯度的一部分进入 Adam 的自适应矩估计,而是在最后更新参数时单独作用。
MiniMind 的 pretrain 代码里使用的是 AdamW:
# src/minimind_learning/trainer/train_pretrain.py
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
在 Transformer / LLM 训练里,AdamW 是非常常见的默认选择。不过使用 AdamW 时也要注意:
- learning rate 仍然需要调,AdamW 不是免调参优化器。
- weight decay 通常不会施加到所有参数上。很多训练设置会排除 bias、LayerNorm weight、embedding 等参数。
- weight decay 和 learning rate 会共同决定参数衰减强度,因为衰减项里有 \(\eta\lambda\)。
- AdamW 的状态开销仍然较大,因为它和 Adam 一样要保存 \(m_t\) 和 \(v_t\)。
Q6: Weight Decay 是什么?
有一个很容易和 Learning Rate Decay 混淆的概念叫 Weight Decay。它们虽然名字里都有 decay,但其实是两个完全不同的东西。Weight decay 来自 L2 正则项:
\[ \mathcal{L}’(\theta)=\mathcal{L}(\theta)+\frac{\lambda}{2}|\theta|^2 \]
其中,\(\lambda\) 是正则强度,也就是 weight decay 系数。
对这个新的 loss 求梯度,可以得到:
\[ \nabla_\theta \mathcal{L}’(\theta)=\nabla_\theta \mathcal{L}(\theta)+\lambda\theta \]
如果记 \(g_t=\nabla_\theta \mathcal{L}(\theta_t)\),那么在 SGD 中更新就是:
\[ \theta_{t+1}=\theta_t-\eta(g_t+\lambda\theta_t) \]
展开后:
\[ \theta_{t+1}=\theta_t-\eta g_t-\eta\lambda\theta_t \]
也可以写成:
\[ \theta_{t+1}=(1-\eta\lambda)\theta_t-\eta g_t \]
这里的 \(-\eta\lambda\theta_t\) 就是 weight decay 项。它的作用是每一步都把参数按比例往 0 的方向拉一点,避免参数规模无限变大。
所以在普通 SGD 中,可以说 L2 正则和 weight decay 是等价的:L2 正则项的梯度自然产生了参数衰减项。
但是在 Adam 中,情况会变得更微妙。因为 Adam 会把梯度送进一阶矩 \(m_t\) 和二阶矩估计 \(v_t\),并做自适应缩放。如果直接把 L2 正则项加到 loss 里,那么 \(\lambda\theta_t\) 也会进入 Adam 的自适应缩放过程。这样一来,参数衰减就不再是简单的“按比例往 0 拉”,而是会受到每个参数历史梯度尺度的影响。
AdamW 的意义就是把这件事解耦:Adam 仍然只根据原始 loss 的梯度 \(g_t\) 计算自适应更新,而 weight decay 在最后参数更新时单独作用:
也就是把“根据梯度更新参数”和“按比例衰减参数”分开处理。
关于 \(\lambda\) 是否变化,通常来说 weight decay 系数本身是固定超参数。常见取值可能是 0.01、0.1 这一类,具体要看模型规模、数据量、训练步数和是否对某些参数排除 weight decay。
不过要注意,实际每一步的衰减强度里还有学习率 \(\eta_t\):
\[ -\eta_t\lambda\theta_t \]
所以即使 \(\lambda\) 固定,只要 learning rate schedule 在变化,实际每一步的参数衰减幅度也会跟着变化。
在 Transformer / LLM 训练里,还常常不会对所有参数都使用 weight decay。比如 bias、LayerNorm 的 weight、某些 embedding 参数,可能会被排除在 weight decay 之外。这样做的原因是这些参数本身的尺度意义和普通线性层权重不完全一样,直接衰减未必总是有益。
Q7: Lion 和 Muon 这类新型优化器是什么?
AdamW 很常见,但它不是优化器发展的终点。近年来也出现了一些针对深度网络和大模型训练的新优化器,比如 Lion 和 Muon。
7.1 Lion
Lion 来自论文 Symbolic Discovery of Optimization Algorithms。它的名字是 EvoLved Sign Momentum。
和 Adam 相比,Lion 更轻量。Adam 通常需要保存一阶矩和二阶矩两个状态,而 Lion 主要保存 momentum,因此内存开销更小。Lion 的更新还使用了 sign operation,也就是参数更新方向更像是由符号决定,而不是直接使用连续梯度值。
Lion 的状态初始化通常是:
\[ m_0=0 \]
其中,\(m_t\) 是 momentum 状态,shape 和参数 \(\theta_t\) 一样。
假设第 \(t\) 步梯度是:
Lion 会先用 \(\beta_1\) 构造当前更新方向:
\[ c_t=\beta_1m_{t-1}+(1-\beta_1)g_t \]
然后用 sign update 更新参数。如果带 decoupled weight decay,可以写成:
\[ \theta_t=\theta_{t-1}-\eta\left(\operatorname{sign}(c_t)+\lambda\theta_{t-1}\right) \]
最后再用 \(\beta_2\) 更新 momentum 状态:
\[ m_t=\beta_2m_{t-1}+(1-\beta_2)g_t \]
其中,\(\eta\) 是学习率,\(\lambda\) 是 weight decay 系数。Lion 常见默认 \(\beta\) 设置类似 \((0.9, 0.99)\)。
Lion 和 Adam 的一个重要区别是:Adam 用 \(\sqrt{\hat{v}_t}\) 做逐元素尺度归一化,而 Lion 不维护二阶矩估计。它只保留 momentum,并用 \(\operatorname{sign}(c_t)\) 决定每个参数位置更新的方向。
一个简化理解是:
- AdamW:用一阶矩和二阶矩做自适应更新。
- Lion:用 momentum 加 sign update,状态更少,更新形式更简单。
不过 Lion 不是“无脑替换 AdamW”。因为 sign update 的更新范数通常更大,Lion 往往需要比 AdamW 更小的学习率;为了保持 \(\eta\lambda\) 的衰减强度,weight decay 有时也会相应调大。它在不同任务上的收益并不总是稳定,所以更适合作为了解现代优化器方向的例子。
7.2 Muon
Muon 的主实现来自 KellerJordan/Muon,全称可以理解为 MomentUm Orthogonalized by Newton-Schulz。
Muon 的核心思想是:对神经网络隐藏层中的 2D 权重矩阵,先用 momentum 得到更新方向,再对这个更新矩阵做近似正交化。实现上常用 Newton-Schulz iteration 来高效近似这个操作。
为了避免符号混乱,先把这一节里的符号列出来:
- \(W_t\):第 \(t\) 步的 2D 权重矩阵,也就是 Muon 要优化的参数。
- \(G_t\):第 \(t\) 步的梯度矩阵,shape 和 \(W_t\) 相同。
- \(M_t\):momentum 状态,用来累积历史梯度方向。
- \(U_t\):正交化之前的候选更新矩阵,也就是 update matrix。
- \(O_t\):对 \(U_t\) 做正交化之后得到的更新矩阵。
- \(\mu\):momentum 系数。
- \(\eta\):学习率。
- \(\lambda\):weight decay 系数。
也就是说,Muon 并不是直接用梯度 \(G_t\) 或 momentum \(M_t\) 更新参数,而是先得到候选更新 \(U_t\),再把它正交化为 \(O_t\),最后用 \(O_t\) 更新权重。
对于一个 2D 参数矩阵 \(W_t\),Muon 的 momentum 状态可以初始化为:
\[ M_0=0 \]
假设当前梯度是:
Muon 先做类似 SGD momentum 的更新:
\[ M_t=\mu M_{t-1}+G_t \]
有些实现还会使用 Nesterov 形式:
\[ U_t=\mu M_t+G_t \]
如果不使用 Nesterov,也可以简单理解为:
\[ U_t=M_t \]
接下来,Muon 会对更新矩阵 \(U_t\) 做正交化:
\[ O_t=\operatorname{Ortho}(U_t) \]
理想情况下,如果 \(U_t=A\Sigma B^\top\) 是奇异值分解,那么正交化结果可以理解为:
\[ \operatorname{Ortho}(U_t)=AB^\top \]
也就是说,它保留更新矩阵的“方向结构”,但把奇异值压到接近 1。实际实现中不会真的每一步做完整 SVD,而是使用 Newton-Schulz iteration 近似这个正交化操作。
最后更新参数:
\[ W_t=W_{t-1}-\eta O_t \]
如果带 AdamW-style weight decay,也可以写成:
\[ W_t=W_{t-1}-\eta\left(O_t+\lambda W_{t-1}\right) \]
它的使用方式也和 AdamW 不完全一样。Muon 通常只用于隐藏层里的矩阵参数;embedding、输出层、bias、gain 等参数仍然建议使用 AdamW 之类的标准优化器。
所以 Muon 更像是一种“针对矩阵参数结构的优化器”,而不是简单的通用 AdamW 替代品。它利用了 2D 权重矩阵的结构,而 AdamW / Lion 这类优化器更多是逐元素更新。
对于这类新优化器,我现在更倾向于先把它们当作了解方向:它们说明优化器设计正在从“通用自适应更新”继续往“利用参数结构、减少状态开销、提高训练效率”的方向发展。但在 MiniMind 这种学习项目里,AdamW 仍然是最稳定、最容易理解的选择。
Q8: Pretrain 数据集需要注意什么?
Pretrain 的本质是拟合数据分布。模型学到什么,很大程度上取决于训练数据长什么样。这是一个非常复杂的问题,我们会在后续的章节展开说.但在这里先给出一些直观的要点,和一些实现细节的注意点:
数据集至少要关注几件事:
- 数据质量:低质量文本、乱码、重复模板会直接被模型学进去。
- 数据分布:代码、百科、小说、问答、网页文本的比例不同,模型能力也会偏向不同方向。
- 重复数据:大量重复样本会让模型浪费训练步数,也可能增加记忆风险。
- 数据污染:如果 eval 数据混进训练集,会让评估结果失真。
- 领域覆盖:如果训练数据过窄,模型在其他领域的泛化会比较弱。
MiniMind 的 pretrain dataset 读取 JSONL 文件中的 text 字段:
# src/minimind_learning/dataset/lm_dataset.py
def load_data(self, path):
samples = []
with open(path, 'r', encoding='utf-8') as f:
for line_num, line in enumerate(f, 1):
data = json.loads(line.strip())
samples.append(data)
return samples
随后每条样本会被 tokenizer 编码、截断和 padding:
encoding = self.tokenizer(
str(sample['text']),
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
这意味着 max_seq_len、padding 和 truncation 都会影响模型实际看到的数据。
max_seq_len 不只是显存参数。它决定了单条样本最多保留多少 token,也影响模型能从训练中学习多长范围内的上下文依赖。较短序列训练更快、更省显存,但模型很难从中学习长文本结构;较长序列信息更完整,但训练成本更高。
需要根据模型的能力以及数据集的状态进行权衡,比如数据集缺乏长句子时,过长的 max_seq_len 可能会浪费显存;数据集里有很多长文本时,过短的 max_seq_len 又会丢失重要信息。所以在数据集构造的时候,就需要结合模型能力做考量.
Q8.1: 模型在训练和推理的时候能接受多长的句子?
模型能接受多长的句子,通常受几类因素共同限制:
- 模型结构里的最大位置长度。
- 训练时见过的序列长度。
- attention 计算和显存成本。
- 位置编码或位置嵌入的外推能力。
如果使用传统的 learned absolute position embedding,输入 token embedding 和位置 embedding 通常会相加:
\[ x_t=e_t+p_t \]
其中,\(e_t\) 是第 \(t\) 个 token 的 embedding,\(p_t\) 是第 \(t\) 个位置的位置 embedding。
这时位置 embedding 通常是一张固定大小的表:
\[ P\in\mathbb{R}^{L_{\max}\times d} \]
其中,\(L_{\max}\) 是最大位置长度,\(d\) 是 hidden size。如果训练时设置 \(L_{\max}=1024\),那么这张表只有 1024 个位置。推理时输入超过 1024,就没有对应的 \(p_t\) 可以查。因此这种模型的上下文长度会被 position embedding 表硬限制住。
即使强行扩展这张表,比如随机初始化新的位置 embedding,效果通常也不可靠。因为模型训练时没有学过这些新位置。
后来很多 LLM 使用 RoPE、ALiBi 或其他相对位置编码方式。以 RoPE 为例,它不是查一个固定长度的位置表,而是根据位置 \(t\) 对 query 和 key 做旋转:
\[ \operatorname{RoPE}(x_t,t) \]
理论上,\(t\) 可以继续变大,所以 RoPE 不像 learned absolute embedding 那样被固定表硬卡住。但这不代表模型可以无限使用长上下文。因为模型训练时可能只见过 1024、2048 或 4096 长度的序列,它学到的 attention 行为和长距离依赖方式,主要仍然来自训练长度范围。
所以 RoPE 解决的是“位置编码能不能算到更远”的问题,但没有完全解决“模型会不会用这么远的信息”的问题。
如果一个模型只用 \(1024\) token 的长度训练,那么推理时能到多长要分情况:
- 如果是 learned absolute position embedding,硬限制通常就是 1024。
- 如果是 RoPE / ALiBi,技术上可能能喂超过 1024,但这属于外推,效果不保证。
- 即使推理框架和显存允许更长输入,模型也未必真的能利用远处信息。
所以训练长度、位置编码和推理长度之间不是简单的等号关系。位置编码决定“能不能表示位置”,训练长度决定“模型有没有学过这种长度范围内的行为”,推理资源决定“实际能不能跑得动”。
Q8.2: 支持长上下文的模型一般怎么训练?
支持长上下文的模型,通常不能只靠推理时把长度硬拉长。更常见的做法是让模型在训练中见过足够长的上下文,或者至少经过长上下文继续训练。
常见做法有几类。
第一类是从预训练阶段就使用长序列。比如训练时直接使用 4k、8k、32k token 的 sequence length。这样模型从一开始就能见到长文档结构、长距离依赖和长 attention pattern。
但这样非常贵,因为标准 attention 的计算和显存复杂度大致是:
\[ O(L^2) \]
其中,\(L\) 是序列长度。序列越长,attention 矩阵越大。
第二类是先短上下文预训练,再做长上下文继续训练。这是很常见的路线。先用较短长度训练基础语言能力,比如 2k 或 4k;之后再用更长 sequence length 继续训练,比如 8k、16k 或 32k。
这样做更省,因为很多基础语言能力不一定需要特别长的上下文。长上下文阶段主要补的是:
- 更长距离的位置泛化。
- 长文档结构。
- 跨段落依赖。
- 长上下文检索能力。
- 注意力在长序列里的稳定性。
第三类是使用 RoPE scaling / position interpolation 后继续训练。对于 RoPE 模型,可以通过缩放位置编码,把原来的位置分布映射到更长范围。例如从 4k 扩到 32k。但通常仍然需要继续训练或微调,让模型适应新的位置编码尺度。
换句话说,RoPE scaling 让模型“能算”,长上下文训练让模型“会用”。
长上下文训练还常常配合一些工程和数据策略:
- FlashAttention:降低 attention 显存占用并加速。
- gradient checkpointing:减少训练时保存的激活。
- sequence packing:提高 token 利用率。
- document-level 数据:让训练样本保留真实长文档结构。
- 长文档 QA / retrieval-style 数据:让模型学习使用远处信息。
训练时的显存压力通常比推理更大。因为训练不仅要保存参数,还要保存:
- forward 激活,用于 backward。
- 梯度。
- optimizer state,比如 AdamW 的 \(m_t\)、\(v_t\)。
- 混合精度训练中的额外状态。
而推理不需要 backward,主要额外保存的是 KV cache。所以同样 32k context,推理可能还能跑,训练会贵很多。
因此,长上下文能力可以拆成三层:
- 位置编码是否支持更长位置。
- 模型是否通过训练学会使用长距离信息。
- 训练和推理资源是否支持这么长的序列。
一句话总结:位置编码扩展让模型“能处理更长位置”,长上下文训练让模型“真的会用长上下文”。
Q8.3: 下一个 token 的预测是否受限于最后一个 hidden state?
这里还有一个容易被忽略的问题:对于 causal language model 来说,模型预测下一个 token 时,通常确实只使用最后一层、最后一个位置的 hidden state。
假设输入序列是:
\[ x_1,x_2,\dots,x_t \]
经过 \(L\) 层 Transformer 之后,第 \(t\) 个位置会得到最后一层的 hidden state:
\[ h_t^{(L)}\in \mathbb{R}^{d_{\text{model}}} \]
其中,\(h_t^{(L)}\) 表示最后一层第 \(t\) 个位置的表示,\(d_{\text{model}}\) 是模型的 hidden size。预测下一个 token 时,模型通常会把它送入 LM Head:
然后再经过 softmax 得到下一个 token 的概率分布:
\[ p(x_{t+1}\mid x_{\le t})=\operatorname{softmax}(\text{logits}_{t+1}) \]
从这个角度看,这种直觉是对的:虽然前面的 token 可以在多层 attention 里不断组合、交换和变换信息,但最终用于预测 \(x_{t+1}\) 的,确实是一个固定维度的向量 \(h_t^{(L)}\)。也就是说,整个历史上下文中与当前预测有关的信息,最后都需要被压缩到这个 \(d_{\text{model}}\) 维表示里。
这可以看成一种隐含的信息瓶颈。上下文长度可以变长,attention 可以看到更多 token,但最后参与下一个 token 预测的表示维度并不会随着上下文长度线性增长。如果序列非常长,模型就必须学会选择性地保留、压缩和聚合信息,而不是把所有上下文无损地塞进最后一个向量。
不过这里也需要稍微更精确一点:\(h_t^{(L)}\) 并不是一个静态的“全文摘要”。它是每一层 attention 根据当前位置的预测需求逐层构造出来的表示。模型不需要完整记住前面所有 token 的每个细节,而是需要保留对预测下一个 token 有用的信息。
比如在预测一句话的下一个词时,模型可能只需要最近几个 token 的局部语法信息;但在长文档问答、代码补全、跨段落引用这类任务里,模型可能需要从很远的位置取回关键信息。这个时候,难点就不只是“上下文窗口够不够长”,还包括:
- 最后一个位置的 hidden state 能不能有效聚合远距离信息。
- attention 是否真的学会在长序列中找到关键 token。
- 固定的 \(d_{\text{model}}\) 维表示是否足够承载当前预测需要的信息。
- 训练数据里是否有足够多需要长距离依赖的样本。
所以长上下文能力并不只是 position embedding 或显存问题。即使模型结构上能接收很长的输入,它仍然要通过 attention 和 hidden state,把“长上下文里真正有用的部分”压缩成当前预测所需的表示。这个压缩过程做得好不好,也是长上下文模型能力的重要限制之一。
Q9: Scaling Law 是什么?它说明了什么?
Scaling law 讨论的是模型性能如何随着模型参数量、训练数据量和计算量变化。它不是一个严格的理论定理,而是从大量训练实验里拟合出来的经验规律。
先定义几个符号:
- \(L\):模型的 cross entropy loss,也可以理解为平均 negative log-likelihood。
- \(N\):模型参数量。Kaplan 论文里通常指不包含 embedding 的参数量。
- \(D\):训练数据量,也就是训练 token 数。
- \(C\):训练 compute,通常用 FLOPs 衡量。
对于 dense Transformer language model,一个常用的训练 compute 近似是:
\[ C\approx 6ND \]
其中,\(N\) 是参数量,\(D\) 是训练 token 数。这个公式的直觉是:每个 token 的 forward 和 backward 大致都要对模型参数做若干次计算,所以总 compute 会同时随参数量和 token 数增长。
OpenAI 的 Scaling Laws for Neural Language Models 观察到,当其他因素不成为瓶颈时,loss 会随着模型参数量、数据量、训练 compute 呈现幂律下降。
当主要瓶颈是模型参数量 \(N\) 时,论文写成:
\[ L(N)=\left(\frac{N_c}{N}\right)^{\alpha_N} \]
其中,\(N_c\) 是拟合得到的常数,\(\alpha_N\) 是参数量方向的 scaling exponent。论文给出的拟合结果大约是:
\[ \alpha_N\approx 0.076 \]
当主要瓶颈是训练数据量 \(D\) 时:
\[ L(D)=\left(\frac{D_c}{D}\right)^{\alpha_D} \]
其中,\(D_c\) 是拟合得到的常数,\(\alpha_D\) 是数据量方向的 scaling exponent。论文给出的拟合结果大约是:
\[ \alpha_D\approx 0.095 \]
当主要瓶颈是 compute,并且模型大小和训练过程都接近 compute-optimal 时:
\[ L(C_{\min})=\left(\frac{C_c^{\min}}{C_{\min}}\right)^{\alpha_C^{\min}} \]
其中,\(C_{\min}\) 表示为了达到某个 loss 所需的最小 compute,\(C_c^{\min}\) 是拟合常数,论文给出的指数大约是:
\[ \alpha_C^{\min}\approx 0.050 \]
Kaplan 论文还给了一个同时考虑模型大小和数据量的形式:
\[ L(N,D)= \left[ \left(\frac{N_c}{N}\right)^{\frac{\alpha_N}{\alpha_D}} + \frac{D_c}{D} \right]^{\alpha_D} \]
这个公式表达的是:模型太小会带来损失,数据太少也会带来损失;最终 loss 可以看成这两类限制共同作用的结果。
根据这套拟合关系,Kaplan 论文得到的 compute-optimal 趋势大致是:
\[ N_{\text{opt}}\propto C^{0.73} \]
\[ D_{\text{opt}}\propto C^{0.27} \]
也就是说,如果训练 compute 增加,Kaplan 版本的建议更偏向于优先增大模型参数量,而训练 token 数增长得相对慢一些。
后来的 Chinchilla 工作 Training Compute-Optimal Large Language Models 重新研究了这个问题。它的核心问题是:在固定 compute 预算 \(C\) 下,应该把预算更多分给模型参数量 \(N\),还是训练 token 数 \(D\)?
Chinchilla 论文使用的参数化 loss 形式是:
\[ L(N,D)=E+\frac{A}{N^\alpha}+\frac{B}{D^\beta} \]
其中:
- \(E\):理想生成过程在数据分布上的不可约 loss,可以理解为数据本身的熵下界。
- \(\frac{A}{N^\alpha}\):模型参数量不够带来的额外 loss。
- \(\frac{B}{D^\beta}\):训练 token 数不够带来的额外 loss。
论文拟合得到:
\[ E=1.69,\qquad A=406.4,\qquad B=410.7 \]
\[ \alpha=0.34,\qquad \beta=0.28 \]
然后在 compute 约束下做优化:
也就是在 \(6ND=C\) 这个预算约束下,寻找能让 loss 最小的 \(N\) 和 \(D\)。
根据 Chinchilla 的参数化形式,可以得到 compute-optimal frontier:
\[ N_{\text{opt}}(C)=G\left(\frac{C}{6}\right)^a \]
\[ D_{\text{opt}}(C)=G^{-1}\left(\frac{C}{6}\right)^b \]
其中:
\[ G=\left(\frac{\alpha A}{\beta B}\right)^{\frac{1}{\alpha+\beta}} \]
\[ a=\frac{\beta}{\alpha+\beta},\qquad b=\frac{\alpha}{\alpha+\beta} \]
把 \(\alpha=0.34\)、\(\beta=0.28\) 代进去:
\[ a=\frac{0.28}{0.34+0.28}\approx 0.45 \]
\[ b=\frac{0.34}{0.34+0.28}\approx 0.55 \]
这说明 Chinchilla 的结论和 Kaplan 不太一样。它认为当 compute 增加时,模型参数量和训练 token 数应该接近同比例增长,而不是主要把预算用来增大模型。
论文里用三种方法估计这个关系,最后得到的趋势大致可以概括为:
\[ N_{\text{opt}}\propto C^{0.5},\qquad D_{\text{opt}}\propto C^{0.5} \]
这就是常说的 Chinchilla scaling:模型变大时,训练 token 数也应该同步变多。
这个结论的一个重要后果是:很多早期大模型其实是 undertrained 的。它们参数量很大,但训练 token 数不够多,所以并没有在给定 compute 下达到最优。Chinchilla 本身就是一个典型例子:它比 Gopher 小很多,但训练 token 更多,在相近 compute 下效果更好。
对 MiniMind 这样的学习项目来说,我们不需要直接套这些工业级公式。因为这些公式是在特定数据集、特定模型结构和大规模训练设置下拟合出来的,小模型、小数据集不一定满足相同规律。但它们给了一个非常重要的直觉:
- 参数量、数据量、计算量要一起看。
- 只增大模型、不增加训练 token,模型可能 undertrained。
- 只增加数据、不增加模型容量,模型也可能吃不下更复杂的分布。
- pretrain 里不能只看 epoch,更应该关注 tokens seen。
- 数据质量和数据规模本身就是 pretrain 的核心变量。
这也是为什么 MiniMind 的意义不是直接复制工业级训练结论,而是帮助我们在小规模实验中看清这些变量之间的关系。
Q10: Batch Size、Epoch 和 Tokens Seen 应该怎么理解?
这一节其实是在回答一个训练计量问题:一次参数更新到底看了多少数据?整个训练过程一共看了多少 token?这些量又和显存、epoch、compute 有什么关系?
Q10.1: Batch size、梯度累积和分布式训练是什么关系?
在代码里看到的 batch_size,通常不是整个训练系统的总 batch size,而是每张卡、每次 forward/backward 实际处理的样本数。这个值也常被叫作 micro-batch size。
MiniMind 默认设置里:
parser.add_argument("--batch_size", type=int, default=32, help="batch size")
parser.add_argument("--accumulation_steps", type=int, default=8, help="梯度累积步数")
如果显存不够,最直接的办法就是把每张卡上的 batch_size 设小一点。这样每次 forward/backward 处理的样本少,激活占用也会少一些,显存压力会下降。
但是 batch size 太小,单次梯度估计会比较嘈杂。于是训练里经常使用 gradient accumulation。它的意思是:连续做多次 forward/backward,把梯度累积在参数上,暂时不执行 optimizer.step();等累积了指定次数之后,再统一做一次参数更新。
可以把它理解成:
- 第 1 个 micro-batch 计算梯度,先不更新参数。
- 第 2 个 micro-batch 继续计算梯度,把梯度加到前面的梯度上。
- 重复 \(A\) 次。
- 最后做一次
optimizer.step(),完成一次真正的参数更新。
这里的 \(A\) 就是 accumulation_steps。
分布式训练里还会多一个维度:多张 GPU 同时处理不同的数据。每张卡先在自己的 micro-batch 上计算梯度,然后通过 all-reduce 把不同 GPU 上的梯度求平均。这样就相当于多张卡一起组成了一个更大的 batch。
所以 effective batch size 可以写成:
\[ B_{\text{eff}}=B_{\text{micro}}\times A\times W \]
其中:
- \(B_{\text{micro}}\):每张卡单次 forward/backward 的 batch size。
- \(A\):gradient accumulation steps。
- \(W\):world size,也就是参与训练的 GPU 数量。
例如单卡训练时,MiniMind 默认配置下:
\[ B_{\text{eff}}=32\times 8\times 1=256 \]
如果是 4 张 GPU,并且每张卡仍然使用 batch_size=32、accumulation_steps=8,那么:
\[ B_{\text{eff}}=32\times 8\times 4=1024 \]
如果每条样本长度是 \(L\),也可以进一步估计每次参数更新处理了多少 token:
\[ T_{\text{update}}=B_{\text{eff}}\times L \]
其中,\(T_{\text{update}}\) 表示每次 optimizer.step() 对应的 token 数。对于 LLM 训练来说,这个量往往比“多少条样本”更直观,因为不同样本的长度可能不同。
那么 effective batch size 是不是越大越好?不一定。
更大的 batch size 通常有几个好处:
- 梯度估计更平滑,训练曲线可能更稳定。
- 多卡训练时吞吐更高,硬件利用率可能更好。
- 每次参数更新看过的数据更多,噪声更小。
但它也有代价:
- 在总 token 数固定时,batch 越大,参数更新次数越少。
- batch 变大后,学习率、warmup 和 weight decay 往往都需要重新调。
- batch 太大时,梯度噪声太小,泛化不一定更好。
- 继续增大 batch 到某个程度后,收益会明显变小。
所以 batch size 不是单纯追求越大越好,而是在显存、吞吐、训练稳定性、更新次数之间做平衡。LLM pretrain 通常会使用较大的 effective batch size,但它会配合学习率调度、warmup 和稳定性监控一起调。
Q10.2: Epoch、tokens seen 和 training compute 应该怎么理解?
Epoch 表示完整遍历训练集的次数。在传统深度学习里,数据集通常没有那么大,所以经常会训练很多 epoch。比如图像分类里,一个数据集可能被反复看几十遍甚至上百遍。
但是 LLM pretrain 的情况很不一样。语言模型的数据集往往非常大,大到完整训练一个 epoch 就已经需要巨大的计算量。所以在 LLM 里,大家更常用的训练计量单位不是 epoch,而是 tokens seen,也就是训练过程中模型实际处理过的 token 总数。
假设去重后的训练数据集一共有 \(D_{\text{dataset}}\) 个 token,训练了 \(E\) 个 epoch,那么:
\[ D_{\text{seen}}=E\cdot D_{\text{dataset}} \]
其中,\(D_{\text{seen}}\) 是训练过程中实际喂给模型的 token 总数。
Scaling law 里的训练 compute 近似可以写成:
\[ C\approx 6ND_{\text{seen}} \]
其中,\(N\) 是模型参数量,\(D_{\text{seen}}\) 是训练过程中实际处理过的 token 数。这里的 \(D_{\text{seen}}\) 不是说“数据集必须只过一遍”,而是模型训练期间总共看过多少 token。
如果数据集固定,就可以把 compute 和 epoch 联系起来:
\[ C\approx 6NE D_{\text{dataset}} \]
也就是说,在模型大小 \(N\) 和数据集大小 \(D_{\text{dataset}}\) 固定时,训练更多 epoch 会线性增加训练 compute。
反过来,如果有固定 compute 预算 \(C\),可以粗略估计最多训练多少个 epoch:
\[ E\approx \frac{C}{6ND_{\text{dataset}}} \]
如果不知道 compute \(C\) 是多少, Chinchilla 论文里的一个经验值是,总token数大约为模型参数量的20倍:
\[ D_{\text{seen}} \approx 20 N \]
这样我们可以得到epoch: \[ E \approx \frac{D_{\text{seen}}}{D_{\text{dataset}}} \approx \frac{20 N}{D_{\text{dataset}}} \]
不过这里有一个容易混淆的问题:如果数据有限,第二遍、第三遍重复同一批数据,这到底算不算“增加数据”?
从训练计数上看,它确实增加了 tokens seen:
\[ D_{\text{seen}}=E\cdot D_{\text{dataset}} \]
也确实增加了 compute:
\[ C\propto D_{\text{seen}} \]
但它不等价于增加了新的数据多样性。更准确地说,我们可以区分两个概念:
\[ D_{\text{seen}}=\text{训练过程中实际处理过的 token 总数} \]
\[ D_{\text{unique}}=\text{去重后真正不同的 token 或文档规模} \]
如果同一个样本被看了三遍,那么 \(D_{\text{seen}}\) 会按三倍计算,但 \(D_{\text{unique}}\) 并没有变成三倍。第二遍、第三遍仍然能帮助优化,因为模型会继续从这些样本上更新参数;但它带来的信息增量通常会下降,并且可能增加过拟合和记忆风险。
这也是 LLM pretrain 和传统小数据深度学习的一个重要区别。传统深度学习经常默认“一个 epoch 太少”,因为数据集相对小,模型需要反复拟合这些样本。而 LLM pretrain 面对的是巨大的 token 流,很多时候一个 epoch 或少数几个 epoch 就已经足够昂贵。相比“把同一批数据刷很多遍”,更有价值的往往是扩大高质量、去重后的数据覆盖。
所以可以这样理解:
- 增加 epoch:增加 tokens seen,也增加 training compute。
- 增加 epoch 但不增加新样本:增加优化步数,但不增加数据多样性。
- 增加去重后的高质量数据:既增加可训练 token,也增加数据覆盖。
- 在 LLM pretrain 中,tokens seen 通常比 epoch 更适合作为训练进度指标。
因此,对于 pretrain,更自然的观察单位通常是:
- steps:优化器更新了多少次。
- tokens seen:模型总共处理了多少 token。
- unique tokens / unique documents:训练数据本身有多少去重后的信息。
- effective batch size:每次参数更新大约用了多少样本或 token。
- learning rate schedule:这些更新发生在什么学习率下。
Q10.3: 如何决定 effective batch size?
这个问题麻烦的地方在于:effective batch size 和 learning rate 是强耦合的。它们都会影响 loss 曲线的稳定性,而且有时候会造成相似的现象。所以实践里通常不是先拍脑袋决定一个 batch size,再单独决定 learning rate,而是把它们当成一组训练配置一起调。
参数更新可以粗略写成:
\[ \theta_{t+1}=\theta_t-\eta \hat{g}_t \]
其中,\(\eta\) 是 learning rate,\(\hat{g}_t\) 是当前 batch 估计出来的梯度。batch size 影响的是 \(\hat{g}_t\) 的噪声大小,learning rate 影响的是沿着这个梯度方向走多远。
如果 batch size 变大,\(\hat{g}_t\) 通常会更接近真实平均梯度,噪声更小:
但如果 learning rate 太大,即使梯度估计更平滑,参数也可能一步走太远,导致 loss spike 甚至 NaN。反过来,如果 batch size 很小,loss 也可能抖动很大,但这是梯度估计噪声造成的,不一定代表学习率已经过大。
不过实际操作时,仍然需要一个清晰的顺序。一个比较稳妥的流程是:
第一步:先确定硬件能承受的 micro-batch。
单卡显存主要受模型大小、序列长度和 micro-batch size 影响。直观上,可以理解为:
\[ \text{memory}\uparrow \quad \text{when}\quad B_{\text{micro}}\uparrow,\ L\uparrow,\ d_{\text{model}}\uparrow,\ \text{layers}\uparrow \]
其中,\(B_{\text{micro}}\) 是每张卡单次 forward/backward 的样本数,\(L\) 是序列长度。通常先固定模型和 seq_len,然后从 batch_size=1,2,4,8... 往上试,找到不会 OOM、吞吐也还可以的 \(B_{\text{micro}}\)。这个阶段主要受显存约束,不要急着讨论理论最优。
第二步:通过梯度累积和多卡得到几个候选 effective batch size。
确定 \(B_{\text{micro}}\) 后,再用:
\[ B_{\text{eff}}=B_{\text{micro}}\times A\times W \]
得到实际每次参数更新对应的 batch size。这里 \(A\) 是 accumulation_steps,\(W\) 是 GPU 数。
对于 LLM,更建议同时看每次 optimizer step 处理多少 token:
\[ T_{\text{update}}=B_{\text{eff}}\times L \]
其中,\(L\) 是序列长度。相比单纯看 \(B_{\text{eff}}\),\(T_{\text{update}}\) 更适合 LLM,因为 seq_len=512 和 seq_len=4096 时,同样的 batch size 对应的 token 数完全不同。
对于学习项目或小模型,可以先从比较温和的范围试起。一个粗略参考是:
- 如果 \(L=512\),可以先试 \(B_{\text{eff}}=64,128,256,512\),对应每次更新大约 \(3.2\times 10^4\) 到 \(2.6\times 10^5\) tokens。
- 如果 \(L=1024\),可以先试 \(B_{\text{eff}}=32,64,128,256\),对应每次更新大约 \(3.2\times 10^4\) 到 \(2.6\times 10^5\) tokens。
- 如果是更大的训练,常见做法会继续把 \(T_{\text{update}}\) 提到 \(10^5\sim 10^6\) 甚至更高,但这通常需要更仔细的 LR、warmup 和稳定性调参。
这些不是理论最优值,只是起步参考。真正的选择还要看模型大小、数据质量、显存、吞吐和 loss 曲线。
第三步:在候选 \(B_{\text{eff}}\) 上重新寻找 learning rate。
这一步很重要:当 \(B_{\text{eff}}\) 改变时,learning rate 通常也要跟着改。一个常见经验是:
\[ \eta_{\text{new}}\approx \eta_{\text{old}}\left(\frac{B_{\text{new}}}{B_{\text{old}}}\right)^p \]
其中,\(p\) 通常可以先在 \([0.5,1.0]\) 之间理解。\(p=1\) 接近 linear scaling rule,\(p=0.5\) 接近 square-root scaling。对 LLM 的 AdamW 训练来说,这只是调参起点,不是定律。batch 变大时,通常还需要更长的 warmup。
所以更实际的做法是:不要只试一个 learning rate。对于一个候选 \(B_{\text{eff}}\),至少试两三个 learning rate,比如原始学习率、稍小一点、稍大一点。这样才能判断问题到底来自 batch size,还是来自 LR 不匹配。
第四步:用 loss 曲线区分 batch 问题和 LR 问题。
从 loss 曲线上,可以大致这样判断:
- batch 太小:单 step loss 抖动很明显,但滑动平均 loss 仍然能稳定下降;梯度范数可能有噪声,但不一定持续变大。
- learning rate 太大:loss 不只是抖动,而是出现明显 spike、持续升高,甚至 NaN;梯度范数也可能突然变大。
- batch 很大但 LR 偏小:loss 曲线很平滑,但按 tokens seen 比较时下降很慢,训练像是在“慢慢挪”。
- batch 变大但 LR / warmup 没跟上:前期 loss spike,或者 warmup 结束附近突然不稳定。
这里最容易误判的是第一种和第二种:它们都可能表现为 loss 抖动。但 batch 太小通常是“有噪声地下降”,而 LR 太大更像是“更新走过头”,会出现 spike、发散或者 NaN。
第五步:比较实验时按 tokens seen,而不是只按 step。
batch size 改变后,每个 step 处理的 token 数也会改变。如果只看 step,batch 大的实验每一步看了更多 token,比较会不公平。所以更合理的是固定模型、数据、seq_len 和总 tokens seen,然后做少量网格:
| 实验 | \(B_{\text{eff}}\) | learning rate | 观察重点 |
|---|---|---|---|
| A | 小 | 小/中 | 是否稳定下降,噪声是否可接受 |
| B | 中 | 中 | 通常作为主要候选 |
| C | 大 | 中/大 | 吞吐是否更好,按 tokens seen 是否真的更快 |
如果只能做很少实验,我更倾向于先选一个不会让更新次数太少的中等 \(B_{\text{eff}}\),再围绕它调 learning rate。因为 batch 太大以后,虽然曲线好看,但在固定 tokens seen 下参数更新次数会明显减少,小模型实验里不一定划算。
所以总结成一句话:先由显存确定 micro-batch 的可行范围,再用梯度累积和多卡得到适中的候选 \(B_{\text{eff}}\),然后根据候选 batch 重新调 LR, 如果能work最好,但是如果不行的话就需要重新选择 batch 再选择LR ,最后评估的时候,除了要看 step 级别的曲线,还要按 tokens seen 的 loss 曲线判断模型是否更新的足够快。 需要始终记住的是,loss 抖动不一定只说明 batch 小,也可能是 LR 太大;这两个旋钮必须一起看。
Q11: 为什么不同实验的 loss 曲线不能随便比较?
这算是Eval章节的一个实操预演,我们会在Eval章节进行更多的展开.
比如,一个实验 padding 很多,另一个实验有效 token 更多,它们虽然都在算平均 loss,但实际参与统计的 token 分布并不一样。再比如,effective batch size 变大后,loss 曲线可能更平滑,但这不一定代表模型能力更强,因为它的更新次数、梯度噪声和 learning rate 适配关系都变了。
所以训练指标不是孤立数字。每一条 loss 曲线背后,都绑定着一整套数据和训练配置。
如果要比较不同实验,至少需要尽量检查下面这些参数。这里大致按照重要性排列:
- 数据集是否一致:包括数据来源、数据清洗、去重、过滤规则、数据混合比例。
- tokenizer 是否一致:不同 tokenizer 会改变 token 数、切分方式和 loss 的统计单位。
- tokens seen 是否一致:不同实验最好按训练 token 数比较,而不是只按 step 或 epoch 比较。
max_seq_len是否一致:序列长度会影响上下文范围、padding 比例和每步 token 数。- packing、padding、truncation 规则是否一致:这些会影响有效 token 比例。
- loss mask 是否一致:padding token、特殊 token、prompt token 是否参与 loss,都会改变 loss 数值。
- 模型结构是否一致:参数量、层数、hidden size、attention head、position encoding、是否 tie embedding。
- optimizer 是否一致:AdamW、Lion、Muon 这类优化器的更新方式不同,loss 曲线形态也可能不同。
- learning rate 和 schedule 是否一致:包括初始 LR、warmup、cosine decay、最小 LR。
- effective batch size 是否一致:包括
batch_size、accumulation_steps、world size。 - weight decay、gradient clipping 是否一致:这些会影响训练稳定性和参数范数。
- mixed precision 设置是否一致:比如 fp16、bf16、loss scale、是否使用 gradient scaler。
- 随机性是否一致:seed、shuffle、dataloader worker、分布式采样方式都会影响短期曲线。
- eval 设置是否一致:eval 数据集、eval 间隔、eval batch size、是否固定 eval samples。
除了看一条 train loss 曲线,实际训练时还可以同时看几类曲线:
- train step loss:每一步训练 loss,最原始,但噪声最大。
- smoothed train loss:对 step loss 做滑动平均,更适合看整体下降趋势。
- train loss vs tokens seen:比
loss vs step更适合比较不同 batch size 的实验。 - eval loss:在固定验证集上的 loss,更适合判断泛化能力。
- eval perplexity:由 eval loss 转换得到,公式是:
\[ \text{PPL}=\exp(L) \]
其中,\(L\) 是平均 cross entropy loss。
- learning rate curve:确认 warmup、decay 是否按预期执行。
- gradient norm curve:判断是否有梯度爆炸、LR 过大或训练不稳定。
- parameter norm / update norm:观察参数本身和每次更新幅度是否异常。
- loss scale / NaN count:混合精度训练时用于判断数值稳定性。
- tokens/sec 或 step time:观察吞吐,不然可能 loss 下降快但训练效率很差。
- train loss 和 eval loss 的 gap:如果 train loss 继续下降但 eval loss 不降,可能有过拟合、数据污染或训练分布不匹配的问题。
所以比较实验时,不要只说“第 N step 的 loss 更低”。尤其当 \(B_{\text{eff}}\)、seq_len 或 accumulation_steps 不同时,第 N step 背后对应的 tokens seen 可能完全不同。更稳妥的做法是:用 loss vs tokens seen 作为主轴,再结合 eval loss、gradient norm、learning rate curve 和吞吐一起判断。
Q12: 一个 CheckList
整个训练流程可以按照如下步骤检查规划:
1.根据目标和算力,确定模型参数量和模型规模:
- 影响 layers、hidden size、heads、训练预算。
2.根据目标上下文能力,设计数据集和序列长度:
- 影响
max_seq_len、packing、padding、truncation。
3.根据模型参数量和数据集规模,估算训练 token 数:
- 影响
tokens seen、epoch、是否需要重复数据。
4.根据 optimizer、weight decay、precision 等训练配置,估算训练状态开销:
- 影响显存、optimizer state、是否需要 mixed precision / checkpointing。
5.根据实际硬件显存
- 设置
batch_size、gradient_accumulation_steps和分布式方式 - 影响
B_eff、tokens per update、吞吐。
6.观察训练稳定性和收敛速度
- 根据
B_eff和 loss 曲线 - 调整 learning rate、warmup、decay schedule
7.训练过程中其他Eval指标的监控
- loss、eval loss、PPL, gradient norm、LR curve、tokens/sec。
8.实验管理
- 记录配置,保证实验可复现、可比较。
- 可视化清晰
参考资料
- Scaling Laws for Neural Language Models
- Training Compute-Optimal Large Language Models
- Symbolic Discovery of Optimization Algorithms
- Muon: An optimizer for hidden layers in neural networks
Pretrain 的实施细节和常见坑
上一节我们更多讨论的是模型、目标函数和优化器这些偏原理的内容.这一节开始,我们进入训练的实现部分,也就是一个 pretrain 脚本到底是怎么真正跑起来的.
这部分未必总是在讲很复杂的理论,但它对训练能不能稳定进行、能不能顺利复现、出了问题能不能快速排查,其实非常重要.很多时候,真正让预训练跑不顺的,并不是模型结构本身,而是这些实现细节没有处理好.
所以这一节我还是想按照 QA 的形式,把训练里一些很关键但又很容易被忽略的问题串起来:
- 训练配置和模型配置分别是什么?
- 一个完整的 pretrain 训练脚本通常由哪些环节组成?
- 为什么要设置随机种子? 应该怎么设置?
- 分布式训练主要在解决什么问题? 梯度累积又是怎么接到训练循环里的?
- 什么是混合精度训练?
- 梯度稳定性操作:梯度缩放,梯度剪裁? 梯度累积、梯度剪裁和
GradScaler的顺序应该怎么放? - checkpoint 应该保存什么? 又该怎么做断点恢复?
- 可视化工具主要看什么?
Q1: 一个完整的 Pretrain 训练脚本通常由哪些环节组成?
如果只看最核心的训练过程,好像事情很简单,无非就是:
- forward 算出 loss.
- backward 算出梯度.
- optimizer 更新参数.
但真实能跑起来的 pretrain 脚本,远不止这三步.它通常还要处理分布式初始化、随机种子、数据加载、混合精度、梯度累积、日志记录、checkpoint 保存和断点恢复这些事情.
以 MiniMind 为例,它的 pretrain 主流程可以粗略拆成下面几个环节:
- 初始化分布式环境,并确定当前进程使用的设备.
- 设置随机种子,尽量保证实验可复现.
- 创建模型配置,初始化模型和 tokenizer.
- 读取预训练数据,构造
Dataset、Sampler和DataLoader. - 设置优化器、学习率调度、混合精度上下文和
GradScaler. - 对每个 batch 执行 forward,计算 loss,然后 backward.
- 按照梯度累积步数决定什么时候真正更新参数,并在更新前后处理梯度裁剪、梯度缩放和梯度清零.
- 定期打印日志、记录可视化指标、保存 checkpoint.
在代码里,这条主线主要集中在 src/minimind_learning/trainer/train_pretrain.py:
# src/minimind_learning/trainer/train_pretrain.py
local_rank = init_distributed_mode()
if dist.is_initialized():
args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
model, tokenizer = init_model(lm_config, args.from_weight, device=args.device)
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16'))
optimizer = optim.AdamW(model.parameters(), lr=args.learning_rate)
这段代码也说明了一件事: 训练脚本不是只有 model(X) 和 loss.backward(). 真正完整的训练流程,还包括随机性控制、数据采样、混合精度、优化器状态、分布式包装和断点恢复.
下面我们逐一进入细节:
Q1.1: 训练配置和模型配置里一般有什么?
这是一个很容易被忽略,但实际上非常重要的点.一个完整的训练流程,最好要有比较清晰的配置系统,专门去管理“模型怎么定义”和“训练怎么执行”这两类信息.这样会让整个训练流程更清楚,也会让复现容易很多.
MiniMind 现在主要是用 argparse 去传训练参数.这种方式在项目比较小时很直接,但参数一多,训练脚本和训练配置本身就会慢慢混在一起.这样一来,如果你想改训练设置,经常就得去改脚本本身,配置来源也会变得比较分散,后面无论是复现实验还是维护代码,都会有点乱.
比较常见也更清晰的做法,是把这些配置单独整理到配置文件里,比如 json、yaml,或者再进一步,封装成专门的配置类.这样做的核心好处,其实就是把“数据”和“逻辑”分开: 训练脚本负责执行流程,配置文件负责描述这次实验到底要怎么跑.这样你只需要改配置,就可以比较快地调整实验,也更容易复现之前的结果.
这里可以粗略把配置分成两类:
1. 模型配置
模型配置回答的是: 你到底要训练一个什么样的模型?
一般会包括这些内容:
模型基础信息:
- 模型类型或者模型名称
- 最大序列长度
max_seq_len
词表和 tokenizer 相关:
- 词表大小
vocab_size - 特殊 token 的定义,比如
bos_id、eos_id、pad_id - tokenizer 通常会和模型一起考虑,所以这里先放在模型配置里一起讨论.
Embedding 相关:
- 位置编码或者 RoPE 相关参数
- 普通的 embedding 一般由
hidden_size和vocab_size定义,但如果有特殊设计,也可能有额外参数
模型结构相关:
- 隐藏层维度
hidden_size - Transformer 层数
num_layers - 注意力头数
num_heads - 前馈网络维度
intermediate_size - 如果项目把每个 attention head 的维度单独写出来,也可能会有
head_dim
其他细节:
- dropout 相关参数
- 是否共享输入输出 embedding
- normalization 相关参数,比如
norm_eps - 激活函数类型,比如
GELU、SwiGLU
2. 训练配置
一般会包括这些内容:
路径类配置:
- 数据集路径 (验证集,测试集)
- tokenizer 路径或者词表路径
- 日志输出路径
- checkpoint 保存路径
- resume checkpoint 路径
- 配置文件本身的保存路径
实验设置类:
- 实验名称或者 run id
- 设备类型,比如
cpu或cuda - 随机种子
- 是从头训练,还是从已有权重开始训练
- 日志打印频率、验证频率、checkpoint 保存频率
实验可视化类:
- 是否开启可视化工具,以及对应的 project / run 配置
训练系统类(工程参数 分布式 混合精度):
- 分布式训练相关参数,比如
world_size、rank、local_rank - 混合精度类型,比如
float16或bfloat16 - DataLoader 相关参数,比如
num_workers、pin_memory
训练参数:
- 优化器类型,比如
AdamW - batch size、梯度累积步数、训练轮数、最大训练步数
- 学习率、权重衰减、warmup 步数、学习率调度策略
- 梯度裁剪阈值
- 是否 shuffle、是否
drop_last
3. 更多细节
还有一些更细节的配置,不一定每个项目都会单独写出来,但在一些实现里也很常见.如果继续往下拆,其实也可以按前面的分类方式来理解:
模型配置里更细节的内容:
-
attention 细节: 有些项目除了
num_heads之外,还会单独配置num_kv_heads, 用来区分普通多头注意力、MQA或GQA. 这些设置会直接影响 attention 的参数规模、KV cache 的大小,以及推理时的效率. -
FFN 细节: 有的实现会直接写
intermediate_size, 也有的实现不会直接给这个值,而是通过某种扩展倍率,比如ffn_mult,去间接确定它. 如果模型用了SwiGLU这类结构,FFN 部分的实际维度设计也可能和最基础的 MLP 写法不太一样. -
参数初始化: 有些项目会把参数初始化方式也放进配置里,比如初始化标准差、不同层是否采用不同的初始化策略. 这些内容平时不一定最先关注,但它们会影响训练刚开始时的稳定性.
-
norm 和激活函数的进一步细节: 除了前面提到的
norm_eps和激活函数类型,有的实现还会进一步区分用的是哪一种 normalization. 也有的项目会在不同模块里采用不同的激活函数. -
模型默认 dtype: 有些项目会在模型配置里单独写模型权重默认使用什么 dtype,比如
float32、bfloat16. 这个设置有时也会影响模型初始化、加载权重和后续训练流程.
训练配置里更细节的内容:
数据相关配置:
- 训练集路径和验证集路径分别是什么.
- 数据格式是什么,比如
jsonl、bin、memmap. - 是否流式读取.
- 是否 shuffle.
num_workers.pin_memory.- 是否
drop_last. - 是否做 packing.
- 每条样本的截断 / 拼接策略.
恢复与初始化相关配置:
- 是从头训练,还是从已有权重开始.
- 是
from_pretrained还是from_scratch. - 是否加载 optimizer state.
- 是否恢复 scheduler state.
- 是否恢复 scaler state.
- 恢复到哪个
epoch/step.
保存策略相关配置:
- checkpoint 是按 step 保存还是按 epoch 保存.
- 保存间隔是多少.
- 最多保留多少个 checkpoint.
- 是否额外保存一个 best checkpoint.
- 是只保存模型权重,还是保存完整训练状态.
验证 / 评估相关配置:
- 是否开启验证.
- 验证频率.
- 验证集路径.
- 验证指标.
- 验证时的 batch size.
- 如果是生成任务,还可能会带上
max_new_tokens、temperature这类推理配置.
训练目标相关配置:
- loss 类型.
- 是否做 label smoothing.
ignore_index是多少.- 是否对某些 token 做 mask.
- 是否有 auxiliary loss.
系统与复现相关配置:
- 使用哪些 GPU.
cudnn/matmul精度设置.- 除了随机种子之外,是否开启 deterministic.
- 运行时的代码版本、git commit id.
- 配置文件本身是否要保存到实验目录里.
从工程角度看,路径类配置尤其值得单独检查.至少在训练开始前,应该确认下面这些路径是否存在、是否可读、是否可写:
- 训练集路径
- 验证集路径
- tokenizer 或词表路径
- 日志目录
- checkpoint 输出目录
- resume checkpoint 路径
- 配置文件本身的保存路径
这一类检查听起来很基础,但非常有必要.因为如果路径问题不提前处理,训练很可能不是一开始报错,而是跑到中间某个地方才因为找不到文件或者目录不可写而停下来,这样调试起来就很浪费时间.
Q2: Seed怎么设置?
训练里有很多随机性来源,比如参数初始化、数据 shuffle、dropout、CUDA 算子选择等。设置 seed,是保证两次运行复现实验现象的必要条件。
MiniMind 的工具函数里设置了 Python、NumPy、PyTorch 和 CUDA 的随机种子:
# src/minimind_learning/trainer/trainer_utils.py
def setup_seed(seed: int):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
这里还有一个细节:分布式训练时,不同 rank 会使用略微不同的 seed:
# src/minimind_learning/trainer/train_pretrain.py
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
这样可以避免所有进程的随机状态完全一样。对于分布式训练来说,这通常更合理。
Q3: 分布式训练怎么进行?
分布式训练的目标是把训练任务拆到多张 GPU 上执行,从而提高吞吐量,或者让更大的模型、更大的 batch 能够训练起来.
MiniMind 使用的是 PyTorch 的 DistributedDataParallel, 简称 DDP. 这里很容易有一个误解: DDP 并不是“自动把一个 batch 拆到很多张卡上”,它更像是在每个进程里的模型外面包了一层“梯度同步外壳”.
可以先把它理解成下面这件事:
- 每张 GPU 对应一个进程.
- 每个进程里各自放一份完整的模型副本.
- 每个进程各自拿到自己那一份数据,独立做 forward 和 backward.
- backward 结束之后,DDP 会自动把不同进程上的梯度同步起来.
- 梯度同步完成后,每个进程再各自执行
optimizer.step(),于是所有模型参数仍然保持一致.
所以从职责上看:
DistributedSampler负责“把数据分开”.DistributedDataParallel负责“把梯度同步回来”.
Q3.1: 分布式训练的初始化代码有哪些?
结合 MiniMind 的代码来看,PyTorch 分布式训练的主线其实没有多神秘,主要就是先把分布式环境初始化好,然后把数据集和模型分别接到分布式机制里:
# src/minimind_learning/trainer/train_pretrain.py
# 第一步 初始化分布式环境,并设置设备和随机种子
local_rank = init_distributed_mode()
if dist.is_initialized():
args.device = f"cuda:{local_rank}"
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
# 第二步 创建 sampler
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
# 第三步 包装模型
if dist.is_initialized():
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
model = DistributedDataParallel(model, device_ids=[local_rank])
这里可以按顺序理解:
- 先初始化分布式环境.
init_distributed_mode() 会先检查当前是不是分布式模式.如果环境变量里没有 RANK,那就说明现在不是 DDP 训练,直接按单卡处理.如果检测到是分布式模式,它就会调用 dist.init_process_group(...) 建立通信组,然后读取 LOCAL_RANK,再通过 torch.cuda.set_device(local_rank) 把当前进程绑定到对应的 GPU 上.
这一步很关键,因为后面每个进程都必须明确知道: “我到底在用哪一张卡”.
- 再设置设备和随机种子.
初始化完分布式环境之后,代码里会把当前进程的设备写成:
if dist.is_initialized():
args.device = f"cuda:{local_rank}"
然后再设置 seed:
setup_seed(42 + (dist.get_rank() if dist.is_initialized() else 0))
这里不是简单地让所有进程用完全相同的 seed,而是让不同 rank 的 seed 略微错开.这样做的目的是避免所有进程的随机状态完全一样.对于分布式训练来说,这种写法通常更合理.
- 用
DistributedSampler把数据分给不同进程.
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
如果不开分布式,数据集就正常顺序或 shuffle 读取.如果开了分布式,DistributedSampler 会负责把整个数据集切分给不同进程,避免每张卡都重复训练同一批数据.
- 用
DistributedDataParallel把模型包起来.
if dist.is_initialized():
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
model = DistributedDataParallel(model, device_ids=[local_rank])
这一句 DistributedDataParallel(...) 就是在告诉 PyTorch: 这个模型现在要进入分布式同步模式了.
其中 device_ids=[local_rank] 的意思是,当前这个进程只负责当前这张 GPU 上的模型副本.后面在 backward 的时候,DDP 会自动帮我们把不同进程上的梯度做同步,通常可以理解成一次 all-reduce.
这里的
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}
说明有一些 buffer 不希望被 DDP 按默认方式处理,所以提前显式忽略掉了.这也说明分布式训练虽然主线不复杂,但具体实现里还是会有一些模型相关的细节.
Q3.2: DistributedSampler 在每个 epoch 里是怎么工作的?
DistributedSampler,顾名思义,就是用来在分布式训练里给数据集配一个 sampler 的. 它的功能就是让每一个进程分布式的从总体数据集里面拿自己的部分.
先看这句:
train_sampler = DistributedSampler(train_ds) if dist.is_initialized() else None
它的意思其实很直接:
- 如果当前是分布式训练,就给数据集配一个
DistributedSampler. - 如果当前不是分布式训练,那
train_sampler就是None.
然后在训练循环里,每个 epoch 开始前会调用:
train_sampler and train_sampler.set_epoch(epoch)
这句可以理解成:
if train_sampler is not None:
train_sampler.set_epoch(epoch)
所以如果现在不是分布式环境,train_sampler 就是 None,这句代码什么都不会做.如果现在是分布式环境,那就会调用 set_epoch(epoch),让 sampler 在新的 epoch 使用新的 shuffle 顺序.
这一点很重要,因为 DistributedSampler 本身既负责“把数据按进程拆开”,也经常负责“在分布式场景下怎么 shuffle”.如果不在每个 epoch 里调用 set_epoch(epoch),那每个 epoch 的采样顺序可能就固定住了.
再看真正创建 DataLoader 的地方:
loader = DataLoader(
train_ds,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
sampler=train_sampler,
num_workers=args.num_workers,
pin_memory=True
)
这里的逻辑是:
- 如果
train_sampler is None,说明当前不是分布式训练,那就让DataLoader自己做普通的 shuffle. - 如果
train_sampler不是None,说明当前是分布式训练,那就由DistributedSampler来决定每个进程读哪些样本,这时DataLoader自己就不再额外 shuffle 了.
所以从代码上看,非分布式和分布式其实共用的是同一套训练流程,只是数据采样这一步根据 train_sampler 是否存在,自动切换成了不同模式.
Q3.3: train_epoch() 是每张卡各跑各的,还是同步后统一跑的?
答案是: 每个进程各自跑一遍 train_epoch().
如果有 4 张 GPU,通常就会有 4 个进程.这 4 个进程都会各自执行:
train_epoch(epoch, loader, ...)
所以并不是“主进程负责训练,其他进程等结果”,而是:
- 每个进程各自有自己的
DataLoader - 每个进程各自拿自己的 batch
- 每个进程各自有自己的模型副本
- 每个进程都独立执行 forward、loss 计算和 backward
真正发生同步的地方,不是整个 train_epoch() 跑完之后,而是在 backward 阶段.
Q3.4: 梯度累积是在各自显卡上做,还是统一同步后做?
更准确地说,梯度是先在各自进程本地累积,但每次 backward() 时就已经发生了同步.
也就是说:
- 每个进程先拿自己的 micro-batch
- 每个进程本地做 forward
- 每个进程本地做 backward
- backward 的过程中,DDP 自动把梯度和其他进程同步
- 同步后的梯度继续累积在各自本地参数的
.grad里 - 等到满足
accumulation_steps,每个进程再各自执行一次optimizer.step()
所以它不是“先各自累积很多步,最后再统一同步”,而是“每一步 backward 都会同步,同步后的结果再继续本地累积”.
这份 MiniMind 代码里也没有用 no_sync(),所以当前这份实现里,每次 backward() 都会触发同步.这样写更直接,也更容易理解,只是通信开销会更大一些.
优化的办法是在累积的过程中,只在最后一步 backward() 时才同步,前面几步都用 with model.no_sync(): 来跳过同步. 这样可以减少通信开销,但代码会稍微复杂一些.
Q3.5: DDP 的同步细节和执行流程到底是什么?
这里最容易混淆的一点是: DDP 不是“主进程把 batch 发给其他显卡,其他显卡再把梯度传回主进程”.
更准确的流程是:
- 每个进程自己通过
DataLoader读取自己的 batch. - 每个进程自己执行
forward(). - 每个进程自己计算 loss.
- 每个进程自己调用
backward(). - 在
backward()阶段,DDP 自动把各个进程上的梯度做同步,通常可以理解成一次 all-reduce. - 同步完成后,每个进程本地都会拿到一致的梯度.
- 每个进程再各自调用
optimizer.step(),完成本地参数更新.
所以真正负责“同步”的关键函数是 backward(),更准确地说,是 DDP 在 backward 过程中注册的那些梯度同步逻辑.
而 optimizer.step() 本身并不是用来做跨进程同步的,它做的事情主要是: 使用已经同步好的梯度,在每个进程本地更新参数.
之所以每个进程都可以各自 step(),但最后模型还能保持一致,原因就在于:
- 初始参数是一致的
- backward 之后梯度是一致的
- optimizer 的更新规则也是一样的
所以更新完成后,每个进程上的参数仍然会保持一致.
你也可以把这件事压缩成一句话:
DistributedSampler负责决定“每个进程读哪一份数据”.DDP负责决定“每个进程算出来的梯度怎么在 backward 阶段同步”.optimizer.step()负责用已经同步好的梯度,在每个进程本地更新参数.
Q3.6: DDP 的局限是什么? 更大的模型又该怎么训练?
到这里其实就能看出 DDP 的一个核心限制: 它解决的是“数据并行”的问题,但默认并不解决“单张显卡放不下完整模型”的问题.
因为在 DDP 里:
- 每张卡上都要放一份完整的模型副本
- 每个进程都会算出自己这一份梯度
- 在
backward()阶段,这些梯度还要做同步
所以模型一旦变大,会同时遇到两个压力:
-
显存压力
单张卡必须先能放下一整份模型,否则 DDP 连启动都很困难. -
通信压力
梯度的规模通常和模型参数规模是同一个量级.模型越大,每次backward()时要同步的内容也就越多.如果卡很多、网络带宽又不够强,那通信就可能成为瓶颈.
所以你可以粗略地把 DDP 理解成: 模型能放下时,它是一个很好用的数据并行方案; 模型放不下时,就不能只靠 DDP 了.
这时候更大的模型通常会用另外几类并行方案:
-
FSDP
FullyShardedDataParallel的核心思路是: 不再让每张卡都完整保存一份模型,而是把参数、梯度、优化器状态分片到不同设备上.
这样做的直接好处就是显存占用显著下降,所以它适合“模型太大,单卡放不下”的场景.
从 PyTorch 官方文档的描述来看,FSDP 本质上就是把 DDP 那种“整份复制”的方式,换成了“分片保存、按需聚合”的方式. -
Tensor Parallel
它不是把“数据”拆开,而是把“层内部的计算”拆开.
比如一个很大的线性层,可以按列切到不同 GPU,或者按行切到不同 GPU.这样每张卡只负责这个层的一部分参数和计算.
这种方式更像是在“一个算子内部做并行”,比较适合超大矩阵运算. -
Pipeline Parallel
它的思路是把模型按层切成几段,不同 GPU 分别放不同的 stage.
比如前几层在 GPU0,中间几层在 GPU1,后几层在 GPU2.
然后把一个 batch 再拆成多个 micro-batch,像流水线一样穿过这些 stage.
所以如果只做一个很粗的划分:
- DDP: 每张卡一份完整模型,主要解决“如何并行处理更多数据”
- FSDP: 把参数分片,主要解决“模型太大,单卡放不下”
- Tensor Parallel: 把层内部的张量计算拆开
- Pipeline Parallel: 把模型按层切成不同 stage
工业级大模型训练,通常不会只用其中一种,而是把这些并行策略组合起来.
一个很常见的思路是:
- 数据并行负责把样本分到不同 worker
- FSDP 或 ZeRO 类方案负责降低参数、梯度、优化器状态的显存占用
- Tensor Parallel 负责把单层内部的大矩阵计算拆到多张卡
- Pipeline Parallel 负责把整个模型沿层的方向切成多个阶段
所以工业级大模型训练,确实往往不是“只写一个普通 PyTorch 脚本就够了”,而是需要一整套更复杂的训练系统去协调这些并行策略.这也是为什么很多大模型项目最后都会发展出比较专门的训练框架或者训练基础设施.
不过从 PyTorch 现在的生态来看,也不能简单说“PyTorch 不支持这些”.更准确地说是:
- DDP 是 PyTorch 里最成熟、最直接的数据并行方案
- FSDP 已经是 PyTorch 官方支持的重要路线
- Tensor Parallel 和 Pipeline Parallel 也已经有官方能力,只是相对更复杂,有些接口还比较新
- 真正的工业级方案,往往会在 PyTorch 之上再叠一层自己的并行封装和训练框架
所以这一块如果要压缩成一句话,可以这样理解:
小模型或者中等规模模型,DDP 往往就够用了.
更大的模型,尤其是单卡放不下的时候,就必须从“只做数据并行”走向“数据并行 + 参数分片 + 模型并行”的组合方案.
Q4: 混合精度训练怎么做?
混合精度训练的目标是用更低精度的数据类型提升训练速度、降低显存占用,同时尽量保持训练稳定。
MiniMind 里通过 autocast 创建混合精度上下文:
# src/minimind_learning/trainer/train_pretrain.py
device_type = "cuda" if "cuda" in args.device else "cpu"
dtype = torch.bfloat16 if args.dtype == "bfloat16" else torch.float16
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
with autocast_ctx:
res = model(X)
loss = loss_fct(
res.logits.view(-1, res.logits.size(-1)),
Y.view(-1)
).view(Y.size())
autocast 的作用是让 PyTorch 自动决定哪些操作可以用低精度计算,哪些操作应该保留较高精度。这样比手动把所有张量都转成 float16 或 bfloat16 更安全。本质上可以理解成一个“自动混合精度的上下文环境”. 也就是说,只要代码写在
with autocast_ctx:
...
这个块里面,PyTorch 就会按照自己的规则,自动决定当前这些算子应该用什么精度来算.
所以它做的事情不是“粗暴地把所有张量都变成 float16 或 bfloat16”,而是:
- 对适合低精度的算子,尽量用低精度计算
- 对数值更敏感的算子,保留更高精度
这样做的好处是:
- 速度通常会更快
- 显存占用通常会更低
- 同时又比手动把所有内容都转成低精度更安全
这里也可以顺手解释一下这句:
autocast_ctx = nullcontext() if device_type == "cpu" else torch.cuda.amp.autocast(dtype=dtype)
它的意思是:
- 如果当前在 CPU 上,那就用
nullcontext(),相当于“什么都不做” - 如果当前在 GPU 上,那就真正启用
autocast
所以 autocast_ctx 可以理解成一个统一接口. 这样后面训练代码就不用专门写两套分支,而是统一写成:
with autocast_ctx:
...
autocast 在这里真正起作用的地方,主要是 forward 和 loss 计算. 它负责让这些计算尽量以合适的低精度进行,从而达到“混合精度训练”的效果.
Q5: GradScaler 到底在缩放什么?
GradScaler 主要用于 float16 混合精度训练。因为 float16 的数值范围较小,梯度太小时可能下溢成 0,导致训练不稳定。它和梯度剪裁不是一件事情
它的核心思路是: 先把 loss 放大,这样反向传播时得到的梯度也会一起被放大,从而尽量避免过小的梯度在 float16 下直接下溢成 0.
对应代码就是:
# src/minimind_learning/trainer/train_pretrain.py
# 这里的 `enabled=(args.dtype == 'float16')` 就是说,只有当我们使用 `float16` 时才启用 `GradScaler`.
scaler = torch.cuda.amp.GradScaler(enabled=(args.dtype == 'float16')) #自动缩放 loss,防止梯度下溢
# 反向传播时,先用 `scaler.scale(loss)` 把 loss 放大,再调用 `backward()`.
scaler.scale(loss).backward()
所以更准确地说,GradScaler 表面上是在 scale loss,但它真正想保护的是 backward 过程中产生的梯度.
等真正更新参数之前,再把梯度恢复到正常尺度:
scaler.unscale_(optimizer)
这一步之后,参数上的 .grad 才重新回到“真实梯度大小”. 也正因为如此,如果后面还要做梯度裁剪,就必须放在 unscale_ 之后.
然后才能进行梯度裁剪:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
最后再通过 scaler.step() 和 scaler.update() 执行更新并调整缩放因子:
scaler.step(optimizer)
scaler.update()
所以这一整套顺序其实是:
scale(loss)
先把 loss 放大backward()
让放大后的 loss 参与反向传播unscale_(optimizer)
在真正更新前,把梯度恢复到正常尺度clip_grad_norm_(...)
如果要做梯度裁剪,在真实梯度上裁剪scaler.step(optimizer)
执行参数更新scaler.update()
动态调整缩放因子
这套顺序很重要. 如果要做梯度裁剪,应该先 unscale_,再 clip_grad_norm_. 否则裁剪的就是被放大后的梯度,阈值就失去了原本的意义.
Q6:scaler.scale(loss).backward() 应该放在 autocast 里面吗?
一般来说,autocast 包住 forward 和 loss 计算,而 backward 放在 autocast 外面。
MiniMind 里的写法是:
with autocast_ctx:
res = model(X)
loss = loss_fct(
res.logits.view(-1, res.logits.size(-1)),
Y.view(-1)
).view(Y.size())
loss = (loss * loss_mask).sum() / loss_mask.sum()
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
这样写是合理的. autocast 主要影响的是 forward 过程和 loss 计算过程中的算子精度选择. 反向传播会沿着 forward 过程中记录下来的计算图进行,它并不需要再额外包在 autocast 里面.
所以这里可以把两者的分工理解成:
autocast负责决定 forward 和 loss 计算时“用什么精度算”GradScaler负责在 backward 前后处理梯度缩放,尽量避免float16下的梯度下溢
如果把整个过程串起来,更完整的逻辑其实是:
- 进入
autocast_ctx - 做 forward
- 计算 loss
- 退出
autocast_ctx - 用
scaler.scale(loss).backward()做反向传播 - 用
scaler.unscale_(optimizer)恢复真实梯度 - 如果需要,再做梯度裁剪
- 最后
scaler.step()和scaler.update()
autocast 和 GradScaler 就是配合关系,而不是二选一的关系:
autocast解决“前向计算尽量安全地用低精度”GradScaler解决“反向传播时低精度梯度可能下溢”- grad_clip 解决“梯度可能过大导致训练不稳定”
三者的配合顺序至关重要
Q6.1 Minimind 中完整代码片段:
# src/minimind_learning/trainer/train_pretrain.py
def train_epoch(epoch, loader, iters, start_step=0, wandb=None):
'''
epoch: 有 num_epochs 个 epoch
steps: 每个 epoch 有 steps_per_epoch 个 batch
iters: iters = steps_per_epoch 最大迭代步数
'''
loss_fct = nn.CrossEntropyLoss(reduction='none')
start_time = time.time()
for step, (X, Y, loss_mask) in enumerate(loader, start=start_step + 1):
# B batch size L seq_len
X = X.to(args.device) #[B,L-1] #去掉最后一个 token的index
Y = Y.to(args.device) #[B,L-1] #去掉第一个
loss_mask = loss_mask.to(args.device) #[B,L-1]
# 手动修改LR
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
with autocast_ctx:
res = model(X) #CausalLMOutputWithPast #[batch_size, seq_len, vocab_size (logit/raw score)]
loss = loss_fct(
res.logits.view(-1, res.logits.size(-1)), # [batch_size * seq_len ,vocab_size]
Y.view(-1) #[batch_size * seq_len]
).view(Y.size()) #[batch_size , seq_len]
loss = (loss * loss_mask).sum() / loss_mask.sum()
if res.aux_loss : loss += res.aux_loss
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
# accumulation_steps 原本大batch拆成小batch 但是为了保证梯度的稳定性(降低方差) 还是需要用大batch估计梯度 所以把小batch的梯度保留然后拼回去
# 相当于一个正常batch结束了 要更新一下
if (step + 1) % args.accumulation_steps == 0:
scaler.unscale_(optimizer) #作用:把梯度从 GradScaler 的缩放状态恢复到正常大小。在混合精度训练中,scaler.scale(loss).backward() 会把梯度放大,以避免 fp16 下的数值下溢。在做梯度裁剪 或其他需要真实梯度值的操作前,必须先调用 unscale_。
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip) #对梯度进行 裁剪,防止梯度爆炸。
scaler.step(optimizer) # :执行一次参数更新。和普通的 optimizer.step() 不同,scaler.step() 会检查梯度是否为 NaN 或 Inf(数值不稳定)。
scaler.update() #动态调整缩放因子。如果梯度稳定,GradScaler 会逐步增大缩放因子,提高精度利用率。如果出现溢出(NaN/Inf),它会减小缩放因子,保证安全。
optimizer.zero_grad(set_to_none=True)#清空梯度,为下一次迭代做准备。set_to_none=True 会把 .grad 设为 None 而不是 0,这样更节省显存和计算开销。下次反向传播时,PyTorch 会重新分配梯度张量。
Q7: 为什么需要梯度裁剪?
训练深层网络时,梯度有时会突然变得非常大,这就是常说的梯度爆炸。梯度爆炸会让参数更新过猛,轻则 loss 剧烈波动,重则直接出现 NaN 或 Inf。
梯度裁剪的思想是限制梯度范数。如果梯度整体范数超过阈值,就把它缩放回阈值范围内。
MiniMind 默认的裁剪阈值是:
parser.add_argument("--grad_clip", type=float, default=1.0, help="梯度裁剪阈值")
对应训练循环中的:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
它不会改变梯度方向,只会限制梯度大小。因此它更像是给训练过程加了一个安全阀。
Q8: 为什么要做梯度累积?
梯度累积的目标是模拟更大的 batch size。
如果显存不够,我们无法一次放入很大的 batch。但可以把一个大 batch 拆成多个小 batch,分别 forward 和 backward,让梯度先累积在参数的 .grad 里,等累积到一定步数后再更新一次参数。
这部分的实践技术细节,和理论方面的内容,我们分别在上一小节的分布式训练,和上一章节Effective Batch size也有涉及.相关的内容可以先参阅前述章节.
MiniMind 里默认:
parser.add_argument("--accumulation_steps", type=int, default=8, help="梯度累积步数")
训练时先把 loss 除以累积步数:
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
然后每隔 accumulation_steps 才执行一次 optimizer step:
if (step + 1) % args.accumulation_steps == 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
loss = loss / args.accumulation_steps
特别注意,这里需要把 loss 除以 accumulation_steps 是为了让累积后的梯度尺度接近真正的大 batch 平均梯度。如果不除,累积后的梯度会被放大,等价于改变了学习率。
Q8.1: PyTorch 里的 backward()、optimizer.step() 和 zero_grad() 分别是什么意思? 它们又是怎么配合完成梯度累积的?
这一组操作几乎是所有 PyTorch 训练循环里最核心的三步,但它们各自负责的事情其实不一样:
backward()
负责反向传播,并把当前这一步算出来的梯度累加到参数的.grad上.optimizer.step()
负责读取当前参数上的.grad,然后按照优化器规则去更新参数.optimizer.zero_grad()
负责把参数上旧的梯度清掉,让下一轮计算从干净状态开始.
这里一个很重要的细节是: PyTorch 默认不会在每次迭代后自动清空梯度.也就是说,如果你连续调用多次 backward(),而中间不 zero_grad(),那么新的梯度就会继续累加到旧的 .grad 上.
这也是梯度累积能成立的根本原因.
所以从机制上看,梯度累积并不是什么额外的黑盒功能,而是利用了 PyTorch 默认“梯度会累加,不会自动清空”这个特性.
可以把一个最基本的训练循环理解成:
loss.backward()optimizer.step()optimizer.zero_grad()
而梯度累积做的事情,其实就是把“每次 backward 之后立刻更新参数”这件事延后:
- 多次调用
backward() - 中间先不
optimizer.step() - 也先不
optimizer.zero_grad() - 让多次 backward 的结果都累积在
.grad里 - 等累积够了,再执行一次
optimizer.step() - 最后再
optimizer.zero_grad()
也就是说,梯度累积不是因为“不调用 optimizer.step() 就会自动保留梯度”,而是因为 PyTorch 本来就不会自动清空梯度,真正负责清空的是 zero_grad().
所以更准确地说:
backward()负责“把梯度加上去”optimizer.step()负责“拿当前梯度去更新参数”zero_grad()负责“把旧梯度清掉”
Q8.2: 梯度累积会带来不稳定吗? 如果会,通常怎么避免?
梯度累积本身不等于梯度爆炸,但如果处理不当,它确实会让训练更容易不稳定.
最常见的风险有两个:
- 没有把 loss 除以
accumulation_steps
如果你想累积 8 步,但每一步都直接对原始 loss 做 backward,那最后参数上的 .grad 大约就会变成 8 个 micro-batch 梯度的和. 这样梯度尺度会明显变大,效果上很像学习率也被一起放大了,训练就更容易抖动甚至发散.
所以通常要写:
loss = loss / args.accumulation_steps
这样累积完成之后,梯度尺度会更接近真正的大 batch 平均梯度.
- 梯度累积后,更大的梯度会在
.grad里持续保留
因为梯度累积的过程就是不断把多步的梯度往 .grad 里加,所以如果某一步梯度本身就特别大,它也会被继续保留下来. 在模型本来就不稳定、学习率偏大,或者混合精度下数值不太稳的时候,这种影响会更明显.
通常的避免办法有这几个:
- 把 loss 除以
accumulation_steps,控制梯度尺度 - 在真正更新参数之前做梯度裁剪
- 混合精度训练时,先
unscale_()再做梯度裁剪 - 不要把学习率设置得过大
这里还要注意一个顺序问题: 梯度裁剪通常应该放在“累积完成之后”,而不是每个 micro-batch 的 backward 之后.
也就是说,更常见的做法是:
- 多次 backward,先把梯度累积起来
- 累积完成后,先
unscale_(optimizer)
如果使用了混合精度 - 对最终要用于更新参数的总梯度做
clip_grad_norm_(...) - 再执行
optimizer.step()
原因在于,我们真正想控制的,是“这一次参数更新实际会用到的总梯度”,而不是某一个 micro-batch 的局部梯度. 如果每一步都先裁一遍再去累积,那得到的就不再是原本那个大 batch 梯度的近似了.
Q9: 为什么 optimizer、learning rate 和 batch size 不只算工程参数?
优化器、学习率和数据设置决定了参数怎样更新,也决定了每次更新用什么样的数据估计梯度。它们比 checkpoint、可视化更接近训练理论,所以单独放到上一节讨论。
在实际看训练代码时,可以先把这里当作一个连接点:本节继续关注训练能不能稳定执行,而优化器、学习率、数据集和 batch size 的理论含义,会在上一节中单独展开。
Q10: 如何恢复训练, checkpoint 保存什么?
训练不是一次性跑完就结束的。尤其是 pretrain,常常需要中断、恢复、换机器、换 GPU 数量。因此 checkpoint 很重要。
先从更一般的角度看,如果我们希望训练能够真正从中断处继续下去,那通常至少要保存下面这些东西:
- 模型权重
这是最基本的一项. 不管是推理还是继续训练,都首先需要模型当前的参数.
- 优化器状态
如果只恢复模型权重,但不恢复优化器状态,那训练虽然还能继续跑,但优化器内部的动量、二阶统计量这些信息都丢了. 这样后续的训练轨迹通常就和中断前不一致了.
- 混合精度相关状态
如果训练里用了 GradScaler,那最好也把 scaler.state_dict() 一起保存下来. 否则恢复训练后,梯度缩放会重新从头开始,数值行为可能和中断前不一致.
- 训练进度
最常见的是保存 epoch 和 step. 这样恢复训练时,至少可以知道是从哪个 epoch、哪个 step 继续.
- 数据进度
这一点有时容易被忽略. 因为训练恢复不只是“模型接着算”,还包括“数据读到哪里了”.
最简单的情况下,epoch + step 往往已经够用了. 但如果数据读取方式更复杂,比如 sampler 状态更复杂、数据是流式读取的、或者中间做了 packing,那严格来说还可能需要保存更完整的数据管线状态.
- 其他训练状态
比如分布式训练时的 world_size,可视化实验的 run id,以及本次训练的配置快照. 这些内容虽然不直接参与参数更新,但对恢复实验和复现实验都很重要.
所以也可以换个角度理解:
- 如果只是为了推理或者后续加载模型,保存模型权重就够了
- 如果是为了真正恢复训练,那就应该保存完整训练状态,而不只是模型参数
MiniMind 这里实际上保存了两类东西:
- 半精度模型权重:方便推理或后续加载。
- resume checkpoint:保存模型、优化器、训练进度、可视化 run id 等,用于继续训练。
对应代码在 lm_checkpoint 中:
# src/minimind_learning/trainer/trainer_utils.py
resume_data = {
'model': state_dict,
'optimizer': optimizer.state_dict(),
'epoch': epoch,
'step': step,
'world_size': dist.get_world_size() if dist.is_initialized() else 1,
'wandb_id': wandb_id
}
这里只截了一部分核心字段,但结合完整代码来看,MiniMind 的保存逻辑其实分成两层:
第一层是保存模型权重:
state_dict = model.module.state_dict() if isinstance(model, DistributedDataParallel) else model.state_dict()
torch.save({k: v.half() for k, v in state_dict.items()}, ckp_tmp)
这里保存的是一份半精度权重. 它更适合“模型加载”这个目的,比如推理或者后续再继续作为初始权重使用.
第二层是保存 resume checkpoint:
resume_data = {
'model': state_dict,
'optimizer': optimizer.state_dict(),
'epoch': epoch,
'step': step,
'world_size': dist.get_world_size() if dist.is_initialized() else 1,
'wandb_id': wandb_id
}
for key, value in kwargs.items():
if value is not None:
if hasattr(value, 'state_dict'):
resume_data[key] = value.state_dict()
else:
resume_data[key] = value
这里比较关键的一点是: resume_data 不只保存模型和优化器,它还会继续把 kwargs 里传进来的训练状态一起保存. 在 train_pretrain.py 里,调用 lm_checkpoint(...) 时也把 scaler 传进去了,所以恢复训练时混合精度状态也能一起恢复.
所以从实际效果看,MiniMind 这里保存的内容主要包括:
- 模型权重
- 优化器状态
GradScaler状态epochstepworld_size- 可视化 run id
然后再看加载逻辑:
ckp_data = lm_checkpoint(lm_config, weight=args.save_weight, save_dir='../checkpoints') if args.from_resume==1 else None
if ckp_data:
model.load_state_dict(ckp_data['model'])
optimizer.load_state_dict(ckp_data['optimizer'])
scaler.load_state_dict(ckp_data['scaler'])
start_epoch = ckp_data['epoch']
start_step = ckp_data.get('step', 0)
这里做的事情也很清楚:
- 恢复模型参数
- 恢复优化器状态
- 恢复
GradScaler状态 - 恢复
epoch和step
也就是说,它恢复的不是“某一份权重文件”,而是一整套训练状态.
还有一个细节值得注意. MiniMind 并没有直接把 sampler 的完整状态保存下来,而是主要依靠 epoch + step 来恢复训练进度,并在恢复时通过 SkipBatchSampler 跳过前面的 batch.
这说明它对“数据进度”的恢复思路是:
- 用
epoch确定恢复到第几个训练轮次 - 用
step确定当前 epoch 里已经跑到了哪里 - 再通过跳过前面 batch 的方式,近似恢复数据读取位置
这种做法在很多普通训练脚本里已经够用了,实现上也比较简单. 但如果数据管线特别复杂,那严格来说,还可能需要更完整的数据状态恢复机制.
这里还可以单独补充一下 world_size 的作用. 在 MiniMind 这份代码里,world_size 并不是训练主流程里持续依赖的状态,它主要是在恢复 checkpoint 时,用于处理“保存时的 GPU 数量”和“恢复时的 GPU 数量”不一致的情况:
saved_ws = ckp_data.get('world_size', 1)
current_ws = dist.get_world_size() if dist.is_initialized() else 1
if saved_ws != current_ws:
ckp_data['step'] = ckp_data['step'] * saved_ws // current_ws
也就是说,MiniMind 保存 world_size,主要是为了在 GPU 数量发生变化时,对 step 做一个近似换算. 它并没有进一步恢复更完整的分布式数据状态,所以这更像是一种实用的工程补偿,而不是严格意义上的数据进度恢复.
Q10.1: MiniMind 在单卡和分布式场景下,是怎么恢复数据进度的?
先直接看训练循环里的代码:
for epoch in range(start_epoch, args.epochs):
train_sampler and train_sampler.set_epoch(epoch)
if epoch == start_epoch and start_step > 0:
batch_sampler = SkipBatchSampler(
train_sampler or range(len(train_ds)),
args.batch_size,
start_step + 1
)
loader = DataLoader(
train_ds,
batch_sampler=batch_sampler,
num_workers=args.num_workers,
pin_memory=True
)
train_epoch(epoch, loader, len(loader) + start_step + 1, start_step, wandb)
else:
loader = DataLoader(
train_ds,
batch_size=args.batch_size,
shuffle=(train_sampler is None),
sampler=train_sampler,
num_workers=args.num_workers,
pin_memory=True
)
train_epoch(epoch, loader, len(loader), 0, wandb)
这段代码的思路其实很清楚:
- 先通过
start_epoch决定从第几个 epoch 开始恢复 - 如果是恢复训练,并且当前 epoch 里已经跑过一部分 step,那就通过
SkipBatchSampler跳过前面的 batch - 如果不是恢复训练,那就正常创建
DataLoader
这里有一个写法很巧:
train_sampler or range(len(train_ds))
它的意思是:
- 如果当前是分布式训练,那就用
train_sampler - 如果当前是单卡训练,
train_sampler是None,那就退回到普通的顺序索引range(len(train_ds))
所以 MiniMind 其实用同一套恢复逻辑,同时兼容了单卡和分布式两种场景:
- 单卡时,根据
epoch + step跳过前面已经训练过的 batch - 分布式时,先由
DistributedSampler决定当前进程应该读取哪些样本,再在这个基础上继续跳过已经训练过的 batch
从工程上看,这是一个比较实用的方案. 它不需要保存完整的 sampler 内部状态,也不需要保存 DataLoader 的全部运行时信息,只要保存:
epochstep- 当前训练时的
world_size
再配合 SkipBatchSampler,通常就已经能把训练大致恢复到之前的位置.
不过它的局限也很明显: 这种恢复方式更像是在“近似恢复训练位置”,而不是“精确恢复整个数据管线状态”:
MiniMind 的数据恢复不是严格意义上的 sampler 状态恢复。它主要以 epoch 为锚点,在恢复时先通过 set_epoch(epoch) 重建当前轮次的数据顺序,再结合 step 和 SkipBatchSampler 跳过前面的 batch。因此它比单纯的 epoch-level 恢复更细一些,但仍然更接近一种“基于 epoch 的 step 级近似恢复”,而不是完全精确的 batch-level 恢复。
如果数据管线更复杂,通常还可能需要额外保存下面这些信息:
- sampler 的随机状态
- 当前 epoch 对应的 shuffle 顺序
- 流式数据读取时的游标位置
- packing / buffer 中还没消费完的样本片段
- 数据增强或随机裁剪使用的随机数状态
可以举一个更复杂的例子. 假设你的数据不是普通的 map-style dataset,而是一个流式读取的文本管线:
- 数据来自多个 shard
- 每个 shard 内部还在不断顺序读取
- 中间会做 document packing
- packing buffer 里可能还残留一些还没拼完的 token
这种情况下,如果只保存 epoch + step,恢复训练时虽然知道“大概跑了多少步”,但并不知道:
- 当前到底读到了哪个 shard
- shard 内部读到了哪一条样本
- packing buffer 里还剩下哪些 token
这时更完整的做法通常是把数据管线自己的状态也做成一个 state_dict,例如:
resume_data = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"scaler": scaler.state_dict(),
"epoch": epoch,
"step": step,
"sampler_state": sampler.state_dict(),
"data_cursor": datapipe.cursor_state(),
"packing_buffer": packer.state_dict(),
}
恢复时再分别加载这些状态:
sampler.load_state_dict(ckp_data["sampler_state"])
datapipe.restore_cursor(ckp_data["data_cursor"])
packer.load_state_dict(ckp_data["packing_buffer"])
这样做的代价是实现更复杂,但好处是恢复训练时会更接近真正的“无缝续训”.
所以这一节最后可以压缩成一句话:
checkpoint 不只是“把模型存下来”,更重要的是把“继续训练所需的状态”一起存下来. 如果只保存模型权重,那更像是保存了一份模型快照; 如果连优化器、scaler、epoch、step 这些都一起恢复,那才更接近真正意义上的断点续训.
Q11: Epoch、Step、Iteration, Batch 这些概念是怎么对应的?
这一组概念在训练代码里非常常见,但不同项目、不同文章里的叫法并不总是完全一致. 有的人把 step 当成“读了一个 batch”,有的人把 step 当成“做了一次参数更新”; 有的人把 iteration 和 step 混用,有的人又会单独区分 global step、micro step、update step.
所以这一节最好先把这些术语尽量定义清楚,再放回训练循环里看它们是怎么运转的.
1. 先定义最基本的几个概念
sample
最小的数据单位. 比如一条训练样本、一段文本、一个句子对,都可以看成一个 sample.
batch
一次 forward / backward 里一起送进模型的一组 sample.
如果 batch_size=32,那通常就是一次送 32 条 sample 进去.
不过在大模型训练里,batch 这个词有时并不够精确,因为它可能指的是:
- 单卡上的一个 local batch
- 梯度累积里的一个 micro-batch
- 所有卡合起来的 global batch
所以只说 batch 时,最好结合上下文判断.
epoch
指“把整个训练集大致跑一遍”.
如果数据集大小固定,一个 epoch 通常表示所有样本都被遍历过一次.
在分布式训练里,更准确地说,是所有进程配合起来,把这一轮数据各自处理完,合起来相当于把整个数据集跑过一遍.
iteration
这个词通常指训练循环中的“一次迭代”.
很多时候它和“读一个 batch,做一次 forward/backward”是对应的.
但要注意,它的用法并不绝对统一. 有些代码里会把 iteration 直接等同于 step,有些地方又会单独区分.
step
这是最容易混的一个词.
在很多训练代码里,step 经常有两种常见用法:
- 表示“训练循环往前走了一次”,也就是处理了一个 batch
- 表示“参数真正更新了一次”,也就是执行了一次
optimizer.step()
所以看代码时,一定要结合上下文判断它到底指的是哪一种.
2. 放到 PyTorch 训练循环里看,这些概念通常怎么对应?
先看一个最基础的训练循环:
for epoch in range(num_epochs):
for step, batch in enumerate(loader):
loss = model(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
在这段最简单的代码里:
- 外层
for epoch ...对应 epoch - 内层
for step, batch ...的每一次循环,通常可以看成一次 iteration - 这里的
step也通常等于“一次 batch 迭代” - 因为每次循环都调用了
optimizer.step(),所以这里的step也同时等于“一次参数更新”
也就是说,在没有梯度累积时:
- 一个 iteration 通常处理一个 batch
- 一个 batch 通常对应一次 backward
- 一次 backward 通常也就对应一次
optimizer.step()
这时候很多人把 iteration、step、update step 混着说,问题通常也不大.
3. 一旦有了梯度累积,这些概念就不能再混着用了
假设现在有:
batch_size = 8accumulation_steps = 4
训练循环可能会变成:
for epoch in range(num_epochs):
for step, batch in enumerate(loader):
loss = model(batch)
loss = loss / accumulation_steps
loss.backward()
if (step + 1) % accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
这时就要明确区分两类 step:
- data step / iteration step
指内层循环走了一次,处理了一个 micro-batch - update step / optimizer step
指真正执行了一次参数更新
比如上面的例子里:
- loader 每循环 1 次,处理 1 个 batch
- 但每 4 次循环,才执行 1 次
optimizer.step()
所以:
- 4 个 batch iteration
- 4 次 backward
- 1 次参数更新
这时候如果还只是笼统地说 “step”,就很容易混乱.
4. 再补几个大模型训练里常见的概念
micro-batch
梯度累积时,每次真正送进模型做 forward / backward 的那一小批数据,通常就叫 micro-batch.
也就是说,在做梯度累积时,内层循环里每次读到的 batch,很多时候其实更准确地说应该叫 micro-batch.
local batch size
单个进程、单张卡上,每次 forward 实际处理的数据量.
global batch size
所有卡、再乘上梯度累积之后,一次参数更新等效看到的总 batch size.这个等效于之前提到的 effective batch size, 更强调“从优化角度看,这次更新等效使用了多大的 batch”.
如果定义:
- 记每张卡上的 batch size 为 \( B_{local} \)
- 记 GPU 数量为 \( N_{gpu} \)
- 记梯度累积步数为 \( N_{acc} \)
那么 global batch size 通常可以写成:
\[ B_{global} = B_{local} \times N_{gpu} \times N_{acc} \]
这里:
- \( B_{local} \) 表示单卡每次 forward 的 batch size
- \( N_{gpu} \) 表示并行使用的 GPU 数量
- \( N_{acc} \) 表示梯度累积步数
这个公式有助于把“单卡 batch”“多卡 batch”“梯度累积后的等效 batch”统一起来理解.
5. 结合 MiniMind 的代码,这些词更准确地应该怎么叫?
MiniMind 的训练循环里有:
for step, (X, Y, loss_mask) in enumerate(loader, start=start_step + 1):
...
scaler.scale(loss).backward()
if (step + 1) % args.accumulation_steps == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
这里的 step 更接近:
- 当前 dataloader 迭代到了第几个 batch
- 也就是第几个 micro-batch iteration
它不完全等于“第几次参数更新”,因为参数更新只在满足:
(step + 1) % args.accumulation_steps == 0
时才会发生.
所以如果按更严格的术语来讲:
epoch: 第几个训练轮次step: 当前 epoch 里处理到第几个 dataloader batchiteration: 在这里基本可以近似理解成一次 dataloader 循环optimizer step/update step: 真正执行参数更新的时刻
也就是说,MiniMind 这里的 step 更接近“batch step”或“iteration step”,而不是严格意义上的“update step”.
6. 所以这几个概念在训练里一般是怎么运转的?
可以把一个更完整的训练过程概括成这样:
- 外层按 epoch 循环
- 每个 epoch 内,
DataLoader不断产生 batch / micro-batch - 每来一个 batch,就做一次 forward 和 backward
- 如果不开梯度累积,通常每个 batch 后都立即
optimizer.step() - 如果开了梯度累积,那就会先积累多个 micro-batch 的梯度,再统一
optimizer.step() - 所以 iteration 的次数通常大于等于 update step 的次数
如果只记一句最实用的话,可以记成:
- epoch: 数据集跑了第几轮
- batch / micro-batch: 一次 forward / backward 处理多少数据
- iteration: 内层训练循环往前走了一次
- optimizer step / update step: 参数真正更新了一次
而一旦进入分布式训练和梯度累积,最容易混乱的地方就是:
“一个 batch iteration” 不一定等于 “一次参数更新 step”. 这也是为什么很多项目后面会额外引入 global_step、update_step 这类更明确的命名.
Q12: 可视化怎么做?
MiniMind 训练脚本里记录了 loss、learning rate 和预计剩余时间:
if wandb:
wandb.log({"loss": current_loss, "lr": current_lr, "epoch_Time": eta_min})
这里代码里变量名叫 wandb,实际导入的是 swanlab:
import swanlab as wandb
不管使用 SwanLab、WandB 还是 TensorBoard,核心目的都一样:把训练过程从终端里解放出来,让我们能看到曲线。
Q12.1 Wandb完整API示例
不过如果继续往代码层面看,这一类可视化工具通常至少会涉及两类最基本的 API:
- 初始化一个实验 run
- 在训练过程中不断往这个 run 里记录数据
MiniMind 里初始化的代码是:
if args.use_wandb and is_main_process():
import swanlab as wandb
wandb_id = ckp_data.get('wandb_id') if ckp_data else None
resume = 'must' if wandb_id else None
wandb_run_name = f"MiniMind-Pretrain-Epoch-{args.epochs}-BatchSize-{args.batch_size}-LearningRate-{args.learning_rate}"
wandb.init(project=args.wandb_project, name=wandb_run_name, id=wandb_id, resume=resume)
这里虽然变量名写的是 wandb,但实际导入的是 swanlab,所以更准确地说,这里用的是一套 WandB 风格的接口去记录实验.
这里几个参数可以顺手解释一下:
project
表示这次实验属于哪个项目. 一般同一类实验会放在同一个 project 下面,方便后面统一比较.name
表示当前这个 run 的显示名称. 它通常更适合给人看,比如把 epoch、batch size、learning rate 直接拼进名字里.id
表示这个 run 的唯一标识. 如果恢复训练时还想继续往原来的实验里写数据,这个 id 就很重要.resume
表示是否继续已有的 run. 这里resume='must'的意思可以理解成: 如果已经有这个 run,那就强制接着它写; 不要新建一个同名但不连续的实验.
这里还有一个分布式训练里的关键点:
if args.use_wandb and is_main_process():
为什么只在主进程记录日志? 因为在分布式训练里,会有很多个进程同时跑训练循环. 如果每个进程都自己 init 和 log,那同一组指标就会被重复记录很多次,曲线也会变得很乱.
所以更常见的做法是:
- 只让主进程负责可视化记录
- 其他进程正常训练,但不单独写日志
然后在训练过程中,通过 wandb.log(...) 不断追加指标:
if wandb:
wandb.log({"loss": current_loss, "lr": current_lr, "epoch_Time": eta_min})
wandb.log(...) 最常见的用法就是记录一组标量.
每调用一次,平台就会把这些值追加到当前 run 的时间序列里,最后画成曲线.
所以这段代码本质上记录的是三条标量曲线:
losslrepoch_Time
再结合 Q10 里的 checkpoint 恢复逻辑,这里还有一个细节很值得注意: MiniMind 会把 wandb_id 一起保存进 resume checkpoint. 这样恢复训练时,可以重新拿回原来的 run id,再继续往同一个实验里写数据.
这里还有一个很自然的问题: 如果第一次训练时 wandb_id 本来就是 None,那保存 checkpoint 的时候这个 id 又是从哪里来的?
答案是: 第一次 wandb.init(...) 时,即使传进去的 id 是 None,平台也会自动新建一个 run,并给它分配一个真正的 run id. 之后在保存 checkpoint 时,MiniMind 再从当前 run 对象里把这个 id 取出来保存.
对应代码在 lm_checkpoint(...) 里:
wandb_id = None
if wandb:
if hasattr(wandb, 'get_run'):
run = wandb.get_run()
wandb_id = getattr(run, 'id', None) if run else None
else:
wandb_id = getattr(wandb, 'id', None)
所以这件事的完整逻辑其实是:
- 第一次训练时,
wandb_id可以是None wandb.init(...)会自动创建一个新的 run- 新 run 创建好之后,平台内部就已经有了真正的
id - 保存 checkpoint 时,再把这个
id读出来,写进 resume checkpoint - 下次恢复训练时,再把这个旧
id传回wandb.init(..., id=..., resume='must')
也就是说,可视化的断点续训并不是“重新开一个实验再接着看”,而是:
- 先从 checkpoint 里读出原来的
wandb_id - 再
wandb.init(..., id=wandb_id, resume='must') - 让后续日志继续追加到原来的 run 上
这样恢复训练之后,曲线才会是连续的.
除了记录标量之外,WandB 风格的接口通常还支持记录别的数据类型. 比如比较常见的还有:
wandb.log({"samples": wandb.Text("hello world")})
这个用法适合记录文本内容,比如模型生成样例、prompt 和 response、某一步的输出片段.
再比如:
wandb.log({"pred_table": wandb.Table(data=[["input", "output"]], columns=["x", "y"])})
Table 适合记录结构化结果,比如若干条样本的输入、输出、标签、分数. 后面做对比分析时会比较方便.
所以如果只记最常用的几种 API,大概可以记成:
wandb.init(...)
创建或恢复一个实验 runwandb.log({...})
记录标量或其他可视化数据wandb.Text(...)
记录文本wandb.Table(...)
记录表格化结果
Q13: Tips:
Q13.1: 训练里经常因为 tensor 的 shape 或 dtype 报错,有没有办法尽量提前检查?
这是训练代码里非常常见的一类问题. 尤其是写 dataset、collate、model forward、loss 对齐这些地方的时候,一旦 tensor 的 shape 或 dtype 没对上,往往要等跑到中间某一层才会报错,而且报错位置还不一定是问题真正出现的地方.
先说结论: 在 PyTorch 里,这类问题很难做到像静态类型语言那样“彻底静态检查”. 但我们完全可以通过一些工程手段,把很多错误尽量提前暴露出来.
最常见的思路有下面几类:
- 给关键函数补类型注解
最基础的一层是先把普通 Python 类型关系理清楚,比如函数输入输出、可选值、配置对象、batch 结构这些.
这类检查虽然不能直接证明 tensor shape 一定正确,但至少能减少很多“参数类型传错”“返回值结构不一致”这类问题.
- 在关键边界加 shape / dtype 断言
这是最实用的一招.
因为训练代码里最容易出问题的地方,通常都集中在几个边界上:
- dataset 输出
- collate_fn 输出
- model 输入
- logits 和 labels 送进 loss 之前
比如可以直接写:
assert X.ndim == 2
assert Y.ndim == 2
assert X.shape == Y.shape
assert loss_mask.shape == Y.shape
assert X.dtype == torch.long
assert Y.dtype == torch.long
如果模型输出再进一步检查:
assert res.logits.shape[:2] == Y.shape
assert res.logits.size(-1) == vocab_size
这样做的价值是:
与其等到后面的 view、loss_fct、matmul 里报一个很绕的错,不如在边界上更早地把问题拦下来.
- 给 batch 封装成更明确的数据结构
如果训练里到处都在传 (X, Y, mask) 这种裸 tuple,就很容易把顺序写错,或者后面自己都忘了第三个张量到底是什么意思.
更稳一点的写法是把 batch 封装成 dataclass 或者命名结构,比如:
from dataclasses import dataclass
import torch
@dataclass
class LMTrainingBatch:
input_ids: torch.Tensor
labels: torch.Tensor
loss_mask: torch.Tensor
这样一来,接口语义会更清楚,后面也更容易统一加 validate() 一类的检查逻辑.
- 对 dataset / dataloader / forward 写最小测试
很多 shape 问题其实没必要等到正式训练时才发现.
只要写几个很小的测试,比如:
- dataset 取一条样本时 shape 对不对
- dataloader 取一个 batch 时 shape 和 dtype 对不对
- model forward 输出 shape 对不对
- loss 计算能不能正常对齐
通常就已经能提前挡掉一大批错误.
- 如果还想更严格,可以引入带 shape 的类型注解工具
比如 jaxtyping、torchtyping 这类工具,可以把 tensor 的维度约定直接写进函数签名里.
它们更像是“类型注解 + 运行时检查”的组合,虽然不算完全静态检查,但能让接口变得清楚很多.
例如:
from jaxtyping import Int, Float
from torch import Tensor
def forward(
x: Int[Tensor, "batch seq"],
mask: Float[Tensor, "batch seq"]
) -> Float[Tensor, "batch seq vocab"]:
...
这样至少能把“这个函数期望什么 shape”明确写出来.
所以如果只总结成最实用的一套做法,我会更推荐:
- 用普通类型注解把训练代码结构理顺
- 在 dataset / collate / forward / loss 前加 shape 和 dtype 断言
- 给 batch 封装成更明确的数据结构
- 写几个最小单元测试
换句话说,在 PyTorch 里,shape / dtype 问题很难被纯静态检查彻底解决. 但只要把关键边界守住,很多训练时才会爆出来的问题,其实都能更早发现.
Q13.2: 训练里经常出现 CPU / GPU device 不一致报错,这种问题怎么尽量减少?
这一类报错也非常常见. 它和 shape / dtype 问题有点像: 真正的问题往往出在前面,但报错经常是在某个算子真正开始计算时才出现.
先说一个最核心的原则:
- 参与同一次计算的 tensor,通常必须在同一个 device 上
- 但日志、可视化、打印、保存这些操作,又经常需要把 tensor 转回 CPU
所以很多 device 报错,本质上不是“不会用 GPU”,而是“训练计算流”和“日志 / 可视化流”混在了一起.
最常见的几类问题有:
- 模型在 GPU,但输入数据还在 CPU
labels、loss_mask这种辅助 tensor 忘了.to(device)- 中间手动新建 tensor 时,默认建在 CPU
- tensor 还在 GPU 上,就直接拿去
numpy()、可视化或者打印 - 记录日志时,直接把 GPU tensor 塞给可视化工具
比较实用的做法通常有下面几条:
- batch 一进入训练循环,就统一搬到 device
比如:
X = X.to(args.device)
Y = Y.to(args.device)
loss_mask = loss_mask.to(args.device)
这一点非常重要. 最好形成一个固定习惯:
所有参与 forward 和 loss 计算的 tensor,都在训练循环入口统一 .to(device).
- 新建 tensor 时,尽量继承已有 tensor 的 device
比如下面这种写法就很容易埋坑:
mask = torch.zeros(B, L)
因为它默认会建在 CPU 上.
更稳一点的写法是:
mask = torch.zeros(B, L, device=X.device)
或者:
mask = torch.zeros_like(X)
这样可以尽量避免“模型和输入都在 GPU,但中间新建的 tensor 突然跑到 CPU”这种问题.
- 做日志、可视化、保存时,尽量先转成 CPU 友好的形式
如果只是一个标量,最常见的做法是:
loss_value = loss.item()
如果是张量还要继续送去 numpy() 或 matplotlib,更常见的顺序是:
arr = tensor.detach().cpu().numpy()
这里的顺序一般是:
detach()
先脱离计算图cpu()
再搬回 CPUnumpy()
最后转成 NumPy
如果 tensor 还在 GPU 上就直接 numpy(),通常就会报错.
- 给 wandb / swanlab 记录数据时,尽量传 Python 标量或 CPU 数据
比如:
wandb.log({
"loss": loss.item(),
"lr": current_lr,
})
如果你直接把一个 GPU tensor 丢进去,有些时候可视化工具会帮你处理,有些时候又会引出新的问题. 所以更稳的做法通常是:
- 标量用
.item() - 数组用
.detach().cpu() - 图片、表格、文本也尽量先转成更明确的 CPU 侧格式
- 尽量统一 device 的来源
不要在代码里到处手写 "cuda:0"、"cuda:1"、"cpu".
更稳一点的做法是统一从一个地方拿 device,比如:
device = args.device
或者直接从模型参数拿:
device = next(model.parameters()).device
这样更不容易出现“模型在一张卡上,数据却被送到另一张卡上”的问题.
- 在关键边界直接加 device 断言
调试阶段这其实非常有用. 比如:
assert X.device == next(model.parameters()).device
assert Y.device == X.device
assert loss_mask.device == X.device
这样你就不用等到后面某个矩阵乘法或者 loss 计算才看到一长串 device mismatch 报错.
如果把这些经验压缩成一句话,可以记成:
- 算的时候,尽量保证参与同一次计算的 tensor 都在同一个 device 上
- 记的时候,尽量尽早
.item()或.detach().cpu()
也就是说,训练代码里最好主动区分两条流:
- 训练计算流
model、input、label、mask、logits、loss 这些,应该尽量保持在同一个 device 上 - 日志 / 可视化流
print、wandb、numpy、matplotlib、保存展示结果这些,通常应该尽快转成 CPU 侧更安全的形式
很多 device 报错,本质上就是这两条流没有分开.
Pretrain 的 Eval 指标
这一章讨论的是 pretrain 阶段最核心的一类问题:我们到底该如何判断训练是不是在朝着正确的方向进行。
在前面的章节里,我们其实已经多次接触过一些和评估相关的现象。例如在第 2 节“优化器、学习率和数据设置”里,我们已经提到过 loss 曲线,以及不同的 batch size、learning rate 会怎样影响曲线形态。不过那一节的重点仍然是训练配置本身,还没有把“如何系统地观察和解释这些指标”单独展开。
但在实际实验中,评估并不是训练结束之后才考虑的附属环节,而是整个实验流程的一部分。一个训练实验如果没有合适的观测指标,就很难判断当前配置是否稳定,也很难验证自己的假设到底对不对。换句话说,如果不能有效评估,我们的实验就失去了意义。
因此,这一节会把 pretrain 中常见的评估指标单独整理出来。我们会先从最直接的训练 loss 和 loss 曲线开始,再进一步说明为什么仅看 training loss 还不够,以及为什么还需要 validation set、validation loss 乃至更完整的评估方式。
Q1: 训练时最直接的指标Loss怎么用?
Loss 本质上是有效 token 位置上的平均交叉熵:
其中,\(m_t\) 是 loss mask,表示第 \(t\) 个位置是否参与损失计算;\(y_t\) 是真实的下一个 token;\(q_\theta(y_t \mid x_{\le t})\) 是模型给真实 token 分配的概率。
loss 越低,说明模型平均来看给真实 token 分配了更高的概率。因此在 pretrain 中,loss 是最基础、最直接、也最容易持续监控的指标。
不过在实际训练里,我们通常并不是只盯着某一个孤立的 loss 数值,而是更关注 loss 曲线。因为真正有信息量的,往往不是“当前 step 的 loss 是多少”,而是“loss 随训练进展是如何变化的”。
Q1.1: 训练里常看的几种 loss 曲线分别是什么?
在实际实验里,常见的 loss 观察方式至少有下面几种:
- train step loss:每个 step 直接记录一次训练 loss。这是最原始的曲线,信息最丰富,但噪声也最大。
- smoothed train loss:对 step loss 做滑动平均或指数平滑,目的是更容易看出整体下降趋势。
- loss vs step:横轴是 optimizer step,纵轴是 loss。这是训练日志里最常见的一种画法。
- loss vs tokens seen:横轴换成训练过程中模型已经看过的 token 总数。这种画法在比较不同 batch size、不同梯度累积设置时更重要。
这里尤其要区分 loss vs step 和 loss vs tokens seen。
设:
- \(B_{\text{eff}}\) 表示 effective batch size;
- \(L\) 表示序列长度;
- \(T_{\text{update}}\) 表示每次参数更新对应的 token 数;
- \(S\) 表示已经执行的 optimizer step 数;
- \(D_{\text{seen}}\) 表示已经看过的 token 总数。
那么有:
\[ T_{\text{update}} = B_{\text{eff}} \cdot L \]
\[ D_{\text{seen}} \approx S \cdot T_{\text{update}} \]
这意味着:如果两个实验的 \(B_{\text{eff}}\) 不同,那么即使它们都训练了同样多的 step,它们实际看过的 token 数也可能完全不同。所以有时候 loss vs step 看起来某个实验更优,其实只是因为它每一步吃进了更多 token。
Q1.2: 不同 loss 曲线各自回答什么问题?
不同的 loss 曲线,回答的问题其实并不一样。
1. 看 train step loss:主要是在看局部稳定性。
这条曲线最容易暴露训练初期的不稳定现象,比如:
- loss 突然 spike;
- loss 长时间剧烈震荡;
- 出现
NaN或Inf; - warmup 结束附近突然不稳定。
这些现象往往提示 learning rate 过大、数值精度不稳定、梯度爆炸,或者 batch / warmup / optimizer 配置之间不匹配。
2. 看 smoothed train loss:主要是在看整体是否真的在下降。
单步 loss 抖动本身并不可怕。尤其在 batch 较小、梯度噪声较大时,step loss 很可能会明显上下波动。但如果平滑后的曲线仍然稳定向下,就说明模型整体还在学习。
所以很多时候我们会把两条曲线结合起来看:
- 原始 step loss 用来观察噪声和异常尖峰;
- smoothed loss 用来观察长期趋势。
3. 看 loss vs step:主要是在看“按更新次数计”的训练过程。
如果我们关心的是 warmup 有没有结束、learning rate schedule 在第几个 step 开始衰减、某个 checkpoint 前后训练是否稳定,那么 loss vs step 很直观。
但它有一个局限:当实验之间的 effective batch size 不同时,step 不再是公平的比较单位。
4. 看 loss vs tokens seen:主要是在看“按数据消耗计”的学习效率。
这一点和第 2 节最后讨论的 batch size 问题是连在一起的。effective batch size 变大之后,通常会看到两种现象:
- 曲线可能更平滑,因为每次更新用到了更多 token,梯度噪声更小;
- 但在固定
tokens seen下,模型未必学得更快,因为 batch 变大后参数更新次数会减少,而且 learning rate 也可能需要重新匹配。
所以如果我们只是看 loss vs step,很容易高估大 batch 实验;而如果改看 loss vs tokens seen,就更容易判断“模型在消耗同样多训练 token 的前提下,到底哪套配置学得更快”。
也正因为如此,在比较不同 effective batch size 的实验时,最好至少同时看两条曲线:
loss vs step:看训练过程是否稳定;loss vs tokens seen:看数据利用效率和收敛速度。
5. 不同曲线还可以帮助区分不同类型的问题。
例如:
- 如果 step loss 抖动很大,但 smoothed loss 仍然稳定下降,通常更像是 batch 偏小带来的噪声;
- 如果 loss 出现频繁尖峰、持续升高,甚至 NaN,通常更像是 learning rate 过大或训练失稳;
- 如果曲线非常平滑,但按
tokens seen看下降很慢,通常说明训练虽然稳定,但未必高效; - 如果某次改动后曲线整体形状明显变化,就说明这次改动很可能真的影响了训练动力学,而不只是让日志看起来更“好看”。
所以 loss 曲线最核心的作用,不只是告诉我们“当前 loss 是多少”,而是帮助我们回答下面这些更重要的问题:
- 当前训练是否稳定?
- 模型是否还在持续学习?
- 学习率是不是过大或过小?
- effective batch size 的设置是否合理?
- 不同实验之间的差异,究竟来自训练配置,还是只是比较方式不同?
Q2: loss 下降就代表训练收敛了吗?
loss 下降是好信号,但不能简单等同于训练已经收敛。
更准确地说,loss 下降说明模型正在更好地拟合训练数据中的 next token 分布。但它还不能回答这些问题:
- 模型是否过拟合了训练集?
- 模型在没见过的数据上表现如何?
- 模型是否真的具备可用的生成能力?
- 模型是否能遵循指令?
- 模型是否只是学会了某些高频模板?
所以训练 loss 更适合回答:“模型在当前训练数据上是否还在学习?”
它不能单独回答:“模型是否已经好用?”
换句话说,前面这些训练曲线更多是在回答 训练过程是否正常,而不是直接回答 模型能力是否足够好。这也是为什么我们接下来必须引入 validation set。
Q3: 为什么需要 validation loss?
如果只看 training loss,很难判断模型是不是过拟合。更理想的做法是准备一份验证集,训练过程中定期在验证集上计算 validation loss。
假设训练集 loss 持续下降,但 validation loss 开始上升,通常说明模型对训练数据拟合得越来越好,但泛化能力可能变差。
对于大模型 pretrain 来说,validation loss 很重要,因为它比人工看生成样例更稳定。生成样例会受到 prompt、采样参数、随机性影响,而 validation loss 是一个更可比较的数值指标。
更具体地说,training loss 和 validation loss 分工不同:
- training loss 更适合看训练是否稳定、是否还在继续学习;
- validation loss 更适合看模型在未参与训练的数据上表现如何;
- 如果两者一起看,还可以观察 train / val gap 是否在不断扩大,从而辅助判断过拟合风险。
Q3.1: validation set 需要多大?
validation set 不需要像训练集那样大,但也不能小到完全没有统计意义。它的核心目标不是“覆盖所有知识”,而是提供一份 固定、稳定、能够重复比较 的参考数据。
实践里更重要的往往不是绝对大小,而是下面几个原则:
- 和训练集分布尽量一致:如果验证集和训练数据分布差太远,那么 val loss 变化未必反映真实训练效果。
- 不参与训练:验证集必须和训练集严格隔离,不能一边训练一边混进去。
- 规模足够稳定:样本太少时,validation loss 会有较大随机波动,不利于比较实验。
- 固定不变:一旦开始做实验对比,最好始终使用同一份 validation set,否则不同实验之间就失去了可比性。
对于像 MiniMind 这样的学习项目,一个常见而实用的做法是:从原始语料里单独切出一小部分,规模不一定要很大,但最好保证包含足够多的 token,使得每次 eval 算出来的 loss 不会因为样本太少而大幅波动。
如果用符号表示,设:
- \(N_{\text{val}}\) 表示 validation set 的样本数;
- \(D_{\text{val}}\) 表示 validation set 的 token 总数;
- \(\hat{\mathcal{L}}_{\text{val}}\) 表示估计得到的 validation loss。
那么直觉上,\(D_{\text{val}}\) 越大,\(\hat{\mathcal{L}}_{\text{val}}\) 的统计波动通常越小;但代价是每次 eval 的计算开销也会更大。
所以 validation set 的大小本质上是在做一个平衡:
- 太小:波动大,不稳定;
- 太大:评估成本高,训练中频繁 eval 会拖慢整体吞吐;
- 适中:既能提供稳定趋势,又不会让 eval 成本过高。
Q3.2: 应该多久做一次 validation?
validation 也不是越频繁越好,因为每做一次 eval 都要消耗额外计算资源,还会打断训练节奏。
常见做法是每隔固定的若干个 step,或者每消耗固定数量的 tokens seen,就在同一份 validation set 上跑一次 eval。这样做的重点不是“评估得越勤越高级”,而是:
- 能及时发现训练已经失稳;
- 能观察 validation loss 是否仍在下降;
- 能在不同实验之间保留统一的评估节奏。
如果实验规模比较小、训练时间不长,可以把 eval 设得稍微频繁一点,方便观察曲线;如果训练规模较大,通常会把 eval 间隔拉长,避免评估开销过高。
MiniMind 当前这个学习项目里,训练脚本主要记录的是训练 loss。如果后续要继续完善实验记录,可以考虑加入一个固定的 validation set,并在每隔若干 step 后运行 eval。这样我们就不只是知道“训练 loss 在下降”,还能够进一步判断:“模型在没见过的数据上,是否也在同步变好。”
Q3.3: 如果 validation loss 和 training loss 都几乎不变,还有必要继续训练吗?
这个问题不能只凭一句“loss 不动了”就直接下结论,更准确的问法其实是:当前继续消耗更多训练 token,还能不能换来足够值得的收益?
如果在相当长的一段训练区间内,training loss 和 validation loss 都几乎没有继续下降,而且这种“几乎不变”已经明显超过了正常波动范围,那么通常说明这段训练的边际收益已经变小了。此时继续训练不一定完全没有收益,但性价比往往会越来越低。
更形式化一点地说,我们真正关心的其实是:每增加一部分训练 token,loss 还能下降多少。设:
- \(\mathcal{L}\) 表示 loss;
- \(D_{\text{seen}}\) 表示训练过程中已经看过的 token 总数。
那么可以关注这样一个量:
\[ \frac{\Delta \mathcal{L}}{\Delta D_{\text{seen}}} \]
如果 \(\Delta D_{\text{seen}}\) 已经很大,但 \(\Delta \mathcal{L}\) 仍然极小,那么就说明继续训练的边际收益在下降。
不过在实践里,是否停训通常还要结合下面几种情况一起判断:
- 如果 train loss 和 val loss 都进入平台期,而且按
tokens seen看也长期没有明显改善,通常说明继续训练的收益已经很有限。 - 如果 loss 变化很小,但下游能力还在提升,比如生成更稳定、某些 benchmark 还在缓慢上升,那么仍然可能值得继续训练。
- 如果当前正处在 learning rate schedule 的阶段切换附近,例如刚结束 warmup,或者刚进入更小 learning rate 的阶段,那么后面仍然可能出现一小段新的缓慢下降。
- 如果训练数据已经重复很多遍,而 validation loss 依然没有改善,那么继续训练更可能只是继续消耗 compute,而不一定能带来新的泛化收益。
所以更稳妥的说法不是“loss 不动了就一定该停”,而是:当 train loss、val loss 和下游能力都同时进入平台期时,停训才更有依据。
Q3.4: LLM 训练里会出现反直觉的 validation loss 曲线吗?
会,而且这恰恰是 LLM pretrain 和传统小数据监督学习很不一样的地方。
在很多经典深度学习任务里,我们常见的教科书式现象是:
- training loss 持续下降;
- validation loss 先下降,随后开始明显上升;
- 这个拐点通常被解释为比较明确的过拟合信号。
但在 LLM pretrain 里,这种曲线不一定总是出现。原因之一是:pretrain 往往面对的是更大的数据规模、更低的数据重复率,以及更长时间的 next-token 建模过程。很多时候,模型在很长一段训练里都还没有进入那种非常典型的“小数据过拟合”状态。
因此在 LLM 训练里,更常见的反而是下面几种情况:
- train loss 下降,validation loss 也继续下降,但下降得更慢。
- train loss 继续下降,但 validation loss 很早就进入平台期。
- validation loss 短期有波动,甚至偶尔反弹,但后面又继续下降。
- train loss 和 validation loss 几乎贴得很近,但模型实际生成能力仍然有限。
这些现象看起来有些“反直觉”,但并不奇怪。
第一种情况说明模型还在持续从大规模数据中学习,验证集也还没有明显表现出过拟合。
第二种情况说明模型虽然还在继续优化训练目标,但验证集上的平均 next-token 改善已经很有限。
第三种情况往往和 learning rate、评估噪声、eval 间隔、验证集规模有关,不一定意味着真正的过拟合开始。
第四种情况则说明:语言建模 loss 和“模型是否已经好用”并不是同一回事。
这也是为什么在 LLM 里,我们不能机械地套用传统监督学习里那种“只要 val loss 一上升,就说明该立刻停训”的经验。对于 pretrain,更常见的不是 validation loss 明显拐头向上,而是:
- 下降速度越来越慢;
- 长时间平台期;
- 和 training loss 一起缓慢下降,但幅度很小。
所以在 LLM pretrain 里,停训信号往往不是一个非常尖锐的拐点,而更像是一个综合判断:
- validation loss 是否还在明显改善;
- 在固定
tokens seen下,继续训练的收益是否已经非常边际; - 生成样例或下游评测是否还在变好;
- 当前 compute 是否值得继续投入在这次训练上。
Q4: Perplexity 是什么?
Perplexity 通常翻译成困惑度,可以理解成由语言模型的 cross entropy loss 派生出来的指标。
不过在正式定义 Perplexity 之前,最好先把这里的 loss 再统一一下。因为在前面的章节里,我们已经从不同角度写过语言模型的训练目标;如果这里不先把符号和视角对齐,后面直接写 PPL = exp(loss) 会显得有些跳。
更完整的推导可以参考 1.loss.md 中 Q4 的讨论。这里先把后面最需要用到的三种等价写法整理出来。
Q4.1: Loss的两种视角?
设:
- \(x_{1:T}\) 表示一段真实文本对应的 token 序列;
- \(x_{<t}\) 表示第 \(t\) 个位置之前的上下文;
- \(x_t\) 表示序列在第 \(t\) 个位置上的真实 token;
- \(y\) 表示“给定上下文后的真实 next token”这个随机变量;
- \(q_\theta(\cdot \mid x_{<t})\) 表示模型在上下文 \(x_{<t}\) 下预测的条件分布;
- \(p_{\text{data}}\) 表示真实数据分布。
从 最大似然 的角度看,自回归语言模型建模的是整条序列的联合概率:
于是训练目标可以写成最小化真实序列的负对数似然:
再利用 \(\log \prod = \sum \log\),就得到等价形式:
这表示:模型希望给真实序列中每一个位置上的真实 token 分配尽可能高的概率。
从 交叉熵 / 条件分布拟合 的角度看,同一个目标也可以写成:
这个式子的含义是:先从真实数据分布中采样上下文 \(x_{<t}\) 和对应的真实 next token \(y\),然后计算模型在这个位置上没有给真实 token 足够高概率时所付出的代价,也就是 \(-\log q_\theta(y \mid x_{<t})\)。
这三种写法本质上描述的是同一个训练目标,只是观察角度不同:
- 前两种更强调 最大化真实序列的联合概率;
- 第三种更强调 在每个条件分布上最小化交叉熵 / 负对数似然。
它们最终会落到同一种 token-level loss 上。所以在本章前面 Q1 里看到的:
其实就是上面这些理论目标在实际训练中的 batch 内、有效 token 上的平均形式。这里只是额外加入了 loss_mask,用来忽略 padding 等不参与训练的位置。
也可以这样理解符号:
- 在“整条序列”的视角里,通常写 \(x_t\);
- 在“当前位置标签”的视角里,通常写 \(y_t\) 或 \(y\);
- 对于自回归 next token prediction,这两者本质上指向的是同一个真实 token,只是书写视角不同。
Q4.2: Perplexity 是什么? 如何理解它?
在语言模型里,如果 loss 使用的是自然对数,那么 Perplexity 定义为:
\[ \text{PPL} = \exp(\mathcal{L}) \]
其中,\(\mathcal{L}\) 就是我们上文提到的平均 token-level cross entropy loss。
如果把平均 loss 写成:
\[ \mathcal{L} = - \frac{1}{N}\sum_{n=1}^{N}\log q_\theta(y^{(n)} \mid c^{(n)}) \]
其中:
- \(N\) 表示参与统计的有效 token 数;
- \(c^{(n)}\) 表示第 \(n\) 个位置对应的上下文;
- \(y^{(n)}\) 表示这个位置上的真实 next token;
那么:
1. Perplexity 的定义
Perplexity 本质上不是一个独立于 loss 的新目标,而是对平均负对数似然做了一次指数变换后的结果。
所以它和 loss 的关系非常直接:
- loss 在优化时更基础;
- Perplexity 更像是 loss 的另一种表达尺度。
2. Perplexity 隐含的含义是什么?
Perplexity 的关键在于:它不是先对概率做平均,而是先对 log 概率 做平均,再用 \(\exp\) 变换回来。
利用对数和指数的性质,可以把上面的式子改写成:
这说明 Perplexity 可以理解为:
真实 token 概率倒数的几何平均。
这句话很重要。它说明这里的“平均”不是算术平均,而是 几何平均。
之所以出现几何平均,本质上就是因为我们先在 log 空间求平均,再映射回普通概率空间。
因此,Perplexity 的直觉含义可以表述成:
- 它衡量的是模型平均需要在多大规模的不确定性中做选择;
- 或者说,它近似反映了模型对真实 token 平均还剩下多少“等效候选数”。
如果模型在每个位置都把真实 token 的概率大约压到 \(1/K\),那么:
\[ \text{PPL} \approx K \]
这也是为什么 Perplexity 常被直觉地解释成“模型平均困惑于多少个候选 token”。
3. Perplexity 的取值范围是什么?
Perplexity 的取值范围是:
\[ 1 \le \text{PPL} < \infty \]
原因是:
- 如果模型在每个位置都把真实 token 的概率预测为 1,那么
\[ \mathcal{L} = 0,\qquad \text{PPL} = \exp(0)=1 \]
- 如果模型给真实 token 的概率越来越小,那么 \(-\log q_\theta(y \mid x_{<t})\) 会越来越大,于是 loss 和 PPL 都会增大。
因此:
- PPL = 1 对应理论上的完美预测;
- PPL 越小越好;
- PPL 越大,说明模型平均给真实 token 分配的概率越低。
不过这里要注意,Perplexity 的绝对数值会受到 tokenizer、词表大小、数据分布和评估方式影响。因此它更适合同一套设置下做比较,而不适合跨任务、跨 tokenizer 直接横向比较。
4. Perplexity 更深层的数学含义是什么?
从信息论角度看,如果把平均 loss 记成交叉熵:
\[ \mathcal{L} = H(p_{\text{data}}, q_\theta) \]
那么:
\[ \text{PPL}=\exp\left(H(p_{\text{data}}, q_\theta)\right) \]
这说明 Perplexity 本质上是 交叉熵的指数形式。
如果一个离散分布在每次预测时都需要在 \(K\) 个等可能候选中做选择,那么它的不确定性大致满足:
\[ H \approx \log K \]
反过来就有:
\[ K \approx \exp(H) \]
这正是 Perplexity 的形式来源。
所以从更深一点的角度看:
- cross entropy / loss 衡量的是平均编码代价;
- Perplexity 衡量的是与这个编码代价等价的不确定性规模。
它把对数尺度下的平均误差,重新解释成了一个“等效分支数”或“等效选择空间”。
5. \(\text{PPL} = K\) 是否意味着模型什么都没学到?
不一定。这里最容易产生的误解是:一看到 \(\text{PPL} = K\),就把它理解成“模型只有 \(1/K\) 的概率猜对”,甚至进一步理解成“模型几乎什么都没学到”。这两个理解都过于粗糙。
更准确地说,\(\text{PPL} = K\) 表示的是:
\[ \left( \prod_{n=1}^{N} q_\theta(y^{(n)} \mid c^{(n)}) \right)^{1/N} \approx \frac{1}{K} \]
也就是说,模型给真实 token 的概率,其几何平均大约是 \(1/K\)。
因此,“\(K\) 个候选 token”只是一个等效解释。它的真正含义是:如果模型在每个位置都像是在 \(K\) 个等可能候选里做选择,那么它产生的平均不确定性,大致会和当前这个模型相当。
但这并不意味着:
- 每个位置都真的有
\(K\)个等可能候选; - 模型在每个位置都刚好给真实 token 分配
\(1/K\)的概率; - 模型的 top-1 准确率一定就是
\(1/K\)。
例如,模型可能在一些位置给真实 token \(0.8\) 的概率,在另一些位置只给 \(0.001\),最后综合起来,几何平均仍然可能对应某个固定的 Perplexity。
所以 \(\text{PPL} = 20\) 更准确的意思是:模型给真实 token 的几何平均概率大约是 \(0.05\),而不是它只有 \(5\%\) 的 top-1 正确率。
同样地,\(\text{PPL} = K\) 也不自动意味着“模型什么都没学到”。关键要看这个 \(K\) 相对于任务本身有多大:
- 如果词表大小是
\(V=50000\),而模型的 PPL 仍然接近\(50000\),那才比较接近“几乎和瞎猜差不多”; - 如果模型的 PPL 已经降到
\(20\)、\(10\)甚至更低,那通常说明它已经把原本巨大的不确定性压缩到了相对小得多的范围。
所以更合理的判断方式不是孤立地看 \(K\),而是看:
- 它相对于随机基线有多低;
- 它相对于之前的 checkpoint 有没有持续下降;
- 它相对于同设置下的其他模型有没有改善。
6. 为什么自然语言的 Perplexity 本来就不可能非常低?
这是理解 Perplexity 时非常关键的一点:自然语言本身就有不可消除的不确定性。
很多位置并不存在唯一必然的下一个 token。比如一句话:
“今天晚上我们去吃……”
后面可能接:
- 火锅
- 烧烤
- 日料
- 饭
- 什么
这些 continuation 都可能合理。也就是说,即使模型已经很好地理解了上下文,它也不可能总是把真实 token 的概率压到接近 1,因为真实文本本身就是在多个合理可能里选择了其中一个。
从信息论角度看,如果模型分布已经完全等于真实数据分布,那么此时的最优 loss 也不会一般性地等于 0,而是等于真实数据分布本身的熵。设:
- \(p_{\text{data}}\) 表示真实语言分布;
- \(H(p_{\text{data}})\) 表示这个分布本身的熵。
那么当模型已经达到最优时,有:
对应的理论下界则是:
因为真实语言分布的熵通常大于 0,所以:
这说明 \(\text{PPL} = 1\) 只会出现在一个极端理想化的情形里:每个位置都毫无不确定性,而且模型还始终预测完全正确。对于自然语言,这几乎是不可能的。
所以在实践中,Perplexity 包含了两部分来源:
- 语言本身的内在不确定性;
- 模型还没有学好的额外误差。
这也是为什么我们不应该把 “PPL 没有接近 1” 理解成模型很差。更合理的标准是:
- 在同样的 tokenizer、同样的数据分布、同样的评估方式下,PPL 是否持续下降;
- 相比基线模型或更小的 checkpoint,它是否显著更低。
7. 为什么模型“自信地犯错”会导致更高的 Perplexity?
这是 Perplexity 一个很值得强调的性质:它不只是惩罚“猜错”,还会更强烈地惩罚“高置信度地猜错”。
原因直接来自 token-level loss 的形式:
\[ \ell = -\log q_\theta(y \mid x_{<t}) \]
其中:
- \(y\) 是真实 next token;
- \(q_\theta(y \mid x_{<t})\) 是模型给真实 token 分配的概率。
如果模型给真实 token 的概率还不算太低,比如:
\[ q_\theta(y \mid x_{<t}) = 0.1 \]
那么:
\[ \ell = -\log 0.1 \approx 2.30 \]
但如果模型非常自信地把概率给错了,只给真实 token 极小的概率,比如:
\[ q_\theta(y \mid x_{<t}) = 10^{-4} \]
那么:
\[ \ell = -\log 10^{-4} \approx 9.21 \]
可以看到,后者的惩罚会大得多。
这说明 Perplexity 对模型的要求不只是“把正确答案排在前面”,而是还要求:不要对错误答案过度自信。
从 Perplexity 的定义看,这件事同样成立。因为:
如果某些位置上真实 token 的概率被压得特别低,那么这些位置对应的概率倒数就会特别大,从而显著拉高整体的几何平均。
所以在直觉上,可以把几种情况区分开:
- 不太确定,但分布还算温和:真实 token 的概率不高,但也没有低到离谱,PPL 会偏高,但不一定灾难性。
- 经常预测正确,而且概率分配合理:真实 token 的概率整体较高,PPL 会下降。
- 经常高置信度地预测错:真实 token 的概率被压得极低,loss 会非常大,PPL 也会明显恶化。
这也是为什么有时候两个模型的 top-1 行为看起来差不多,但 PPL 仍然可能差很多:
它们也许都“猜错了若干次”,但一个模型是谨慎地错,另一个模型是非常自信地错。对语言建模目标来说,后者会受到更重的惩罚。
Q4.3: 应该怎么看 Perplexity 曲线?
从定义上说,Perplexity 和 loss 是一一对应的:
\[ \text{PPL} = \exp(\mathcal{L}) \]
因此 PPL 曲线和 loss 曲线在趋势上是完全一致的:
- loss 下降,PPL 也下降;
- loss 进入平台期,PPL 也会进入平台期;
- loss spike,PPL 往往会出现更明显的 spike。
所以问题并不是“看 loss 更对,还是看 PPL 更对”,而是它们分别更适合什么用途。
1. 训练过程中,通常优先看 train loss。
因为 train loss 是优化器真正对应的目标,而且数值变化更线性,更方便观察训练稳定性、learning rate 是否过大、warmup 是否有问题。
train Perplexity 当然也可以画,但很多时候它只是 train loss 的指数变换,新增信息并不多。
2. 做模型评估时,更常看 validation Perplexity。
原因是 validation Perplexity 和 validation loss 一样,都是在固定验证集上统计出来的,更适合比较不同 checkpoint 或不同实验的泛化表现。
所以更常见的搭配往往是:
- 调训练时重点看
train loss; - 做评估或汇报时重点看
val loss或val perplexity。
3. 如果只想保留一条 PPL 曲线,通常优先保留 validation Perplexity 曲线。
因为 train PPL 更多反映模型对训练数据的拟合程度,而 val PPL 更接近我们真正关心的问题:模型在未参与训练的数据上平均还有多大的不确定性。
4. PPL 曲线更适合看整体趋势,不适合过度解读单点波动。
因为 PPL 是 loss 的指数变换,所以当 loss 在较高区间有小波动时,PPL 上的波动会被放大,看起来可能更夸张。
因此:
- 看短期训练稳定性时,loss 往往更稳妥;
- 看整体评估趋势和对外汇报时,PPL 往往更直观。
所以更实用的建议是:
- 调参时优先看 loss 曲线;
- 比较模型时重点看 validation loss / validation Perplexity;
- 如果是实验汇报或论文表达,Perplexity 往往比原始 loss 更容易让读者形成直觉。
Q5: 生成能力如何? 生成样例如何Eval?
前面几节讨论的 train loss、validation loss 和 Perplexity,本质上都是定量指标。它们非常重要,因为它们能帮助我们判断训练是否稳定、模型是否还在学习、不同实验之间谁更优。
但是这些指标也有边界:它们只能告诉我们模型在平均意义上是否更会预测下一个 token,却不能直接告诉我们“生成出来的文本读起来到底怎么样”。
因此在 pretrain 阶段,除了看 loss 和 PPL 这类数值指标,我们通常还会配合看一些生成样例。不过这里要先强调一点:生成样例更适合作为定性观察,而不是严格的、可重复的最终 eval 指标。
这是一个很大的问题。更系统的生成评测、指令跟随能力评测、偏好评测,我们会在后续的 SFT 章节里再展开。这里先讨论 pretrain 阶段最初步、最实用的几种观察方法。
Q5.1: 为什么还要看生成样例?
因为 loss 和 PPL 只能说明:模型平均来看是不是更擅长给真实 token 分配更高概率。
但它们不能直接回答下面这些更直观的问题:
- 生成出来的句子是否基本通顺?
- 会不会很快陷入重复?
- 会不会前面看起来正常,后面突然跑偏?
- 对常见格式,比如列表、问答、代码片段,是否已经有基本模式感?
这些现象很难只靠一个平均 loss 数字直接看出来,所以实践中常常会补几条固定 prompt 的生成样例,作为对训练状态的辅助观察。
Q5.2: 为什么生成样例不能单独当作严格 eval?
虽然生成样例很有价值,但它本身并不是特别稳定的指标。
原因是生成结果会受到很多因素影响,比如:
- prompt 的具体写法;
- temperature、top-k、top-p 等采样参数;
- 随机种子;
- 生成长度;
- 模型当时是否更擅长某一类局部模式。
这意味着:同一个 checkpoint,有时可以生成出一段看起来不错的文本;但换一个 prompt、换一个采样参数,结果可能就完全不同。
所以生成样例更适合用来回答下面这类问题:
- 模型大致学会了什么?
- 模型最明显的失败模式是什么?
- 和上一个 checkpoint 相比,它在局部连贯性、重复、格式感上有没有改善?
它不太适合单独回答:
- 模型是否已经“足够好”?
- 两个模型之间谁一定更强?
因此,更稳妥的做法通常是:
- 用
validation loss / validation PPL做主要的定量比较; - 用固定 prompt 的生成样例做辅助的定性分析。
Q5.3: Pretrain 阶段看生成样例时,主要看什么?
在 pretrain 之后,模型可能已经学到一些语言分布,比如能接上常见短语、能生成看似通顺的句子、能复述一些常见知识。但因为它还没有经过 SFT 和对齐训练,它不一定会稳定遵循聊天格式,也不一定真的理解用户指令。
所以 pretrain 阶段看样例时,重点通常不是“它能不能像聊天模型一样回答问题”,而是看它是否已经从接近随机输出,变成了一个初步可用的语言模型。
比较常见的观察点包括:
- 局部续写是否合理:能不能顺着 prompt 的局部语义往下接。
- 句法和语法是否基本通顺:有没有明显的乱码、词序崩坏、标点异常。
- 格式模式是否初步形成:比如列表、标题、缩进、问答格式能不能延续。
- 是否容易重复:会不会很快进入某个短语或句式的循环。
- 是否容易跑题:前两句还正常,后面突然和 prompt 毫无关系。
- 中长程连贯性是否开始出现:能不能在几句话范围内维持大致统一的主题。
Q5.4: 一些初步例子
下面给几个很初步的观察例子。
例 1:观察常见短语续写
如果 prompt 是:
今天晚上我们去吃
那么一个已经学到基本语言统计规律的 pretrain 模型,往往会续出:
火锅。
或者:
烧烤吧。
这说明它至少已经学会了一些高频 continuation。
但如果它续出完全无关的 token、乱码,或者很快陷入重复,那就说明基础语言建模还比较弱。
例 2:观察格式延续能力
如果 prompt 是:
1. 数据预处理
2. 模型训练
3.
那么如果模型倾向继续写出:
模型评估
或者:
结果分析
这通常说明它已经学到了一些局部格式模式,而不只是孤立地记住词和词之间的共现关系。
例 3:观察局部通顺但整体跑偏
有时 pretrain 模型会生成出这样的文本:
Transformer 是一种基于注意力机制的模型,它能够有效地建模上下文信息。
今天的天气很好,我们可以一起去公园散步。
前一句看起来很正常,但后一句突然跳到完全无关的话题。
这种现象说明模型已经学到了一部分局部流畅性,但中长程主题维持能力还比较弱。
例 4:观察重复和退化
还有一种常见失败模式是:
这个问题需要从多个方面进行分析,首先我们需要从多个方面进行分析,首先我们需要从多个方面进行分析……
这类重复退化通常说明模型虽然学到了一些局部高频结构,但生成时缺少更稳定的全局控制能力。
Q5.5: Pretrain 阶段该怎样看待这些样例?
这也是为什么实践中会看到一种很有意思的现象:只做 pretrain 的模型,有时已经能说出一些像样的话,但经常前言不搭后语。
这不是失败,而是 pretrain 的性质决定的。pretrain 教模型学习文本分布,SFT 才进一步教模型按照指令和对话格式输出。
所以在这一阶段,更合理的看法是:
- 不要因为模型偶尔说出几句通顺的话,就高估它的能力;
- 也不要因为它还不会稳定对话,就否定 pretrain 的价值。
Pretrain 阶段的生成样例,更像是在帮助我们回答:
- 模型是否已经摆脱了接近随机的输出?
- 模型是否开始具备局部语言流畅性?
- 模型的典型失败模式是什么?
- 不同 checkpoint 或不同训练配置之间,样例差异是否和 loss / PPL 的变化相互印证?
真正更系统的“生成能力评测”,尤其是指令跟随、问答质量、偏好对齐和人类主观体验评测,还需要放到后续的 SFT 和对齐章节里再展开。
Q5.6: 这些定性判断能不能做成自动化评测?
可以,但通常不能只靠单一指标完成。更实际的做法是:把原本比较主观的观察点,拆成若干可以重复执行的自动化检查项。
例如,前面提到的这些现象:
- 是否重复;
- 是否跑题;
- 是否能延续格式;
- 是否基本通顺;
- 是否已经摆脱接近随机的输出;
都可以部分转成自动化评测。
一种最直接的做法是:固定一组 prompt、固定采样参数、固定生成长度,然后在每个 checkpoint 上跑同一套生成脚本,再统计一些规则指标。
例如:
- 重复问题:可以统计
distinct-n、重复 n-gram 比例、最长重复子串长度; - 格式延续:可以写规则检查是否继续编号、是否保持 Markdown 列表、是否保持代码缩进;
- 乱码或退化:可以统计标点比例、中文字符比例、异常字符比例、句长分布;
- 主题偏移:可以用 prompt 和生成结果的 embedding 相似度,或者用更强模型判断主题是否一致;
- 局部通顺性:可以用更强语言模型或 judge model 做打分。
所以从方法上看,自动化通常可以分成三类:
1. 规则型指标
这类方法最便宜,也最容易复现。典型特点是:
- 不需要参考答案;
- 适合抓住明显退化现象;
- 但通常只能覆盖质量的一部分。
例如重复率、格式合法性、字符分布异常检测,都属于这一类。
2. 参考答案型指标
如果任务本身存在某种“标准输出”或至少有若干参考输出,就可以计算 BLEU、ROUGE、BERTScore、embedding 相似度之类的指标。
但在开放生成里,这类方法有明显局限:自然语言往往一题多解,所以“和参考答案像不像”不一定等于“生成质量高不高”。
3. Judge Model 评测
也就是让一个更强的模型按照固定 rubric 来打分,比如:
- 是否通顺;
- 是否重复;
- 是否跑题;
- 是否保持原格式;
- 是否存在明显事实或语法错误。
这类方法现在很常见,因为它比纯规则更灵活,比纯人工评测更便宜。但它本身也会带来评审模型偏差,所以更适合作为辅助指标,而不是唯一标准。
因此,更实用的经验通常是:
- 用规则指标做第一层自动筛查;
- 用 judge model 做第二层质量判断;
- 最后再做少量人工抽样复核。
Q5.7: 这些自动化方法也适合 SFT 或 function calling 的测评吗?
适合一部分,但不能直接把 pretrain 阶段的这些方法原封不动搬过去。更准确地说,这些方法更像是一套通用评测工具箱,而不同任务通常还需要自己的专门测试集和判分标准。
有一些评测方法是跨任务通用的,例如:
- 固定测试集;
- 固定推理参数;
- 自动脚本跑分;
- judge model 打分;
- 人工抽样复核;
- 成功率 / 失败率统计;
- 输出格式合法性检查。
这些方法不只 pretrain 可以用,SFT、function calling、RAG、agent 任务也都可以用。
但问题在于:不同任务的“正确”定义并不一样。
对于 pretrain,前面这些生成样例主要是在看:
- 是否重复;
- 是否通顺;
- 是否延续格式;
- 是否会突然跑题;
- 是否已经学到基本语言分布。
而到了 SFT,评测重点会变成:
- 是否遵循指令;
- 是否回答完整;
- 是否安全;
- 是否风格符合预期;
- 多轮对话是否一致。
到了 function calling,重点又会变成:
- 是否该调用工具;
- 是否调用了正确的工具;
- 参数是否齐全;
- 参数类型是否正确;
- 工具调用之后是否真正执行成功。
这时,单纯看“生成得通不通顺”已经远远不够了。很多时候,即使自然语言写得很好,只要工具名选错、参数传错、JSON 结构非法,这次 function calling 在任务上就是失败的。
所以更合理的理解是:
- 自动化评测的方法论有通用部分;
- 但每个任务的测试集合和专门指标通常需要单独设计。
可以把它概括成两层:
第一层:通用层
这部分几乎所有任务都能复用:
- 固定样本集;
- 自动跑分脚本;
- judge model;
- 人工 spot check;
- 稳定性、成本、延迟统计。
第二层:任务层
不同任务要补自己的核心指标:
- pretrain:loss、PPL、重复率、生成退化;
- SFT:指令跟随、帮助性、安全性、偏好胜率;
- function calling:tool selection accuracy、argument accuracy、execution success rate;
- RAG:retrieval recall、faithfulness、citation correctness;
- agent:task completion rate、步骤效率、工具使用正确性。
这里还有一个很重要的经验:
- 越开放的任务,越依赖 judge model 和人工评审;
- 越结构化的任务,越适合做精确自动评测。
例如:
- 开放式问答或自由写作,很难只靠一个规则精确判分;
- function calling 的 JSON 结构、参数字段、执行结果,则往往很适合自动精确比对。
所以如果放到后续章节里,更自然的衔接方式是:
- pretrain 阶段先学会如何结合
loss / PPL / 生成样例看一个基础语言模型; - 到 SFT 阶段,再引入更专门的 instruction-following 测试集和 judge 方式;
- 到 function calling 阶段,再引入结构正确性、工具调用正确率和执行成功率这类更任务化的指标。
Q6: 除了 loss / PPL,还有哪些训练中值得顺手盯着的曲线?
在实际训练里,loss 和 PPL 当然最核心,但它们不是唯一值得看的量。很多训练问题并不是先体现在最终指标上,而是先体现在优化过程、数值稳定性和吞吐监控上。
因此更完整一点的训练监控面板里,通常还会顺手看下面这些曲线或指标:
| 曲线 / 指标 | 主要看什么 | 常见异常含义 |
|---|---|---|
learning rate curve | warmup、decay 是否按预期执行 | schedule 配错,实际 LR 和预期不一致 |
gradient norm curve | 梯度是否整体稳定 | 梯度爆炸、LR 过大、训练失稳 |
parameter norm / update norm | 参数尺度和每次更新幅度是否异常 | 更新过猛、参数漂移异常、优化器状态异常 |
loss scale / NaN count | 混合精度训练是否数值稳定 | 溢出、下溢、AMP 配置问题 |
tokens/sec / step time | 吞吐和训练效率 | loss 虽然在降,但训练效率很差 |
train loss 和 eval loss 的 gap | 训练集和验证集是否开始分化 | 过拟合、数据污染、训练分布不匹配 |
GPU memory / utilization | 显存和算力利用率 | batch 太小、数据管道瓶颈、硬件没有吃满 |
这些指标不一定每次都要展开分析,但它们能帮助我们更早发现问题。很多时候,真正的异常并不是先出现在最终的 validation loss 上,而是先出现在:
- 学习率曲线没有按预期走;
- 梯度范数突然 spike;
- loss scale 频繁回退;
- 吞吐异常下降;
- train / eval gap 提前拉大。
所以如果把训练过程想成一个监控面板,那么:
loss / PPL更像是主指标;- 上面这些曲线更像是辅助诊断指标。
Q7: 更现实的测试和训练流程: 开放世界中的不确定性
到这里其实会自然出现一个更现实的问题:在真正的大模型系统里,训练和测试并不是一条简单的直线流程,而更像是一棵不断分叉、不断回环的能力树。
我们前面讨论了 pretrain 的 loss、validation loss、Perplexity,也讨论了生成样例、自动化评测和后续任务专用 benchmark。但当问题真的落到开放世界里的复杂任务上时,一个现象往往不再只有唯一原因。
例如,一个下游任务表现不好,表面上看只是“模型回答不行”,但真实原因可能完全不同:
- 基础模型的 pretrain 还不够强;
- post-training 没有把任务形式教出来;
- function calling 或 tool use 训练不够;
- system prompt、采样参数或工具 schema 设计得不好;
- 评测集本身没有测到真正的问题;
- 任务定义混合了多个目标,导致训练和评测都不清晰。
这也是为什么现实里的训练和测试流程,往往比教科书里更复杂。它不是单次训练、单次评测就能结束的,而是一个不断观察、定位、修正、再评估的循环。
Q7.1: 为什么现实里的模型训练更像一棵能力树?
如果把一个商业大模型系统粗略拆开,它通常至少包含下面几层能力:
1. 基础层:Pretrain Base Model
- 语言流畅性;
- 知识覆盖;
- 长上下文建模;
- 基础推理和模式归纳;
- 多语言、代码、数学等底座能力。
2. 对齐层:Post-training
- 指令跟随;
- 回复风格;
- 拒答策略;
- helpful / harmless / honest;
- 多轮对话稳定性。
3. 工具层:Task-Specific Training
- function calling;
- tool selection;
- 参数填写;
- RAG 引用;
- agent planning。
4. 产品层:Inference & System Design
- system prompt;
- routing;
- sampling;
- tool schema;
- memory;
- fallback 策略。
5. 评测层:Eval & Monitoring
- 离线 benchmark;
- judge model 和人工评测;
- 在线 A/B test;
- failure case 分类;
- 用户反馈闭环。
所以现实中的训练流程,很少是:
- 训完 pretrain。
- 再训一次 SFT。
- 结束。
更常见的实际流程反而是:
- 先得到一个 base model。
- 做通用 post-training。
- 再做任务专项训练。
- 用专项 eval 找失败模式。
- 再回到数据、训练策略、产品逻辑继续修正。
- 然后重新评测。
从这个角度看,训练流程更像是一棵树,甚至更像一张带回路的图:每做一次评测,都会把问题重新分流到不同层级。
Q7.2: 下游任务做不好时,怎么判断是 base model 不够强,还是后训练不够?
这是一个非常现实,也非常难的问题。因为很多下游问题并不是“base 不够强”和“后训练不够”二选一,而更像是两者共同作用的结果。
例如,function calling 做不好,可能有几种完全不同的原因:
- base model 根本没理解任务语义;
- base model 其实理解了,但没有被训练成稳定输出结构化 schema;
- 工具调用的数据不够;
- 工具 schema 设计得不清楚;
- 系统 prompt 没把调用规则写明白。
所以工业实践里通常不会直接问:“是不是基础模型太弱?”
而是先把问题拆成更细的定位问题。
一个常见的思路是:
先怀疑上层问题,再怀疑底层问题。
这是因为:
- 改 prompt、采样参数、tool schema、routing 策略最便宜;
- 改 SFT 数据或 task-specific post-training 次之;
- 继续大规模 pretrain 或重训 base model 最贵。
所以现实里更常见的排查顺序是:
- 先看评测定义是不是有问题;
- 再看推理配置和产品编排是否有问题;
- 再看 task-specific post-training 是否不够;
- 再看通用对齐是否损伤了能力;
- 最后才看是不是 base model 本身不够强。
Q7.3: 有什么更具体的判断思路?
如果一个任务失败了,常见的判断方法包括:
1. 看模型“会不会”,还是“会但不稳定”。
如果给一点更明确的示范,模型就明显能做出来,那么问题往往更像是:
- prompt 不够清楚;
- 输出格式没有教好;
- 后训练还不够稳定。
如果即使给了很强的引导,它仍然做不好,那么问题就更像底层能力不足。
2. 看把任务改成更结构化之后,模型会不会。
例如把自由生成问题改成:
- 选择题;
- 判断题;
- 填槽题;
- 固定 JSON 输出。
如果结构化之后模型明显变好,那么通常说明它并不完全是“不会”,而可能是:
- 自由生成阶段不稳定;
- 格式对齐不够;
- 输出空间太开放。
3. 看是不是某一类失败特别集中。
例如在 tool use 任务里,可以继续细分:
- 理解错任务;
- 选错工具;
- 参数填错;
- 应该调工具但没调;
- 工具调用成功了,但结果没整合进最终回答;
- 输出格式非法。
只有把失败继续切成这些更细的子类,才能知道下一步该补哪一层能力。
4. 看更便宜的修复能不能救回来。
如果换一个更清楚的 system prompt、改一下 schema、补一点更贴任务的 SFT 数据,性能就明显上升,那么通常没有必要立刻怀疑 pretrain 底座。
反过来,如果这些便宜修复几乎都无效,才更有理由怀疑 base model 的能力上限。
Q7.4: 这和我们现在做的小模型实验有什么关系?
MiniMind 这种规模的模型非常适合学习训练流程,但它的能力边界也很明显。
因此评估时要避免两个极端:
- 看到模型能说出几句通顺的话,就高估它的能力;
- 看到模型回答不稳定,就否定 pretrain 的意义。
更合理的看法是:小模型的 pretrain 结果主要用于观察训练机制,而不是追求最终可用的智能水平。
对于这一类实验,我会优先关注:
- loss 曲线是否正常下降。
- validation loss / validation PPL 是否和训练趋势基本一致。
- checkpoint 是否能稳定保存和恢复。
- 模型是否从完全随机输出变成能生成局部通顺文本。
- 相同设置下,不同实验之间的 loss 和样例是否有可解释差异。
这些指标不一定能证明模型“强”,但能证明训练流程在工作。
Q7.5: 一个更现实的总结
如果把这整章内容放在一起看,一个更现实的结论是:
- pretrain 阶段先用
loss / validation loss / PPL把训练过程看清楚; - 再用固定 prompt 的生成样例和一些自动化指标补充定性观察;
- 到 SFT、function calling、RAG、agent 等阶段,再分别引入更专门的测试集和任务指标;
- 当下游任务做不好时,不要急着把原因都归到“模型不够强”,而要先把问题拆到不同能力层级上去定位。
换句话说,真实世界里的大模型训练和测试,不是单条流水线,而是一个在开放世界不确定性中不断分叉、不断回收的闭环系统。
MiniMind Pretrain 实践入口
快速开始
在进入各种理论之前,最好先把原始项目跑起来,直接开始跑 Pretrain。原始项目介绍得很详细: 原项目参考文档。
下面内容是我实践时整理出来的版本。它不是完整复述原项目 README,而是把最容易混乱的几件事先梳理清楚:
- 不同 MiniMind 版本到底对应什么模型配置。
- 预训练和后续阶段分别应该下载哪些数据。
- 如果我现在想训练某一个版本,应该敲哪条命令。
MiniMind3 的模型结构和训练代码升级细节,可以参考另一篇笔记:MiniMind 3 升级内容。
1. 先梳理模型配置
MiniMind 项目历史版本比较多,而且有些名字描述的是“模型结构”,有些名字描述的是“训练流程产物”,所以第一次看 README 时很容易混在一起。
我目前建议这样理解:
MiniMind Zero:更像是一个训练目标或者实践路线,而不是一个独立的新架构。它通常指“用 mini 数据集,从 0 快速训练出一个能基本对话的小模型”。在 MiniMind3 语境下,最快复现 Zero 通常是pretrain_t2t_mini.jsonl + sft_t2t_mini.jsonl。minimind-3:当前主线 Dense 模型,默认hidden_size=768、num_hidden_layers=8,参数量约 64M。minimind-3-moe:当前主线 MoE 模型,主干配置和minimind-3基本一致,但 FFN 换成 MoE,参数量约 198M,总参数更多,但激活参数约 64M。minimind2-small/minimind2:历史版本配置。现在如果只是跟着最新代码实践,可以优先看minimind-3,历史版本主要作为对照。
1.1 常见模型版本表
| 版本 / 训练目标 | 参数量 | 关键结构参数 | 训练命令中的核心参数 | 适合场景 |
|---|---|---|---|---|
| MiniMind Zero | 取决于所选结构,MiniMind3 下通常约 64M | 通常使用 minimind-3 Dense 结构 | --hidden_size 768 --num_hidden_layers 8 --use_moe 0 | 最快从 0 跑通 pretrain + SFT,观察完整训练链路 |
| minimind-3 | 约 64M | d_model=768,n_layers=8,q_heads=8,kv_heads=4 | --hidden_size 768 --num_hidden_layers 8 --use_moe 0 | 当前主线 Dense 模型,优先推荐 |
| minimind-3-moe | 约 198M-A64M | d_model=768,n_layers=8,4 experts / top-1 routing | --hidden_size 768 --num_hidden_layers 8 --use_moe 1 | 想观察 MoE 训练和激活参数概念 |
| minimind2-small | 约 26M | d_model=512,n_layers=8,历史轻量配置 | --hidden_size 512 --num_hidden_layers 8 --use_moe 0 | 更低成本的历史小模型配置 |
| minimind2 | 约 104M | d_model=768,n_layers=16,历史主线配置 | 当前脚本需要额外指定 --hidden_size 768 --num_hidden_layers 16 --use_moe 0 | 作为历史主线对照 |
1.2 为什么 MiniMind3 默认选择 hidden_size=768
hidden_size 也就是 Transformer 里的 d_model。它决定了每个 token 在模型内部被表示成多宽的向量。
如果 hidden_size 太小,模型表达能力会明显受限。尤其是在 attention 中,每个 head 的维度通常是:
其中,\(d_\text{model}\) 表示隐藏层维度,\(n_\text{heads}\) 表示 query head 数量,\(d_\text{head}\) 表示每个 head 的维度:
\[ d_\text{head} = \frac{d_\text{model}}{n_\text{heads}} \]
比如 hidden_size=512、num_attention_heads=8 时,\(d_\text{head}=64\)。如果继续把 hidden_size 压得更小,head 内部可表达的信息也会变少。对于 MiniMind 这种小模型来说,embedding 层、attention head 维度、FFN 中间层都会一起受到影响。
但如果 hidden_size 太大,训练成本又会明显上升。MiniMind3 选择 hidden_size=768、num_hidden_layers=8,本质上是在几个目标之间做折中:
- 相比
512,768有更好的表示能力。 - 相比堆到更多层,
8 layers更容易在个人 GPU 上快速训练。 - 对于 64M 级别的小模型,它能在训练速度、稳定性和效果之间取得比较平衡的结果。
所以实践时可以先记住一个简单规则:
- 想快速复现,优先用
hidden_size=768, num_hidden_layers=8的 MiniMind3 Dense。 - 想更省资源,可以退回
hidden_size=512, num_hidden_layers=8的历史 small 配置。 - 想观察 MoE,就保持
768 x 8不变,只把--use_moe 1打开。
2. 再梳理数据配置
新版 MiniMind3 默认数据已经从早期的 pretrain_hq.jsonl 切换到 pretrain_t2t(_mini).jsonl 和 sft_t2t(_mini).jsonl。
数据集下载地址:
下载后统一放到 ../dataset 目录下。这里使用 ../dataset 是为了和训练脚本默认参数、上游项目习惯保持一致。实际运行前只要确认下面路径能被当前命令找到即可:
uv run python -m minimind_learning.trainer.train_pretrain --data_path ../dataset/pretrain_t2t_mini.jsonl
如果你把数据放在别的位置,只需要同步修改 --data_path,模型和训练逻辑本身不受影响。
2.1 数据集用途表
| 数据集 | 大致用途 | 推荐场景 |
|---|---|---|
../dataset/pretrain_t2t_mini.jsonl | 轻量预训练数据 | 快速复现 MiniMind Zero / 快速验证训练流程 |
../dataset/pretrain_t2t.jsonl | MiniMind3 主线预训练数据 | 完整训练 minimind-3 |
../dataset/sft_t2t_mini.jsonl | 轻量 SFT 数据,已混入部分 Tool Call 样本 | 快速把 pretrain 模型训练成基础对话模型 |
../dataset/sft_t2t.jsonl | MiniMind3 主线 SFT 数据,含 Tool Call 样本 | 完整 SFT,追求更好效果 |
../dataset/dpo.jsonl | 偏好对齐数据 | DPO 阶段使用,不属于 pretrain |
../dataset/rlaif.jsonl | RLAIF 数据 | PPO / GRPO / CISPO 等后续 RL 阶段 |
../dataset/agent_rl.jsonl / ../dataset/agent_rl_math.jsonl | Agentic RL 数据 | 多轮 Tool-Use / 数学工具场景 |
如果只是想回家先把 pretrain 跑起来,最小需要:
../dataset/pretrain_t2t_mini.jsonl
如果想继续完成 Zero 风格对话模型,还需要:
../dataset/sft_t2t_mini.jsonl
2.2 原项目推荐的数据组合和训练参数
下面这张表把原项目 README 和训练脚本中的默认配置合在一起看。这样后面真正训练时,就不只是知道“下载哪个数据集”,也知道每个阶段大概应该用什么 epoch 和关键参数。
| 目标 | 数据组合 | 阶段 | epoch | 关键训练参数 | 说明 |
|---|---|---|---|---|---|
| MiniMind Zero / 快速复现 | ../dataset/pretrain_t2t_mini.jsonl + ../dataset/sft_t2t_mini.jsonl | Pretrain | 1 | batch_size=32,learning_rate=5e-4,accumulation_steps=8,max_seq_len≈768 | 先用 mini 预训练数据快速得到 base 权重 |
| MiniMind Zero / 快速复现 | ../dataset/pretrain_t2t_mini.jsonl + ../dataset/sft_t2t_mini.jsonl | Full SFT | 1 | batch_size=16,learning_rate=1e-5,accumulation_steps=1,max_seq_len≈768 | 在 pretrain 权重上继续训练,得到基础对话能力 |
| MiniMind3 Dense 主线 | ../dataset/pretrain_t2t.jsonl + ../dataset/sft_t2t.jsonl | Pretrain | 2 | batch_size=32,learning_rate=5e-4,accumulation_steps=8,max_seq_len≈380 | 更接近完整 minimind-3 主线训练 |
| MiniMind3 Dense 主线 | ../dataset/pretrain_t2t.jsonl + ../dataset/sft_t2t.jsonl | Full SFT | 2 | batch_size=16,learning_rate=1e-5,accumulation_steps=1,max_seq_len=768 | 主线 SFT,数据中已混入 Tool Call 样本 |
| MiniMind3 MoE | 可沿用 mini 或主线数据组合 | Pretrain / Full SFT | 同 Dense | 在对应 Dense 命令基础上加 --use_moe 1 | 总参数更大,激活参数约等于 Dense,训练会更慢 |
| DPO 后续对齐 | ../dataset/dpo.jsonl | DPO | 1 | batch_size=4,learning_rate=4e-8,beta=0.15,max_seq_len=1024 | 属于 SFT 之后的偏好对齐阶段,不是 pretrain 必需步骤 |
需要注意,原项目里说 minimind-3 在单卡 3090 上 1 epoch 约 2.31h,指的是 pretrain_t2t_mini + sft_t2t_mini 两阶段合计的快速 Zero 路线;minimind-3-moe 同样数据组合下约 3.23h。这些数字主要用于估算门槛,不应该理解成固定训练时间,因为不同 GPU、数据加载速度、max_seq_len、batch size 都会影响耗时。
从脚本默认参数看,三个主要阶段的默认值大致是:
Pretrain:
epochs=2
batch_size=32
learning_rate=5e-4
accumulation_steps=8
max_seq_len=340
data_path=../dataset/pretrain_t2t_mini.jsonl
Full SFT:
epochs=2
batch_size=16
learning_rate=1e-5
accumulation_steps=1
max_seq_len=768
data_path=../dataset/sft_t2t_mini.jsonl
DPO:
epochs=1
batch_size=4
learning_rate=4e-8
beta=0.15
max_seq_len=1024
data_path=../dataset/dpo.jsonl
所以如果只是第一次实践,我会优先采用:
Pretrain: pretrain_t2t_mini, epochs=1, max_seq_len=768
SFT: sft_t2t_mini, epochs=1, max_seq_len=768
先把完整链路跑通,再考虑把数据切到 pretrain_t2t / sft_t2t,或者打开 --use_moe 1。
2.3 pretrain_t2t_mini 和 pretrain_t2t 怎么选
pretrain_t2t_mini.jsonl 更适合快速实践。它的目标不是把模型训练到最强,而是让我们在较短时间内完整跑通:
数据读取 -> tokenizer -> 模型 forward -> loss -> backward -> checkpoint -> 评估
pretrain_t2t.jsonl 更适合完整复现 MiniMind3 主线模型。它数据量更大,训练时间更长,也更适合和上游 README 中的主线结果对齐。
这里的选择可以简单理解为:
- 先学习代码、验证环境:选
pretrain_t2t_mini.jsonl。 - 想认真训练一个主线模型:选
pretrain_t2t.jsonl。 - 显存/时间有限:先不要急着上主线完整数据。
2.4 max_seq_len 是 token 长度,不是字符长度
训练参数里的 max_seq_len 指的是 token 数,不是字符数。MiniMind tokenizer 在中文上大致可以粗略理解为 1 token ≈ 1.5~1.7 个中文字符,英文压缩比会更高一些。
所以 max_seq_len 的选择其实是在两个问题之间做平衡:
- 太短:长样本会被截断,语义不完整。
- 太长:短样本会 padding 到很长,浪费算力。
上游 README 中给出的经验是:
pretrain_t2t_mini.jsonl:可以设置相对长一些,比如max_seq_len≈768。pretrain_t2t.jsonl:主线训练中可以设置更均衡一些,比如max_seq_len≈380。
在我们当前的训练脚本里,默认值是:
--max_seq_len 340
如果只是快速跑通,可以先用默认值;如果你明确使用 pretrain_t2t_mini.jsonl 并希望减少截断,可以手动改成:
--max_seq_len 768
3. 最后给出运行命令和参数
下面命令默认从项目根目录执行。为了和本文统一,数据路径都写成 ../dataset/...。
3.1 快速训练 MiniMind Zero 的 pretrain 阶段
这条命令对应的是:使用 MiniMind3 Dense 结构,用 mini 预训练数据快速跑通第一阶段。
uv run python -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t_mini.jsonl \
--save_dir ../out \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 768 \
--use_moe 0 \
--epochs 1 \
--batch_size 32 \
--accumulation_steps 8 \
--learning_rate 5e-4 \
--save_weight pretrain \
--from_weight none
训练后主要得到:
../out/pretrain_768.pth
../checkpoints/pretrain_768_resume.pth
如果中断后继续训练,追加:
--from_resume 1
3.2 训练 MiniMind3 Dense 主线 pretrain
这条命令对应的是当前主线 minimind-3 Dense 结构。和上面 Zero 快速路线的主要区别是:数据集换成完整的 pretrain_t2t.jsonl。
uv run python -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t.jsonl \
--save_dir ../out \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 380 \
--use_moe 0 \
--epochs 2 \
--batch_size 32 \
--accumulation_steps 8 \
--learning_rate 5e-4 \
--save_weight pretrain \
--from_weight none
训练后主要得到:
../out/pretrain_768.pth
../checkpoints/pretrain_768_resume.pth
3.3 训练 MiniMind3 MoE pretrain
这条命令对应 minimind-3-moe。模型主干仍然是 hidden_size=768, num_hidden_layers=8,区别是打开 MoE:
uv run python -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t_mini.jsonl \
--save_dir ../out \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 768 \
--use_moe 1 \
--epochs 1 \
--batch_size 32 \
--accumulation_steps 8 \
--learning_rate 5e-4 \
--save_weight pretrain \
--from_weight none
训练后主要得到:
../out/pretrain_768_moe.pth
../checkpoints/pretrain_768_moe_resume.pth
MoE 总参数更多,训练也会更慢。它适合用来观察“总参数量”和“激活参数量”的区别,而不是最快速地跑通流程。
3.4 训练历史 minimind2-small 风格配置
如果只是想用更小配置快速实验,可以使用历史 minimind2-small 风格:
uv run python -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t_mini.jsonl \
--save_dir ../out \
--hidden_size 512 \
--num_hidden_layers 8 \
--max_seq_len 512 \
--use_moe 0 \
--epochs 1 \
--batch_size 32 \
--accumulation_steps 8 \
--learning_rate 5e-4 \
--save_weight pretrain \
--from_weight none
训练后主要得到:
../out/pretrain_512.pth
../checkpoints/pretrain_512_resume.pth
3.5 多卡训练命令
如果有多张 GPU,可以用 torchrun 启动。比如单机 2 卡:
uv run torchrun --nproc_per_node 2 -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t_mini.jsonl \
--save_dir ../out \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 768 \
--use_moe 0 \
--epochs 1 \
--batch_size 32 \
--accumulation_steps 8 \
--learning_rate 5e-4 \
--save_weight pretrain \
--from_weight none
其中 --nproc_per_node 2 表示启动 2 个进程,一般对应 2 张 GPU。实际训练时,batch_size 是每个进程上的 batch size,总 batch size 会随 GPU 数增加而变大。为了保持训练动态接近单卡,有时需要同步调整 batch_size 或 accumulation_steps。
3.6 可选参数说明
几个常用参数可以先记住:
| 参数 | 含义 |
|---|---|
--use_wandb | 开启 SwanLab / wandb 风格训练可视化 |
--from_resume 1 | 从 ../checkpoints 中自动恢复训练 |
--use_compile 1 | 开启 torch.compile,可能提升吞吐,但会增加首次编译开销 |
--save_interval | 每隔多少 step 保存一次权重 |
--log_interval | 每隔多少 step 打印一次训练日志 |
4. 训练输入输出
训练需要设置的几个目录:
--save_dir:保存模型权重的目录,本文统一使用../out。--data_path:预训练数据路径,例如../dataset/pretrain_t2t_mini.jsonl。- checkpoint 默认保存到
../checkpoints。 - tokenizer 默认从
../model加载,也就是上游仓库中model/目录下的 tokenizer 文件。
训练后常见输出文件:
../out/pretrain_768.pth:MiniMind3 Dense 预训练权重。../out/pretrain_768_moe.pth:MiniMind3 MoE 预训练权重。../out/pretrain_512.pth:历史 small 配置的预训练权重。../checkpoints/<weight>_<hidden_dim>_resume.pth:续训检查点,包含模型、优化器、训练进度等信息。
5. 实验结果
在实际训练中,我们又遇到了一些很工程化的问题。这里我使用的是一块 RTX 3070 Laptop GPU,显存只有 8GB。经过几轮测试之后,我发现除了模型结构本身,下面两个训练参数也非常关键。
第一个是混合精度的数据类型。对这块消费级显卡来说,float16 比默认的 bfloat16 更合适。bfloat16 在一些新卡或者数据中心卡上很好用,但在 30 系消费级显卡上并不一定是最优选择。实际测试时,float16 的训练路径更顺,也更符合这块显卡的硬件特性。
第二个是 DataLoader 的 num_workers。一开始很容易以为 worker 越多,数据加载就越快。但在我的机器上,显存和内存都比较紧张,batch size 也不会设得特别大,CPU 到 GPU 的数据拷贝并不是主要瓶颈。反而是 worker 数太大以后,每个 worker 都要启动自己的进程,并持有一部分 Dataset / tokenizer 相关状态,尤其在 Windows 上进程启动开销更明显。实际测试下来,num_workers=0 反而更稳定,启动也更快。
所以在这台机器上,pretrain 阶段我会优先加上:
--dtype float16
--num_workers 0
训练代码细节
相比上游的原始训练代码,我在这里额外补充了几个更偏工程诊断的指标。训练不只是看 loss 是否下降,尤其是在小显存 GPU 上跑预训练时,还需要观察吞吐、梯度和真实处理过的 token 数。
首先是 tokens_seen 和 tokens/s。tokens_seen 统计训练过程中实际参与 loss 计算的 token 数,也就是排除了 label 中 -100 的 padding 或忽略位置之后的有效 token。这个指标比单纯的 step 更稳定,因为不同 batch 里的有效长度可能不同。tokens/s 则用来观察当前配置的吞吐,如果 batch size、sequence length、num_workers 或 dtype 改动之后,tokens/s 明显下降,就说明这组参数可能不是最优的。
第二个是 grad_norm。训练代码在 optimizer.step() 之前会先执行梯度裁剪:
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
last_grad_norm = float(grad_norm.item() if hasattr(grad_norm, "item") else grad_norm)
这里返回的 grad_norm 是裁剪前的全局梯度范数。它可以帮助我们观察训练稳定性:如果 grad_norm 长时间非常大,或者突然出现尖峰,通常说明学习率、batch size、数据分布或者混合精度状态可能存在问题;如果它异常接近 0,也可能说明梯度传播不充分。把它和 loss、learning rate、tokens/s 一起记录到 wandb 里,可以更容易判断训练到底是在正常收敛,还是只是表面上还能继续跑。
因此现在 wandb log 中除了 loss 之外,还会记录:
{
"loss": current_loss,
"logits_loss": current_logits_loss,
"aux_loss": current_aux_loss,
"learning_rate": current_lr,
"tokens_seen": tokens_seen,
"tokens_per_second": current_tokens_per_second,
"grad_norm": last_grad_norm,
"optimizer_step": did_optimizer_step,
}
这些指标不会改变训练行为,只是让训练过程更透明。尤其在正式长跑之前,它们可以帮助我们快速判断当前参数是否值得继续跑下去。
测试的重要性
这次实践里一个很深的感受是:不要等完整训练跑起来之后才发现参数不合适。训练代码一旦开始跑,可能几分钟之后才因为显存不够、数据加载过慢、checkpoint 太大或者 CUDA 状态异常而失败。这样每次都从头试,会非常浪费时间。
更好的方式是,在正式实验之前,先做一个很小的诊断轮。这个诊断轮不追求模型效果,只回答几个工程问题:
- CUDA 环境是否正常。
- 这个模型配置能不能放进显存。
- 某个
batch_size和max_seq_len组合下,峰值显存是多少。 - 每个 micro-step 大概需要多长时间。
- 第一次 optimizer step 之后,AdamW 状态会不会显著增加显存。
- 当前配置是否还留有足够显存余量。
理论上我们可以估算 batch size 和 sequence length 对显存的影响,但实际训练中还有 CUDA cache、optimizer state、临时张量、DataLoader、后台进程占用等因素。最后还是要在自己的机器上实际跑一下,才能确定真正可用的参数,而且最好留出余量。
为此,我在项目里加入了两个层次的测试。
第一个是 tests/test_gpu_diagnostics.py。它更像一个训练前分析器,而不是普通单元测试。它默认跳过,只有显式设置 RUN_GPU_DIAGNOSTICS=1 才会运行。这个测试会构造一个小的预训练 jsonl,初始化真实的 MiniMind 模型,跑若干个 micro-step,并输出每一步的耗时、显存和 tokens/s。
关键逻辑如下,代码来自 tests/test_gpu_diagnostics.py:
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
scaler = torch.amp.GradScaler("cuda", enabled=(dtype == torch.float16))
optimizer.zero_grad(set_to_none=True)
for micro_step in range(1, micro_steps + 1):
input_ids, labels = next(data_iter)
input_ids = input_ids.to("cuda:0", non_blocking=True)
labels = labels.to("cuda:0", non_blocking=True)
batch_tokens = int((labels != -100).sum().item())
lr = get_lr(micro_step, micro_steps, learning_rate)
for param_group in optimizer.param_groups:
param_group["lr"] = lr
with torch.amp.autocast("cuda", dtype=dtype):
result = model(input_ids, labels=labels)
loss = (result.loss + result.aux_loss) / accumulation_steps
scaler.scale(loss).backward()
if micro_step % accumulation_steps == 0:
scaler.unscale_(optimizer)
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
运行方式如下:
$env:RUN_GPU_DIAGNOSTICS='1'
$env:GPU_DIAG_HIDDEN_SIZE='768'
$env:GPU_DIAG_NUM_LAYERS='8'
$env:GPU_DIAG_SEQ_LEN='768'
$env:GPU_DIAG_BATCH_SIZE='16'
$env:GPU_DIAG_ACCUMULATION_STEPS='8'
$env:GPU_DIAG_STEPS='8'
$env:GPU_DIAG_DTYPE='float16'
$env:GPU_DIAG_NUM_WORKERS='0'
uv run python -m pytest tests/test_gpu_diagnostics.py -s
输出中最需要关注的是 summary 部分。例如一次 hidden_size=768, num_hidden_layers=8, seq_len=768, batch_size=16 的测试结果大致是:
{
"avg_step_s": 0.611,
"median_step_s": 0.563,
"avg_forward_s": 0.202,
"avg_backward_s": 0.380,
"tokens_per_second": 20095,
"peak_allocated_mb": 5951.78,
"peak_reserved_mb": 6494.0,
"estimated_reserved_headroom_ratio": 0.207,
"recommendation": "usable_but_tight"
}
这里的结论很直观:这个配置能跑,但不是特别宽裕。如果后台还有其他程序占用 GPU,或者训练过程中显存有波动,就有可能接近边界。
第二个是实际的 pretrain 诊断轮。为了让真实训练入口也能短跑验证,我给 train_pretrain.py 加了几个只用于诊断的参数:
--max_train_steps
--profile_train
--profile_interval
它们不会把诊断结果保存进 checkpoint,只是在训练时打印每个 step 的耗时和显存。核心代码来自 src/minimind_learning/trainer/train_pretrain.py:
if args.profile_train and ((step - start_step) % args.profile_interval == 0 or step == iters):
if torch.cuda.is_available():
torch.cuda.synchronize()
allocated_mb = torch.cuda.memory_allocated() / 1024**2
reserved_mb = torch.cuda.memory_reserved() / 1024**2
peak_mb = torch.cuda.max_memory_allocated() / 1024**2
else:
allocated_mb = reserved_mb = peak_mb = 0.0
step_time = time.time() - step_start_time
avg_step_time = (time.time() - profile_start_time) / max(step - start_step, 1)
tokens_per_second = int(batch_tokens.item()) / max(step_time, 1e-9)
Logger(
f"Profile step {step}: step_time={step_time:.3f}s, "
f"avg_step_time={avg_step_time:.3f}s, "
f"tokens/s={tokens_per_second:.1f}, "
f"optimizer_step={did_optimizer_step}, "
f"cuda_alloc={allocated_mb:.1f}MB, "
f"cuda_reserved={reserved_mb:.1f}MB, "
f"cuda_peak={peak_mb:.1f}MB"
)
实际短跑命令如下。这里 --max_train_steps 32 表示只跑 32 个 micro-step;当 accumulation_steps=16 时,也就是只做 2 次 optimizer step。
uv run python -u -m minimind_learning.trainer.train_pretrain \
--data_path ../dataset/pretrain_t2t_mini.jsonl \
--save_dir ../out \
--hidden_size 768 \
--num_hidden_layers 8 \
--max_seq_len 768 \
--use_moe 0 \
--epochs 1 \
--batch_size 16 \
--accumulation_steps 16 \
--learning_rate 5e-4 \
--save_weight pretrain_dense_probe \
--from_weight none \
--dtype float16 \
--num_workers 0 \
--log_interval 16 \
--save_interval 100000000 \
--max_train_steps 32 \
--profile_train \
--profile_interval 1
这次真实 pretrain 短跑的结果和 test_gpu_diagnostics 很接近:
Profile step 16: step_time=0.792s, avg_step_time=0.594s,
tokens/s=3998.5, optimizer_step=True,
cuda_alloc=952.6MB, cuda_reserved=6194.0MB, cuda_peak=5932.5MB
Epoch:[1/1](16/79390), loss: 8.9127, tokens_seen: 65613
Profile step 32: step_time=0.554s, avg_step_time=0.575s,
tokens/s=5477.6, optimizer_step=True,
cuda_alloc=952.6MB, cuda_reserved=6794.0MB, cuda_peak=6431.1MB
Epoch:[1/1](32/79390), loss: 8.4330, tokens_seen: 127676
这说明诊断测试确实能较好地预测真实训练的显存和耗时。seq_len=768, batch_size=16 能跑,但峰值 reserved 显存已经到 6.8GB 左右。对 8GB 显卡来说,这属于“可以跑,但需要留意后台占用”的配置。
显存占用理论值
MiniMind3 Dense 的参数量大约是 64M。如果只看模型权重,并且使用 float16,每个参数占 2 字节,那么权重本身大约是:
\[ 64 \times 10^6 \times 2 \text{ bytes} \approx 128 \text{ MB} \]
看起来这离 8GB 显存还很远。但训练时显存不只存模型权重,还要存梯度、优化器状态、激活值和各种临时张量。
以 AdamW 为例,假设参数量为 \(N\),每个参数用 FP16 存权重。训练时至少还会有:
- 权重:约 \(2N\) bytes。
- 梯度:通常也是约 \(2N\) bytes。
- AdamW 一阶动量
exp_avg:通常是 FP32,约 \(4N\) bytes。 - AdamW 二阶动量
exp_avg_sq:通常是 FP32,约 \(4N\) bytes。
也就是说,只看参数相关部分,粗略就可能达到:
\[ 2N + 2N + 4N + 4N = 12N \text{ bytes} \]
相对于 FP16 权重本身的 \(2N\) bytes,这大约是 6 倍。当然实际 PyTorch、AMP、optimizer 实现会有细节差异,但这个估算能说明一个关键点:不能只拿模型权重大小去判断训练显存。
不过,在我们这次实际测试里,参数相关的常驻显存并不是最大头。更明显的增长来自激活值。对于 Transformer 来说,激活值会随 batch size 和 sequence length 增长。一个隐藏状态张量的形状大致是:
[B, L, D]
其中:
- \(B\):batch size。
- \(L\):sequence length。
- \(D\):hidden size。
如果使用 float16,只看一个隐藏状态张量,它大约占:
\[ B \times L \times D \times 2 \text{ bytes} \]
例如 B=16, L=768, D=768 时:
\[ 16 \times 768 \times 768 \times 2 \approx 18 \text{ MB} \]
单个隐藏状态并不夸张,但训练时每一层都要为反向传播保留中间激活,attention、MLP、loss 计算也会产生额外临时张量,所以最终显存会比这个单项估算大得多。
尤其要注意,batch size 通常是最直接的放大器。batch_size=8 到 batch_size=16,显存压力几乎会明显上一个台阶;batch_size=16 到 batch_size=32,在 8GB 显卡上就很容易接近边界。
下面是这次在 RTX 3070 Laptop GPU 8GB 上的实测结果。模型都是 MiniMind3 Dense,即 hidden_size=768, num_hidden_layers=8, dtype=float16。
max_seq_len | batch_size | 诊断峰值显存 | 结论 |
|---|---|---|---|
| 512 | 1 | 约 0.62GB | 很轻 |
| 512 | 4 | 约 1.30GB | 很稳 |
| 512 | 8 | 约 2.19GB | 很稳 |
| 512 | 16 | 约 3.90GB | 稳 |
| 512 | 32 | 接近 7.96GB | 不推荐,已经接近显存上限 |
| 768 | 8 | 约 3.03GB | 推荐,比较稳 |
| 768 | 16 | 约 5.67GB 到 6.43GB | 可用,但需要留余量 |
其中 seq_len=768, batch_size=16 在 test_gpu_diagnostics 中测到的峰值 allocated 大约是 5.95GB;在真实 pretrain 短跑中,峰值 reserved 大约到 6.79GB。这两个数不完全一样,是因为 CUDA 的 allocated 和 reserved 含义不同:
allocated:当前真正被 tensor 使用的显存。reserved:PyTorch CUDA allocator 向显卡申请并缓存起来的显存。
训练时更应该关注 reserved 和系统总显存之间的余量。因为一旦 reserved 已经很接近总显存,后面即使 allocated 看起来还没满,也可能因为临时张量或后台进程导致 OOM。
实际执行的代码
综合上面的测试结果,在 8GB RTX 3070 Laptop GPU 上,如果训练 MiniMind3 Dense,我更推荐下面两个配置。
更稳的版本是:
uv run python -m minimind_learning.trainer.train_pretrain ^
--data_path ../dataset/pretrain_t2t_mini.jsonl ^
--save_dir ../out ^
--hidden_size 768 ^
--num_hidden_layers 8 ^
--max_seq_len 768 ^
--use_moe 0 ^
--epochs 1 ^
--batch_size 8 ^
--accumulation_steps 32 ^
--learning_rate 5e-4 ^
--save_weight pretrain ^
--from_weight none ^
--dtype float16 ^
--num_workers 0 ^
--log_interval 16 ^
--use_wandb
稍微激进一些、但实测可以跑的版本是:(实际测试是跑不了的,因为我还开浏览器刷b站,第一个batch还能跑,第二个batch到了7.9GB,开始来回swap,直接卡死了.)
uv run python -m minimind_learning.trainer.train_pretrain ^
--data_path ../dataset/pretrain_t2t_mini.jsonl ^
--save_dir ../out ^
--hidden_size 768 ^
--num_hidden_layers 8 ^
--max_seq_len 768 ^
--use_moe 0 ^
--epochs 1 ^
--batch_size 16 ^
--accumulation_steps 16 ^
--learning_rate 5e-4 ^
--save_weight pretrain ^
--from_weight none ^
--dtype float16 ^
--num_workers 0 ^
--log_interval 2 ^
--use_wandb
这两个配置的effective batch size 都尽可能和原文中的推荐做到一样 (effective batch size = 32*8, seq_len=768确保effective token接近):
\[ 8 \times 768 \times 32 = 196608 \]
\[ 16 \times 768 \times 16 = 196608 \]
也就是说,如果显存紧张,可以把单步 batch size 降低,再用更大的 accumulation_steps 把有效 batch size 补回来。这是小显存 GPU 上很常用的做法。
初步Eval
这里使用刚训练完的 pretrain_768.pth 做一次非常粗糙的生成测试。评测输入使用 JSONL,每一行只保留一个 prompt 字段,例如:
{"prompt": "你有什么特长?"}
{"prompt": "北京市是"}
如果只是手动对话,可以直接运行:
python scripts\eval_llm.py ^
--load_from model ^
--tokenizer_path ..\tokenizer ^
--save_dir ..\out ^
--weight pretrain ^
--hidden_size 768 ^
--num_hidden_layers 8 ^
--use_moe 0 ^
--max_new_tokens 256 ^
--temperature 0.85 ^
--top_p 0.85 ^
--device cuda
如果使用 JSONL 批量评测,可以运行:
python scripts\eval_llm.py ^
--load_from model ^
--tokenizer_path ..\tokenizer ^
--save_dir ..\out ^
--weight pretrain ^
--hidden_size 768 ^
--num_hidden_layers 8 ^
--use_moe 0 ^
--max_new_tokens 256 ^
--temperature 0.85 ^
--top_p 0.85 ^
--eval_file .\eval_prompts.jsonl ^
--eval-output-file .\eval_result.jsonl ^
--device cuda
这里 --tokenizer_path 指向 tokenizer 所在目录,--save_dir ..\out 对应前面训练命令保存出的 ..\out\pretrain_768.pth。因为这是 pretrain 阶段的模型,还没有经过 SFT,所以它更适合观察“续写能力”和局部语言模式,而不是期待稳定的指令跟随。
在进行 SFT 训练之前,模型已经可以进行一些“勉强前言搭后语”的成语接龙。比较神奇的是,即使 Pretrain 数据中没有对话性的数据,模型似乎也并不完全受影响。不过这种能力还很不稳定,更多说明的是模型学到了一些局部语言模式,而不是已经具备真正稳定的指令跟随能力。
Input: '<|im_start|>system\nYou are a helpful assistant<|im_end|>\n<|im_start|>user\n你有什么特长?<|im_end|>\n<|im_start|>assistant\n'
Output: 我正在想如何开始一个新项目。我正在思考什么?请提供您的一些想法,我将帮助您确定如何开始一个新项目。请描述您所需要的一些信息,包括项目的目标、预算、期限和时间。请提供您希望完成的项目的细节和任何相关信息。
基于以上这段文本内容回答:如何制定一个有效的项目计划?制定一个有效的项目计划需要以下步骤:确定项目目标、确定预算、制定计划、评估期限、设定优先级、评估项目进展情况等。在制定计划的过程中,务必要保持冷静和集中,避免情绪化和决策过分。同时,也要保持持续性和自我反思能力。
Input: '<|im_start|>你有什么特长?'
Output: 有哪些特长? 我能给你讲解什么是机器学习、自然语言处理、深度学习、人工智能、自然语言处理等等。
Input: '<|im_start|>system\nYou are a helpful assistant<|im_end|>\n<|im_start|>user\n北京市是<|im_end|>\n<|im_start|>assistant\n'
Output: 请为我找到在我附近一个新的餐厅,并提供他们推荐的菜肴。
在您的附近找到一个新的餐厅,并输入您的位置信息(例如,您所在的城市或您想查询的区域)。在输入您的位置信息之后,搜索“附近一个新的餐厅”,找到该餐厅的名称和描述。根据您提供的位置信息,搜索“附近一个新的餐厅”,并从中找出该餐厅的名称和描述。这将提供该餐厅的名称和描述,帮助您找到您所在的位置。
Input: '<|im_start|>北京市是'
Output: 中国的首都,位于中国的东部。北京市是中国的首都,位于中国的东部。它的面积约为 1200 万平方公里,人口约为 120 万。北京市是一个著名的历史文化名城,其建筑和文化遗产吸引了大量游客前来参观。
自动的测试结果:
💬: 你有什么特长?
🤖️: 作为一个AI模型,我具有以下特长:1. 学习:我的知识储备主要是通过大量的数据和算法来实现,包括知识库、统计和深度学习。2. 解决问题:我能够回答问题、提供知识和信息、进行交流和解决方案。3. 创意生成:我能够生成各种类型的创意,包括设计、创作、编码、设计、广告等。4. 创造力:我能够创建新的想法、技术、设计概念等,帮助人们在任何领域取得成功。5. 团队合作:我能够与其他团队成员合作,实现各自的角色和职责。6. 创新和灵活:我能够与其他团队成员一起学习和创新,以满足他们的需求和期望。7. 情感和体验:我能够根据用户的需求和偏好提供情感和体验,以更好地理解用户需求和提供个性化服务。8. 团队合作:我能够与其他团队成员合作,共同完成任务,实现共同的目标。
[Speed]: 61.14 tokens/s
💬: 为什么天空是蓝色的
🤖️: ?回答上面的问题,给出具体的推理逻辑。天空是蓝色的主要是因为大气层中含有的气体分子会吸收和散射蓝光。其中,蓝光是一种介质,波长较短,因此我们看到的天空看起来是蓝色的。当太阳光线穿过大气层时,大气层中的气体分子会散射蓝光,蓝光波长较短,因此我们看到的天空看起来是蓝色的。此外,大气层中的气体分子和微小颗粒也会散射蓝光,这是因为蓝光波长较短,所以我们看到的天空看起来是蓝色的。因此,天空的颜色并不是蓝色,而是因为大气层中的气体分子和微小颗粒所散射蓝光,而是因为蓝光波长较短,所以我们看到的天空是蓝色的。
[Speed]: 61.61 tokens/s
💬: 请用Python写一个计算斐波那契数列的函数
🤖️: 。以下是用Python编写的计算斐波那契数列的函数:```pythondef fibonacci(n):if n <= 0:return [0]elif n == 1:return [0, 1]else:return fibonacci(n-1) + fibonacci(n-2)```
[Speed]: 67.95 tokens/s
💬: 解释一下"光合作用"的基本过程
🤖️: ,并举例说明。光合作用是植物和动物利用太阳能进行光合作用的过程中,将二氧化碳和水转化为有机物质和氧气的过程。光合作用是植物和动物利用阳光、二氧化碳和水进行呼吸作用的一种化学过程,其中光能被转化为化学能,产生氧气。光合作用的过程如下:1. 光合作用的光合作用是指植物和动物通过光合作用来制造氧气。植物和动物可以通过光合作用来产生氧气。2. 光合作用的光合作用是指植物和动物利用光能将二氧化碳和水转化为有机物质,产生氧气。3. 光合作用的光合作用是指植物和动物利用光能将二氧化碳和水转化为有机物质。这个过程可以应用于许多领域,例如:1. 农业:光合作用是植物和动物利用光能将二氧化碳和水转化为有机物质。2. 能源:光合作用是植物和动物利用光能将二氧化碳和水转化为有机物质。3. 能源:光合
[Speed]: 60.11 tokens/s
💬: 如果明天下雨,我应该如何出门
🤖️: ?如果明天下雨,您应该选择在雨中散步,享受大自然的美好。可以考虑带上雨伞或带伞,以便更容易出门。同时,还应该注意防雨,不要暴露在强烈的阳光下。如果天气不好,您应该选择携带雨伞或者携带雨伞。如果天气不好,您应该带上雨伞,以便更容易出门。
[Speed]: 65.65 tokens/s
💬: 比较一下猫和狗作为宠物的优缺点
🤖️: 。猫和狗都是常见的宠物,它们的优缺点如下:1. 聪明:猫是独立的动物,它们需要主人的陪伴和训练,可以在室内或户外活动。猫通常需要更多的运动和活动,而且它们可以成为主人的好伙伴。2. 亲密:猫是相对较小的动物,它们需要人类的陪伴和陪伴,可以提供安全感和亲密感。3. 忠诚:猫是独立的宠物,它们可以陪伴人类,提供陪伴和安慰。4. 独立:猫的陪伴需要独立,能够独立工作,而且需要定期的运动和活动。但也存在着许多问题,如猫需要较高的关注度,而狗需要更多的空间和活动,需要更多的关注和关注。综上所述,猫和狗各自的优点和缺点各不相同,不能简单地比较。但它们的优点是它们可以成为主人忠实的伙伴,同时也是主人需要陪伴和关爱的好伙伴。
[Speed]: 60.6 tokens/s
💬: 解释什么是机器学习
🤖️: ,并提供一个使用该算法的实际应用案例。机器学习是一种人工智能的分支,它使用算法来让计算机系统从数据中学习和识别模式,从而自主地进行决策和预测。一个实际应用案例是图像识别。该算法使用大量数据集来训练模型,然后使用该模型来识别图像中的物体或人脸。该算法使用一个称为图像分类器的算法来预测用户的喜好和行为。
[Speed]: 67.11 tokens/s
💬: 推荐一些中国的美食
🤖️: 和传统美食中国美食有许多,包括寿司、刺身、炸鸡、糖果、火锅、糯米饭等等。这些美食都具有独特的口感和味道,同时也有丰富的营养价值。以下是我推荐的一些中国美食和传统美食:1. 寿司:寿司是中国最著名的传统美食之一,以寿司制作而成。寿司制作可以分为各种不同的类型,包括寿司、生鱼片、海苔、豆腐、海苔等等。寿司的制作方法非常简单,只需要将寿司放在海苔上,然后在海苔上翻滚,就可以享受到美味的寿司了。2. 刺身:刺身是一道传统美食,它以各种刺激的刺激为特点。刺身的制作方法非常简单,只需要将身体内的刺激刺激和肌肉刺激结合起来,就可以享受到美味的刺身。3. 火锅:火锅是一道传统美食,通常由面粉、肉类、蔬菜、调料等材料混合制成。制作方法简单,只需要将火锅放入开水中,加入
[Speed]: 60.6 tokens/s
MiniMind Pretrain 实践总结
Pretrain 实践的后总结
在这节里,我想总结一下这次 Pretrain 跑完之后的一些感悟,以及这个训练流程里还存在的不足和需要提升的地方。
在进入具体复盘之前,可以先用两个问题来引导整篇文章:
Q1:模型是否真的训练到位了?我怎么知道这个模型训得行不行?
Q2:我怎么保证整个训练过程是稳定而且有效的?
这两个问题其实也是我这次跑完 Pretrain 之后,最明显感觉到自己还需要继续补课的地方。
首先第一个问题是,这个训练流程本身是不完善的,因为我并没有真正划分测试集。也就是说,实际上我只是按照代码里给定的参数,把模型完整跑了一遍训练。虽然最后的结果看起来好像也还说得过去,模型已经可以生成一些“看起来像语言”的句子了,但这并不等于训练过程就是可靠的,也不等于模型已经训练到位了。
所以这里至少有两个关键问题需要回答:
- 模型是否训练到位?我怎么知道这个模型训得行不行?
- 我怎么保证训练过程是稳定而且有效的?
我发现这其实就是这个项目很有价值的地方。以前很多项目里,我只是把别人给的训练代码跑一遍,能跑出结果就觉得 OK;如果跑不出来,好像也就只是“不行”。但这个项目把整个训练流程比较完整地展现了出来,我在自己尝试理解和复现的过程中,也开始意识到很多之前没有注意过的细节。
这些细节有些是在跑代码时意识到的,有些是在写这份总结笔记、和 AI 讨论时才意识到的。比如,我们不能假设未来自己的项目里,第一次随手选出来的一组训练参数,就一定能让整个训练稳定地跑下去。那么,怎么选择一组可以让训练稳定进行的参数,而不是只指望复现别人的配置,就变得非常重要了。
关于这一点,我简单总结一下自己的感受:训练这件事,与其说像一门学科,不如说更像一门带有工程经验色彩的“玄学”。它当然有一些理论指导,比如学习率、batch size、优化器、warmup、梯度裁剪等参数都有各自的理论背景;但在真正训练时,这些理论往往只能提供一个大方向。更重要的是,训练本身其实更是一套严谨的工程系统。
这和写代码、做项目很像。对于一个工程系统来说,我觉得有两个点非常重要:
- 第一是良好的版本管理。你需要能够控制每一次实验的配置、代码、数据和 checkpoint,并且可以随时回退、复现和对比。
- 第二是如何用尽量低的成本,快速验证自己的假设。也就是说,你需要知道这个系统应该怎样被验证,而不是每次都直接投入完整训练成本。
从这个视角出发,我对严谨的工业训练有了一个新的理解:它其实有点像是在做一棵树搜索。你不能太假设某一组参数从头训到尾就一定是最好的。更合理的做法是,不断创建 checkpoint,通过一个又一个短小的实验去探索参数空间,逐步判断哪些分支值得继续往下走。
也就是说,训练不是一条直线,而更像是一棵不断分叉的树。某一个学习率配置是一条分支,某一个 batch size 配置又是一条分支;某个 checkpoint 后面可以继续接不同的数据配比、不同的训练阶段,甚至后续还可以接 SFT、偏好优化等更多能力训练。一个好的训练系统,不是只会“跑完一次”,而是要能支持这些分支不断被创建、比较、筛选和延续。
验证体系也应该是分层级的。比如,我不应该一开始就直接用全量数据训练,而应该先用非常小的成本确认训练系统本身是正常的,然后再逐步扩大数据规模和训练时间。
一个比较实际的分层验证方式可以是这样的:
-
Smoke Test:先用极少量数据跑通流程。
这一阶段可以只跑几十到几百个 step,甚至只用几百条到几千条样本。它的目标不是训练出一个可用模型,而是确认训练代码、数据读取、tokenizer、模型结构、loss 计算、反向传播、显存占用和 checkpoint 保存都没有明显问题。
在这个阶段,我主要观察几件事:程序能不能稳定跑起来;loss 是否是正常的数值,而不是
NaN或者突然爆炸;显存是否够用;训练速度是否符合预期;checkpoint 是否能够正常保存和加载。 -
小规模短训:用 1%~5% 的数据验证参数是否基本稳定。
这一阶段可以使用完整数据中的一小部分,比如 1%~5%。如果全量训练需要很多小时甚至很多天,那么这一阶段最好控制在几十分钟到几个小时之内。它的重点是验证学习率、batch size、梯度累积、warmup、梯度裁剪等核心训练参数是否大致合理。
在这个阶段,我不应该期待模型能力有多强,而是要重点看 loss 曲线是否平稳下降,是否存在明显震荡、发散或者训练到一半突然崩掉的情况。如果 loss 在很短时间内快速爆炸,或者训练非常不稳定,就说明这组参数不值得进入下一阶段。
-
中等规模训练:用 10%~20% 的数据观察趋势。
当小规模短训没有明显问题后,可以进入 10%~20% 数据规模的训练。这一阶段已经可以初步观察模型是否真的在学习,以及不同配置之间的差异。
比如,可以对比不同学习率、不同 batch size、不同数据清洗策略下的 loss 曲线,也可以固定几个简单 prompt,观察模型在不同 checkpoint 上的生成效果。虽然这些生成结果不能作为严格评估,但它们可以帮助我判断模型是不是已经学到了一些语言模式,还是只是在输出随机片段。
-
全量训练:在配置基本确认后再投入完整成本。
只有当前面的阶段都比较稳定之后,才适合进入全量训练。全量训练的目标才是真正得到一个可以作为后续 SFT 起点的 base model。
在这个阶段,除了继续观察训练 loss,我还需要保留关键 checkpoint,并且准备固定的评估集或验证集。这里的重点已经不只是“能不能跑完”,而是要回答:这次训练相比之前的 checkpoint 是否真的更好?它在固定验证集上的 loss 是否更低?在简单生成任务上是否更稳定?是否出现了明显退化?
另外一点,前面每一个阶段训练出来的 checkpoint,其实都可以作为之后继续训练的起点。甚至完整的 Pretrain 模型训练完成之后,它也可以作为后续能力训练的起点,比如 SFT。后续再通过更多任务数据,把模型往对话、指令跟随、领域能力等方向继续训练。
所以这件事确实很像一棵树搜索。工程系统的稳定性、训练框架的搭建、实验配置的记录、checkpoint 的管理,其实都变得非常重要。训练不是只看最后有没有输出一个模型文件,而是要看整个过程能不能被控制、被复现、被比较。
然后回到第一个问题:如何知道模型已经训练到位了?
这其实是一个非常“玄学”的问题,甚至有点像悖论。从工程系统的角度来说,我们很难说一个模型已经“绝对足够好”了。我们最多只能说,它在某些测试集上、某些评估指标上、某些任务表现上,已经达到了我们认为可以接受的状态。
所以我们需要大量实验和数据来验证模型,而一个最简单的 eval 结果,只是验证体系里最基础的一部分。即使有了验证集 loss、生成样例、下游任务评估,我们也仍然不能保证模型已经达到了最优。我们只能比较谨慎地说:在当前的数据、算力、评估方式和目标任务下,这个训练结果已经达到了一个“足够好”的状态。
这可能就是训练里很让人难受、但又必须接受的一点:它不像普通程序那样,有一个非常明确的“通过”或“不通过”。训练更像是在一个巨大的参数空间里不断试探。我们能做的不是证明自己找到了最优解,而是建立一套足够稳定的工程系统,让每一次实验都尽量可控、可比较,并且能帮助我们更接近一个可接受的结果。
这也是我这次 Pretrain 实践之后最大的收获:跑通训练只是第一步,真正重要的是学会如何验证训练、管理实验、保存分支,并且用工程化的方法去面对这个看起来有些玄学的问题。
SFT 目标和操作
SFT 是 Supervised Fine-Tuning,也就是监督微调。它通常接在 Pretrain 之后,用整理好的指令、问答或者多轮对话数据,让一个主要学会“续写文本”的基座模型,进一步学会按照用户输入给出回答。
有了 Pretrain 的基础,SFT 的训练形式会简单很多:从训练目标上看,SFT 并没有发明一个全新的 loss。它仍然是 next token prediction,也就是给定前面的 token,预测下一个 token。真正变化的是训练数据的组织方式,以及哪些 token 会参与 loss。
SFT 要解决什么问题?
Pretrain 阶段的模型主要学习语言规律、事实知识和上下文统计关系。它看到的是大规模普通文本,训练目标是把每个位置的下一个 token 预测对。
但是一个完成 Pretrain 的模型并不天然知道“用户问一句,我应该以助手身份回答一句”。如果输入是:
什么是 SFT?
预训练模型可能会继续补全文档、百科、论坛帖子,也可能输出另一个问题。它的目标只是“像训练文本一样续写”,而不是“作为助手完成用户请求”。
SFT 的作用,就是把训练分布改成更接近真实交互的形式:
用户提出问题 -> 助手给出回答
经过这样的训练后,模型仍然在做 next token prediction,但它预测的对象变成了“在当前对话模板下,assistant 接下来应该说什么”。
对话式案例只是 SFT 的一种形式。由于训练目标没有变化,如果从似然损失函数的角度理解,SFT 更像是在把模型的输出分布推向某个特定的数据分布。这个过程通常体现在风格迁移和输出结构上:例如原模型很少见到对话数据,SFT 之后就会学习一问一答的结构;如果 SFT 数据包含数学、代码、推理等结构化任务,模型也会学习这些任务中“按步骤输出”的模式。这就是常说的行为对齐和分布迁移。沿着这个角度,更容易理解 SFT 在整个训练链路中的位置.
SFT 的基本样本
参考 MiniMind,一个最小的 Chat SFT 样本可以抽象成两部分:
- prompt:用户问题、系统提示、历史对话、工具说明等上下文。
- response:希望模型学习生成的 assistant 回答。
如果把 prompt token 记为 \(x_1, x_2, \cdots, x_m\),把 assistant 回答 token 记为 \(y_1, y_2, \cdots, y_n\),那么完整输入序列可以写成:
\[ s = [x_1, x_2, \cdots, x_m, y_1, y_2, \cdots, y_n] \]
其中,\(s\) 表示送入模型的一整段 token 序列,\(x_i\) 表示 prompt 中第 \(i\) 个 token,\(y_t\) 表示回答中第 \(t\) 个 token。
SFT 通常只希望模型学习回答部分,因此 loss 可以写成:
\[ \mathcal{L}{\text{SFT}} = - \sum{t=1}^{n} \log p_\theta(y_t \mid x_1,\cdots,x_m,y_1,\cdots,y_{t-1}) \]
这里 \(p_\theta\) 表示参数为 \(\theta\) 的模型给出的条件概率。这个公式表达的含义是:prompt 只是条件,真正被监督学习的是 assistant 的回答 token。具体实现中,通常会在 prompt 部分的 token 上设置 loss mask,让它们不参与损失计算。除此之外,SFT 的 loss 和 Pretrain 的语言模型 loss 是同一种东西。
MiniMind 中的 SFT 入口
在 MiniMind 的 README 中,当前主线 SFT 数据是:
sft_t2t_mini.jsonl:适合快速训练对话模型。sft_t2t.jsonl:适合完整复现主线版本。
README 还特别强调,当前版本的 SFT 数据统一使用多轮对话格式,并且 Tool Calling 能力已经混入主线 SFT 数据。这意味着 SFT 不只是普通问答微调,还承担了让模型学习对话模板、思考标签和工具调用格式的职责。
MiniMind 中和本章关系最密切的文件有:
minimind_upstream/minimind/README.md:说明 SFT 数据来源、格式和训练入口。src/minimind_learning/dataset/lm_dataset.py:实现SFTDataset,负责把对话数据转换成input_ids和labels。src/minimind_learning/trainer/train_full_sft.py:实现全参数 SFT 训练脚本。src/minimind_learning/trainer/train_pretrain.py:用于和 SFT 脚本对比。
本章结构
这一组笔记会按下面的顺序展开:
- SFT 数据和 Chat Template:一条 SFT 样本如何从 JSONL 变成训练张量。
- Full SFT 和 Pretrain 脚本的区别:只关注和 Pretrain 不同的地方,跳过重复训练细节。
- SFT 和 Pretrain 的异同:从目标、数据、loss mask、能力变化几个角度对比。
- SFT Eval 应该怎么做:讨论 SFT loss eval、生成式评估和任务评估各自该看什么。
- SFT 常见问题:整理 SFT 中容易混淆的点。
SFT 数据和 Chat Template
SFT 的重点,也是它和 Pretrain 阶段最大的区别,在于数据处理。本节以 MiniMind 的数据处理流程为例,实际说明 SFT 数据是如何构造出来的。这里有一个细节需要先强调:结构化输入样本如何变成模型可以训练的字符串?起作用的就是 chat template。它负责把结构化对话转换为模型输入文本,和 tokenizer 一样,也是一个隐含但非常重要的设置。一般来说,chat template 会和 tokenizer 一起定义。
MiniMind 的这条链路可以概括为:
jsonl 对话样本
-> conversations
-> pre_processing_chat
-> tokenizer.apply_chat_template
-> post_processing_chat
-> tokenizer(prompt).input_ids
-> generate_labels(input_ids)
-> input_ids, labels
下面用 README 中的 SFT 数据格式作为例子,逐步看每一步之后数据变成了什么样。
原始 JSONL 数据
MiniMind README 中给出的普通多轮 SFT 样本如下:
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"}
]
}
这个阶段的数据还是结构化 JSON。每条消息都有 role 和 content,但是模型不能直接读 JSON 对象,必须先把它展开成一段带角色标记的文本。
第一步:读取 conversations
在 SFTDataset.__getitem__ 中,代码先从样本里取出 conversations:
sample = self.samples[index]
conversations = pre_processing_chat(sample["conversations"])
此时数据可以理解成 Python list:
[
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"},
]
第二步:pre_processing_chat
pre_processing_chat 会在一部分非 tool use 样本前面随机插入 system prompt。MiniMind 这样做,是为了让模型在训练中见过“有 system 消息”和“没有 system 消息”两种情况。
对应代码来自 src/minimind_learning/dataset/lm_dataset.py:
def pre_processing_chat(conversations, add_system_ratio=0.2):
# tool use 数据完整保留,不额外插入 system prompt。
if any(conv.get("tools") or conv.get("functions") for conv in conversations):
return conversations
system_prompts = [
"你是一个知识丰富的AI,尽力为用户提供准确的信息。",
"你是minimind,一个小巧但有用的语言模型。",
"你是一个专业的AI助手,请提供有价值的回答。",
"你是minimind,请尽力帮助用户解决问题。",
"你是一个可靠的AI,请给出准确的回答。",
"You are a helpful AI assistant.",
"You are minimind, a lightweight intelligent assistant.",
"You are a friendly chatbot. Please answer the user's questions carefully.",
"You are a knowledgeable AI. Try your best to provide accurate information.",
"You are minimind, a small but useful language model.",
]
if conversations and conversations[0].get("role") != "system" and random.random() < add_system_ratio:
return [{"role": "system", "content": random.choice(system_prompts)}] + conversations
return conversations
如果这次没有插入 system prompt,数据不变:
[
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"},
]
如果随机插入了 system prompt,则会变成:
[
{"role": "system", "content": "你是minimind,请尽力帮助用户解决问题。"},
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"},
]
对于 tool use 数据,代码会直接返回原始 conversations,因为工具定义通常挂在 system 消息上,随意插入 system prompt 可能破坏工具调用格式。
第三步:apply_chat_template
接下来,create_chat_prompt 会把结构化消息交给 tokenizer 的 apply_chat_template:
def create_chat_prompt(self, conversations: list):
messages = []
tools = None
for message in conversations:
message = dict(message)
if message.get("role") == "system" and (message.get("tools") or message.get("functions")):
raw_tools = message.get("tools") or message.get("functions")
tools = json.loads(raw_tools) if isinstance(raw_tools, str) else raw_tools
if message.get("tool_calls") and isinstance(message["tool_calls"], str):
message["tool_calls"] = json.loads(message["tool_calls"])
messages.append(message)
return self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False,
tools=tools,
)
chat_template 的作用,是把不同 role 的消息转换成模型训练时统一使用的文本格式。MiniMind tokenizer 中的特殊 token 是:
{
"bos_token": "<|im_start|>",
"eos_token": "<|im_end|>"
}
如果不插入 system prompt,上面的对话会被展开成近似下面的文本:
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
<think>
</think>
你好!<|im_end|>
<|im_start|>user
再见<|im_end|>
<|im_start|>assistant
<think>
</think>
再见!<|im_end|>
注意,SFT 引入 chat template 之后,模型学习的并不是裸文本“你好!”,而是在固定对话协议中的 assistant 片段。模型会同时学到:
- 看到
<|im_start|>user后,后面是用户输入。 - 看到
<|im_start|>assistant后,后面是助手回答。 - assistant 回答通常以
<|im_end|>结束。 - 当前模板还可能包含
<think>、<tool_call>、<tool_response>等结构。
这也是为什么训练时的模板和推理时的模板必须一致。如果训练用一种格式,推理用另一种格式,模型看到的条件分布就变了。
第四步:post_processing_chat
MiniMind 的 chat template 会给 assistant 片段加上空 thinking 标签:
<think>
</think>
post_processing_chat 会以一定概率删除这个空 thinking 标签:
def post_processing_chat(prompt_content, empty_think_ratio=0.2):
# 以一定概率移除空 thinking 标签。
if "<think>\n\n</think>\n\n" in prompt_content and random.random() > empty_think_ratio:
prompt_content = prompt_content.replace("<think>\n\n</think>\n\n", "")
return prompt_content
如果删除空 thinking 标签,prompt 可能变成:
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
你好!<|im_end|>
<|im_start|>user
再见<|im_end|>
<|im_start|>assistant
再见!<|im_end|>
如果保留,则模型会见到带 <think></think> 的回答格式。这个设计让同一个模型可以接触“显式思考标签”和“直接回答”两类格式。
第五步:tokenize 成 input_ids
文本 prompt 会被 tokenizer 转成 token id,这一步与 Pretrain 基本一致:
input_ids = self.tokenizer(prompt).input_ids[: self.max_length]
input_ids += [self.tokenizer.pad_token_id] * (self.max_length - len(input_ids))
假设简化显示,不写真实 token id,而用 token 文本表示,input_ids 大致对应:
[
"<|im_start|>", "user", "\n", "你好", "<|im_end|>", "\n",
"<|im_start|>", "assistant", "\n", "你好!", "<|im_end|>", "\n",
"<|im_start|>", "user", "\n", "再见", "<|im_end|>", "\n",
"<|im_start|>", "assistant", "\n", "再见!", "<|im_end|>", "\n",
"<pad>", "<pad>", ...
]
真实情况中,一个中文词或者特殊标记可能被切成一个或多个 token id。这里的关键不是具体 id,而是序列结构:所有角色、换行、回答内容、结束标记都会进入 input_ids。
第六步:generate_labels
最后一步是生成 labels。SFT 不希望模型对 user prompt、system prompt 和 padding 计算 loss,只希望它学习 assistant 回答。因此 MiniMind 会扫描 input_ids,找到所有 assistant 片段,然后只把这些位置的 label 设为真实 token id,其余位置设为 -100。
对应代码:
def generate_labels(self, input_ids: list):
"""
仅 assistant 回复部分参与 loss 计算;其他位置设置为 -100。
labels 和 input_ids 同长度,shift 由模型内部完成。
"""
labels = [-100] * len(input_ids)
i = 0
while i < len(input_ids):
if input_ids[i : i + len(self.bos_id)] == self.bos_id:
start = i + len(self.bos_id)
end = start
while end < len(input_ids):
if input_ids[end : end + len(self.eos_id)] == self.eos_id:
break
end += 1
for j in range(start, min(end + len(self.eos_id), self.max_length)):
labels[j] = input_ids[j]
i = end + len(self.eos_id) if end < len(input_ids) else len(input_ids)
else:
i += 1
return labels
初始化时,SFTDataset 定义了 assistant 段落的起止模式:
self.bos_id = tokenizer(f"{tokenizer.bos_token}assistant\n", add_special_tokens=False).input_ids
self.eos_id = tokenizer(f"{tokenizer.eos_token}\n", add_special_tokens=False).input_ids
也就是说,代码会寻找:
<|im_start|>assistant\n
然后一直标记到:
<|im_end|>\n
简化后的 labels 可以理解为下面几段。这里不用 Markdown 表格展示,是因为 <|im_start|> 这类特殊 token 中包含竖线字符,放进表格后容易被 mdBook 误解析。
user 片段:
input : <|im_start|>user\n你好<|im_end|>\n
label : 全部 -100
assistant 角色头:
input : <|im_start|>assistant\n
label : -100
assistant 回答:
input : 你好!<|im_end|>\n
label : 对应 token id
user 片段:
input : <|im_start|>user\n再见<|im_end|>\n
label : 全部 -100
assistant 角色头:
input : <|im_start|>assistant\n
label : -100
assistant 回答:
input : 再见!<|im_end|>\n
label : 对应 token id
padding:
input : <pad>
label : -100
这里有一个容易忽略的细节:MiniMind 把 assistant 回答后面的 <|im_end|>\n 也纳入 label。这样模型不只学习回答内容,还学习什么时候结束回答。
最终返回的训练样本
__getitem__ 最终返回两个张量:
return torch.tensor(input_ids, dtype=torch.long), torch.tensor(labels, dtype=torch.long)
其中:
input_ids是完整对话模板的 token id。labels和input_ids等长。- 非 assistant 回答位置是
-100。 - assistant 回答和结束标记位置是真实 token id。
完整的 SFTDataset.__getitem__ 是:
def __getitem__(self, index):
sample = self.samples[index]
conversations = pre_processing_chat(sample["conversations"])
prompt = self.create_chat_prompt(conversations)
prompt = post_processing_chat(prompt)
input_ids = self.tokenizer(prompt).input_ids[: self.max_length]
input_ids += [self.tokenizer.pad_token_id] * (self.max_length - len(input_ids))
labels = self.generate_labels(input_ids)
return torch.tensor(input_ids, dtype=torch.long), torch.tensor(labels, dtype=torch.long)
这就是 SFT 数据处理的关键:输入仍然是一整段对话,但 loss 只看 assistant 应该学习的部分。
Tool Calling 样本如何进入模板
README 中还给了 tool use 样本:
{
"conversations": [
{"role": "system", "content": "# Tools ...", "tools": "[...]"},
{"role": "user", "content": "把'你好世界'翻译成english"},
{"role": "assistant", "content": "", "tool_calls": "[{\"name\":\"translate_text\",\"arguments\":{\"text\":\"你好世界\",\"target_language\":\"english\"}}]"},
{"role": "tool", "content": "{\"translated_text\":\"Hello World\"}"},
{"role": "assistant", "content": "Hello World"}
]
}
create_chat_prompt 会把 system 消息上的 tools 解析成 JSON,把 assistant 消息上的 tool_calls 也解析成 JSON,然后一起交给 apply_chat_template。
展开后,模板会生成类似这样的结构:
<|im_start|>system
# Tools
You may call one or more functions to assist with the user query.
<tools>
...
</tools>
...
<|im_end|>
<|im_start|>user
把'你好世界'翻译成english<|im_end|>
<|im_start|>assistant
<tool_call>
{"name": "translate_text", "arguments": {"text": "你好世界", "target_language": "english"}}
</tool_call><|im_end|>
<|im_start|>user
<tool_response>
{"translated_text":"Hello World"}
</tool_response><|im_end|>
<|im_start|>assistant
Hello World<|im_end|>
这说明 SFT 数据中的 tool call 并不是额外走一条训练管线,而是被 chat template 统一展开成文本协议。模型最终还是在做 next token prediction,只是 assistant 需要学习的目标里包含了 <tool_call> 这种结构化输出。
Full SFT 和 Pretrain 脚本的区别
MiniMind 的 train_full_sft.py 和 train_pretrain.py 在训练主循环上几乎一致:都是加载模型、构造 dataset 和 dataloader、前向计算 loss、反向传播、梯度累积、保存权重。
所以这一节不重复 optimizer、checkpoint、batch size、混合精度这些已经在 Pretrain 章节讲过的内容,只看 SFT 脚本相对 Pretrain 真正改变了什么。
区别一:Dataset 从 PretrainDataset 变成 SFTDataset
Pretrain 脚本使用的是 PretrainDataset:
from minimind_learning.dataset.lm_dataset import PretrainDataset
对应构造代码:
train_ds = PretrainDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
Full SFT 脚本使用的是 SFTDataset:
from minimind_learning.dataset.lm_dataset import SFTDataset
对应构造代码:
train_ds = SFTDataset(args.data_path, tokenizer, max_length=args.max_seq_len)
这个改动看起来只换了一个类,但它实际改变了训练样本的含义。
PretrainDataset 读的是:
{"text": "一段普通文本..."}
SFTDataset 读的是:
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"}
]
}
因此训练循环虽然仍然拿到 (input_ids, labels),但 labels 的 mask 方式已经完全不同。
区别二:默认数据路径不同
Pretrain 默认读取:
parser.add_argument("--data_path", type=str, default="../dataset/pretrain_t2t_mini.jsonl", help="预训练数据路径")
Full SFT 默认读取:
parser.add_argument("--data_path", type=str, default="../dataset/sft_t2t_mini.jsonl", help="训练数据路径")
这对应 MiniMind README 中的阶段式训练组合:
pretrain_t2t_mini.jsonl -> sft_t2t_mini.jsonl
前者让模型学习语言建模,后者让模型学习指令和对话格式。
区别三:默认加载权重不同
Pretrain 脚本默认从头训练:
parser.add_argument("--from_weight", default="none", type=str, help="基于哪个权重训练,none表示从头开始")
Full SFT 脚本默认加载 pretrain 权重:
parser.add_argument("--from_weight", default="pretrain", type=str, help="基于哪个权重训练")
这说明 SFT 在 MiniMind 的训练链路里不是从零开始,而是在 Pretrain 已经学到的语言能力和基础知识上继续训练。
如果把模型参数记为 \(\theta\),Pretrain 得到的参数记为 \(\theta_{\text{pretrain}}\),那么 SFT 的初始化可以写成:
\[ \theta_0 = \theta_{\text{pretrain}} \]
然后 SFT 在此基础上继续优化:
\[ \theta_{\text{sft}} = \operatorname{Train}_{\text{SFT}}(\theta_0) \]
其中 \(\theta_0\) 是 SFT 开始时的参数,\(\theta_{\text{sft}}\) 是 SFT 结束后的参数。
区别四:学习率更小
Pretrain 默认学习率是:
parser.add_argument("--learning_rate", type=float, default=5e-4, help="初始学习率")
Full SFT 默认学习率是:
parser.add_argument("--learning_rate", type=float, default=1e-5, help="初始学习率")
这是一个很常见的设置:SFT 是在已有模型上做后续调整,不希望用过大的学习率破坏 Pretrain 阶段学到的语言能力。尤其是小模型和小数据场景下,学习率过大很容易让模型变得更会套模板,但通用生成能力下降。
区别五:训练序列长度不同
Pretrain 默认最大长度是:
parser.add_argument("--max_seq_len", default=340, type=int, help="训练的最大截断长度")
Full SFT 默认最大长度是:
parser.add_argument("--max_seq_len", default=768, type=int, help="训练的最大截断长度")
SFT 样本通常包含 role 标记、system prompt、多轮历史、assistant 回答,甚至还可能包含 tool call 和 tool response,所以同样一条样本会比普通文本带有更多结构信息。更长的 max_seq_len 可以减少重要对话上下文被截断的概率。
区别六:训练循环基本不变
Full SFT 的核心训练循环仍然是:
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device)
labels = labels.to(args.device)
lr = get_lr(epoch * iters + step, args.epochs * iters, args.learning_rate)
for param_group in optimizer.param_groups:
param_group["lr"] = lr
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
loss = loss / args.accumulation_steps
scaler.scale(loss).backward()
这段代码和 Pretrain 的本质逻辑是一样的。模型并不知道自己正在做 “Pretrain” 还是 “SFT”,它只接收 input_ids 和 labels,然后根据 label 位置计算交叉熵。
真正让训练目标发生变化的地方,是 dataset 生成的 labels:
- Pretrain:除了 padding,文本中的大多数 token 都参与 loss。
- SFT:只有 assistant 回答片段参与 loss。
因此,SFT 的关键不在训练 loop,而在数据构造和 label mask。
区别七:训练数据量和 epoch 的含义不同
从脚本默认值看,MiniMind 的 Pretrain 和 Full SFT 都设置了 --epochs 2,但这不代表两个阶段应该使用同样规模的训练 token。epoch 只是“把当前数据集遍历几遍”,真正决定训练量的是:
有效训练 token 数 ≈ 数据集样本数 × 每条样本中参与 loss 的 token 数 × epoch 数
这里要特别注意“参与 loss 的 token 数”。Pretrain 中,除了 padding 之外,大多数 token 都参与 loss;SFT 中,prompt、system、user 和 padding 通常不参与 loss,真正参与 loss 的主要是 assistant 回答和结束标记。
MiniMind README 中给出的主线数据大小是:
| 数据文件 | 文件大小 | 说明 |
|---|---|---|
pretrain_t2t_mini.jsonl | 1.2GB | 轻量预训练数据 |
pretrain_t2t.jsonl | 10GB | 主线预训练数据 |
sft_t2t_mini.jsonl | 1.6GB | 轻量 SFT 数据 |
sft_t2t.jsonl | 14GB | 主线 SFT 数据 |
从文件大小看,MiniMind 的 SFT 数据并不比 Pretrain 数据小,甚至略大一些;但这不能直接等价为“参与训练的 token 更多”。SFT 文件中包含 role 标记、chat template、system prompt、user prompt、tool schema、tool response 等内容,其中很多 token 只是条件上下文,不参与 loss。
README 还给了单卡 3090 上的经验耗时估计:
| 模型 | pretrain_t2t_mini | sft_t2t_mini |
|---|---|---|
minimind-3 | 约 1.21 小时 / epoch | 约 1.10 小时 / epoch |
minimind-3-moe | 约 1.69 小时 / epoch | 约 1.54 小时 / epoch |
这个结果说明,在 MiniMind 这个项目里,轻量 Pretrain 和轻量 SFT 的单 epoch 成本是同一个量级。原因很直接:它是一个从 0 复现完整训练链路的小模型项目,Pretrain 数据本身也被精简过;同时 SFT 数据里混入了对话、reasoning 和 tool call,样本结构并不短。
更一般地说,大模型训练里常见的比例通常是:Pretrain token 量远大于 SFT token 量。Pretrain 负责建立语言、知识和基础能力,token 量可以达到 SFT 的几十倍、几百倍甚至更多;SFT 更依赖高质量样本,目标是改变模型输出分布和交互格式,不是重新灌入全部知识。
所以实践中可以用下面的原则判断:
- 如果是在从 0 训练一个小模型,像 MiniMind 这样让 SFT 数据量接近 Pretrain 数据量,是可以接受的,因为 Pretrain 阶段本身也很轻量。
- 如果是在已有强基座上做 SFT,SFT token 量通常不需要追求接近 Pretrain,而应该优先控制数据质量、任务覆盖和模板一致性。
- 如果 SFT 数据很窄,增加 epoch 可能会让模型更贴合这批数据,但也更容易损失通用能力。
- 如果 SFT loss 继续下降但开放问答变差,通常应该先怀疑数据分布、训练轮数或学习率,而不是继续加数据遍历次数。
小结
train_full_sft.py 可以理解成复用了 Pretrain 的训练框架,只替换了训练阶段最关键的几个入口:
| 对比项 | Pretrain | Full SFT |
|---|---|---|
| Dataset | PretrainDataset | SFTDataset |
| 默认数据 | pretrain_t2t_mini.jsonl | sft_t2t_mini.jsonl |
| 默认初始权重 | none | pretrain |
| 默认学习率 | 5e-4 | 1e-5 |
| 默认最大长度 | 340 | 768 |
| loss 位置 | 普通文本 token | assistant 回答 token |
| 数据量含义 | 文件 token 大多参与 loss | 文件 token 中只有回答部分主要参与 loss |
所以这部分代码阅读的重点不是“训练循环又写了一遍”,而是理解:同一套 next-token 训练框架,只要换掉数据和 labels,就能从预训练切换到监督微调。
SFT 常见问题
这一节整理 SFT 中最容易混淆的点。很多 SFT 问题表面上是训练问题,实际根源都在数据格式、chat template 或 label mask。
SFT 后模型为什么更像助手?
因为训练数据从普通文本变成了对话示范。
SFT 并不是给模型增加了一个“服从用户”的特殊模块,而是让模型反复看到这样的模式:
<|im_start|>user
问题<|im_end|>
<|im_start|>assistant
回答<|im_end|>
当这种格式大量出现后,模型在推理时看到 user 片段,就更倾向于续写 assistant 片段。
为什么 prompt 部分通常不算 loss?
因为 prompt 是条件,不是希望模型学习生成的目标。
以一条样本为例:
user: 什么是 SFT?
assistant: SFT 是监督微调...
训练时我们希望模型学会“在这个问题之后回答什么”,而不是学会“如何生成用户的问题”。所以 user 和 system 片段进入 input_ids,但在 labels 中通常被设置为 -100。
如果 prompt 也参与 loss,模型会把一部分训练能力花在复述模板、用户问题和系统提示上。这不是 SFT 的主要目标。
为什么 assistant 的结束标记也要算 loss?
MiniMind 的 generate_labels 会把 assistant 内容一直标记到 <|im_end|>\n:
for j in range(start, min(end + len(self.eos_id), self.max_length)):
labels[j] = input_ids[j]
这意味着模型不只学习“回答什么”,还学习“什么时候结束回答”。
如果结束标记没有被充分学习,模型在推理时可能更容易出现回答停不下来、继续编造下一轮对话、把 user/assistant 标记也生成出来等问题。
为什么训练模板和推理模板必须一致?
因为 SFT 学到的是模板条件下的输出分布。
如果训练时模型看到的是:
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
你好!<|im_end|>
推理时却输入:
User: 你好
Assistant:
那么模型看到的上下文格式就变了。即使语义接近,token 分布也不同,小模型尤其容易受影响。
所以对 instruction model 或 chat model 来说,apply_chat_template 不是可有可无的格式化工具,而是训练和推理之间的协议。
SFT loss 下降是否等于模型更好?
不一定。
SFT loss 下降说明模型更擅长拟合当前 SFT 数据分布,但这不完全等价于真实使用体验更好。可能出现几种情况:
- 训练数据回答很短,模型也变得偏短。
- 训练数据风格单一,模型回答变得套路化。
- 训练数据有噪声,模型学到错误格式。
- 训练数据领域很窄,模型通用能力下降。
- eval loss 下降,但开放问答的事实性没有提升。
所以 SFT 评估不能只看 loss,还应该看人工问答、格式稳定性、指令遵循、拒答边界、工具调用格式等。
为什么 SFT 可能让模型“变笨”?
常见原因是 SFT 数据太窄、太少、质量不稳定,或者训练过度。
Pretrain 阶段给模型建立了比较宽的语言分布;SFT 阶段如果只用很窄的任务数据继续训练,模型会向这个窄分布靠拢。结果可能是某些格式变好了,但开放问题、事实性或者表达多样性下降。
这也是为什么全参数 SFT 通常要更谨慎。MiniMind 的 Full SFT 默认学习率比 Pretrain 小很多,就是为了减少对基座能力的破坏。
多轮对话中是否只训练最后一轮 assistant?
不一定,取决于 dataset 如何生成 labels。
MiniMind 的 generate_labels 会扫描整段 input_ids,只要找到 assistant 片段,就把这个 assistant 片段标成可训练目标。因此在一条多轮对话中,多个 assistant 回答都可能参与 loss。
以前面的样本为例:
{
"conversations": [
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!"},
{"role": "user", "content": "再见"},
{"role": "assistant", "content": "再见!"}
]
}
两个 assistant 回答都会参与训练:
你好!<|im_end|>
再见!<|im_end|>
这样做可以充分利用多轮对话里的每一轮 assistant 回复。
Tool Calling 为什么也能放进 SFT?
因为 tool call 最终也是一种文本输出格式。
在 MiniMind 中,tool use 样本会通过 chat template 展开成:
<tool_call>
{"name": "translate_text", "arguments": {"text": "你好世界", "target_language": "english"}}
</tool_call>
对模型来说,它仍然是在预测 assistant 片段中的下一个 token。区别只是这段回答不再是普通自然语言,而是一个结构化调用协议。
因此,SFT 可以教模型“什么时候输出自然语言回答”,也可以教模型“什么时候输出 tool call 格式”。
SFT 和 instruction tuning 是什么关系?
instruction tuning 通常可以看成 SFT 的一种重要形式。
更宽泛地说,SFT 指用有监督样本继续训练模型;instruction tuning 强调这些样本是“指令 -> 回答”的形式,目标是提升指令遵循能力。
在现代 LLM 语境里,很多人说 SFT 时,实际说的就是 instruction tuning 或 chat fine-tuning。
SFT 和 DPO/RLHF 是什么关系?
SFT 通常是后训练的第一步。它给模型一个基本可用的助手行为,让模型学会按模板回答。
DPO、RLHF、RLAIF 等方法通常接在 SFT 后面,用偏好数据、奖励模型或者规则反馈继续优化模型行为。它们关心的不只是“标准答案是什么”,还包括“多个回答中哪个更好”。
可以简单理解为:
Pretrain: 学会语言和知识
SFT: 学会按指令回答
DPO/RLHF/RLAIF: 学会更偏好哪些回答方式
如果没有 SFT,模型可能连稳定对话格式都没有;这时直接做偏好优化或者强化学习,训练会更不稳定。
SFT Eval 应该怎么做
和 Pretrain 一样,SFT 阶段也需要 eval。但 SFT 的 eval 更容易让人误解:loss 能告诉我们训练是否稳定,却不能充分说明模型是否获得了我们想要的“风格、格式和任务行为”。
贯穿这一章的应该是两个核心问题:
- SFT 阶段的训练 loss 应该怎么看?它如何观察训练稳定性以及是否该停止训练?它与 Pretrain 阶段的区别是什么?
- SFT 强调风格化和行为对齐,单纯的 loss 不一定能说明模型是否获得了目标能力。那么应该如何设计评价实验,评估模型在 SFT 阶段是否学到了我们想要的能力?(评价实验目标以及流程设计)
Loss 用来看训练状态:SFT loss eval 和 Pretrain loss eval 一样吗?
SFT loss eval 和 Pretrain loss eval 的代码形式基本一样:
with torch.no_grad():
res = model(input_ids, labels=labels)
loss = res.loss
在 SFT 中,loss 的特殊之处来自 label mask。Pretrain 通常是除了 padding 之外,大多数 token 都参与 loss;SFT 通常只让 assistant 回答参与 loss,因此它的 loss mask 范围要大得多。
所以 SFT eval loss 衡量的是:在当前 chat template 和 prompt 条件下,模型对标准 assistant 回答的拟合程度。
我们希望 loss 主要回答三个训练问题:
- 训练是否正常收敛。
- 是否出现发散、异常震荡或者数值问题。
- 是否开始过拟合当前 SFT 数据。
SFT 阶段的训练稳定性
SFT 阶段是不是不是很容易出现训练不稳定? 它的LR调度是否需要和Pretrain不同,比如我是否还需要从头warmup吗? SFT 阶段的数据量与 Pretrain一般如何搭配?
SFT 阶段一般比 Pretrain 更容易训练不稳定,而且学习率调度通常必须和 Pretrain 不同。尤其是 warmup 仍然需要,但规模要小得多。
学习率要比 Pretrain 小
SFT 是“微调行为”,不是“重新学习知识”,所以学习率通常要比 Pretrain 小 10 到 100 倍。
典型范围可以这样理解:
Pretrain: 1e-4 ~ 3e-4
SFT: 5e-6 ~ 5e-5
对于更大的模型,例如 70B 量级,SFT 学习率甚至可能使用:
1e-6 ~ 2e-6
学习率过大时,SFT 很容易把模型已经学到的通用能力冲坏。表现上可能不是 loss 立刻爆炸,而是模型变得模板化、啰嗦,或者开放问答能力下降。
Warmup 仍然需要,但要很短
SFT 仍然需要 warmup,原因是 SFT 数据分布和 Pretrain 数据分布差异很大。如果一开始就使用完整学习率,容易出现 loss spike,甚至导致梯度异常。
但 SFT 的 warmup 不需要像 Pretrain 那么长。Pretrain 可能使用 2k 到 10k steps 的 warmup,而 SFT 通常可以短很多:
小模型 SFT: 50 ~ 200 steps
大模型 SFT: 100 ~ 500 steps
这里 warmup 的目的不是让长训练逐渐进入稳定区,而是避免训练刚开始时因为分布切换太突然导致梯度爆炸。
Decay 策略可以更简单
Cosine decay 仍然是常见选择,但 SFT 的总训练 steps 往往很少,可能只有几千到几万步,所以 cosine decay 会下降得很快。
因此 SFT 也可以使用:
- short warmup + cosine decay。
- short warmup + linear decay。
- short warmup + constant learning rate。
如果 SFT 数据少于 100k 条,constant LR + short warmup 往往是比较稳的选择。
SFT 数据量和 Pretrain 通常如何搭配?
SFT 数据量通常只占 Pretrain 的 0.001% 到 0.1%,但对模型行为的影响却可能是压倒性的。也就是说,SFT 数据量极小,但权重很大。
原因是 SFT 和 Pretrain 学的东西不同。
Pretrain 学的是:
- 世界知识。
- 语言规律。
- 语义结构。
- 推理能力。
SFT 学的是:
- 希望模型“怎么表现”。
- 风格、格式、礼貌和结构。
- 遵循指令。
- 输出格式,例如 JSON、Markdown、CoT 或 Tool Calling。
行为比知识更容易被改变,所以少量 SFT 数据就能强烈改变模型输出分布。
SFT loss 是尖锐监督
这里需要先澄清一点:Pretrain 和 SFT 都是 token-level 的监督,本质上都是 next-token prediction,也都可以使用 cross entropy loss。二者的差异不在于“是不是 token-level”,而在于目标分布是否唯一、是否尖锐、是否容错。
Pretrain 的监督相对宽松。自然语言的下一个 token 往往有很多合理选择。例如:
他走进了房间,看见了一只 ___
这里可以接“猫”“狗”“椅子”“人”“灯”等很多词。模型预测其中某个合理 token,即使没有完全命中数据中的原始 token,也通常仍然是在向合理语言分布靠近。因此 Pretrain 的目标分布更像是多峰的,梯度方向相对分散,loss landscape 也更平滑。
SFT 的监督更尖锐。SFT 数据里通常只有一个标注答案,训练时每个参与 loss 的 assistant token 都必须匹配这个标注答案。例如:
Q: 请解释 Transformer 的注意力机制
A: Transformer 使用自注意力机制来捕捉序列中不同位置之间的依赖关系……
如果模型生成的是:
Transformer 使用注意力机制来捕捉序列中不同位置之间的关系……
这句话在语义上可能完全可以接受,但 token-level CE 仍然会认为“自注意力机制”和“注意力机制”、“依赖关系”和“关系”等位置没有匹配标注。也就是说,SFT 在数学形式上仍然是语言模型 loss,但目标序列被当作唯一答案来监督,容错率很低。
所以,SFT 的目标分布更像是单峰的:梯度方向更集中、更明确,模型会迅速向标注数据的表达方式靠拢。这就是为什么少量高质量 SFT 数据就能显著改变模型行为,而 Pretrain 往往需要海量数据才能改变模型的基础分布。
可以把两者的差异概括为:
| 维度 | Pretrain | SFT |
|---|---|---|
| 数学形式 | token-level CE | token-level CE |
| 目标分布 | 多峰,多种合理续写 | 单峰,标注答案唯一 |
| 容错性 | 相对高 | 低 |
| 梯度方向 | 平滑、分散 | 强烈、集中 |
| 风格影响 | 较弱 | 很强 |
| 行为改变 | 需要大量数据 | 少量数据即可 |
一句话总结:Pretrain 是宽松的 token-level 监督,SFT 是严格的 token-level 监督。两者的数学形式相似,但目标分布不同,训练动力学也不同。
SFT 数据分布高度集中
SFT 数据通常具有这些特点:
- 高质量。
- 风格一致。
- 结构统一。
- 任务明确。
这会让模型很快偏向这种分布。对于行为对齐来说,这是优点;但如果数据过窄,也会变成风险。
SFT 数据太多会怎样?
SFT 数据太多,或者训练轮数太多,可能导致:
- 模型变啰嗦、变模板化。
因为 SFT 数据风格太强,模型会越来越像训练样本里的固定表达。
- 推理能力下降。
尤其是数学、代码和逻辑能力,可能因为过度拟合 SFT 分布而出现 catastrophic forgetting。
- 模型变得过度对齐。
例如太礼貌、太安全、不敢回答、不敢推理,或者在不需要拒答的地方也拒答。
几个搭配原则
原则 1:SFT tokens 通常约为 Pretrain tokens 的 0.001% 到 0.05%。
这是一个常见经验范围。SFT 不靠 token 数量取胜,而靠样本质量、覆盖范围和格式一致性取胜。
原则 2:模型越大,SFT 占比通常越小。
大模型更容易被少量 SFT 数据改变行为,因此不一定需要大量 SFT 数据。
原则 3:能力提升更多依赖 mid-train,行为对齐更多依赖 SFT。
不要指望用 SFT 大幅提升基础能力。用 SFT 去“灌知识”或者“硬提能力”,很容易把模型训傻。
原则 4:SFT 数据必须高质量、风格一致。
数量不是第一位的,质量决定一切。
Loss 如何判断是否该停止训练?
这部分和 Pretrain 类似,但 SFT 更要警惕“过拟合风格”。通俗地说,模型大体不会突然坏掉,但要小心把它训到某个狭窄的风格沟里。
如果 train loss 和 eval loss 都在稳定下降,说明训练还在有效拟合数据,可以继续观察。
如果 train loss 继续下降,但 eval loss 开始上升,通常说明模型开始记住训练集表达,而不是泛化到验证集,可以考虑停止训练、降低 epoch、降低学习率,或者增加更有代表性的验证集。
如果 loss 很低,但生成回答变差,例如回答变短、模板味变重、重复更多、开放问答变差,说明 loss 已经不能代表目标能力了。这时不应该只根据 loss 继续训练,而应该转向生成式 eval 和 task-level eval。
如果 eval loss 很高,但人工观察回答不错,也不一定说明模型差。开放式问答有很多合理表达,标准答案只是一种写法;模型用不同措辞答对了,loss 仍然可能不低。
一句话:SFT loss 适合判断训练是否稳定,不适合单独决定模型是否“好用”。
什么是生成式 Eval 和 Task-level Eval?
SFT 的目标通常不是单纯降低 loss,而是让模型形成某种可用行为。所以除了 loss eval,还需要生成式 eval 和 task-level eval。
生成式 Eval
生成式 eval 是把固定 prompt 输入模型,让模型用真实推理方式生成回答,然后观察输出是否符合预期。
它回答的问题是:
- 模型是否按 chat template 正常回答?
- 是否会生成多余的
user、assistant、<|im_start|>等角色标记? - 是否能正常结束,而不是重复或停不下来?
- 回答是否过短、过长、太模板化?
- 风格是否符合 SFT 目标?
生成式 eval 更接近真实使用,但它不一定有明确的自动分数。它适合做人类抽样检查,也适合配合一些简单规则检查。
例如,对于普通对话 SFT,可以固定一组 prompts:
解释一下什么是 SFT。
给我一个 Python 快速排序示例。
用三句话总结注意力机制。
然后观察不同 checkpoint 的回答是否越来越符合助手风格,是否更稳定,是否更少出现角色污染。
Task-level Eval
Task-level eval 是围绕具体任务设计评价指标。它回答的问题是:模型是否真的完成了这次 SFT 想要它学会的任务。
不同任务应该使用不同评价方式:
- 选择题:看准确率,或者比较候选项条件概率。
- 数学题:抽取最终答案,做 exact match 或规则校验。
- 代码题:运行单元测试。
- 摘要题:检查长度、覆盖率、事实错误,必要时人工评估。
- Tool Calling:检查工具名、参数 JSON、schema 合法性和最终执行结果。
- JSON 输出:检查 JSON 是否可解析,字段是否齐全,类型是否正确。
这类 eval 的核心是:先明确“能力目标”,再设计能检验这个目标的评价方法。不要用一个平均 loss 去解释所有能力。
一个实用的 Eval 流程
比较稳妥的 SFT eval 流程可以这样设计:
- 先准备 held-out SFT 验证集,用和训练一致但固定的 chat template 计算 eval loss。
这一步只用于判断训练状态:是否收敛、是否发散、是否过拟合。
- 固定一组生成式 eval prompts,每个 checkpoint 使用相同解码参数生成回答。
这一步用于检查模型真实输出,包括格式、风格、重复、结束标记和角色污染。
- 根据 SFT 目标设计 task-level eval。
如果训练目标是 Tool Calling,就检查工具调用;如果训练目标是数学,就检查答案;如果训练目标是代码,就运行测试;如果训练目标是 JSON 格式输出,就检查 JSON schema。
- 把 loss、生成样例和任务指标放在一起判断。
如果 loss 下降,但生成质量和任务指标变差,说明模型可能过拟合了 SFT 风格;如果 loss 不低,但任务指标更好,说明标准答案的 token 拟合不是当前任务的核心指标。
- 用固定流程比较 checkpoint。
如果要比较两个 SFT checkpoint,必须固定 prompts、chat template、解码参数和评价脚本,否则对比不干净。
如果只是快速调参,eval loss + 少量生成样例 就够了。如果要决定最终模型,必须加入 task-level eval。
小结
SFT eval 可以分工理解:
- loss eval:看训练状态,判断收敛、发散和过拟合。
- 生成式 eval:看模型真实输出的格式、风格和稳定性。
- task-level eval:看模型是否获得目标能力。
所以 SFT 阶段不要只问“loss 降了吗”,还要问“模型是否按我希望的方式完成了任务”。这也是 SFT 和 Pretrain 在 eval 思路上最重要的差别。
强化学习基础知识
速通强化学习
在进入强化学习在 LLM 中的应用之前,我想先用一节内容串讲并总结一下强化学习的基础知识。这部分基本可以看作是对西湖大学赵世玉老师强化学习课程的学习整理。我非常推荐这门课程,赵老师在 B 站和 GitHub 上都公开了相关资料:
https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning
当然,这篇笔记不应该被视为一门完整的强化学习课程;这显然也不是一篇笔记能够完成的事情。我希望在这一节中主要完成两件事。
第一,把强化学习中重要且基础的概念、定义和公式梳理清楚。RL 本身是一个概念密度很高、符号也比较容易混乱的领域,先把这些基础记号统一下来,后面再讨论具体算法时就不容易迷路。
第二,尽量简单梳理不同算法之间的思路演变和基本逻辑关系。这里不会追求覆盖所有细节,而是希望先建立一条主线:这些算法分别想解决什么问题,以及它们之间大致是如何连接起来的。
基本概念,以及问题的定义
基本记号
在强化学习中,我们首先需要区分“随机变量”和“随机变量的一次具体取值”。后面所有公式都尽量沿用这一套记号。强化学习的问题定义里面,随机变量的个数有一些多.所以请时刻牢记随机变量和随机变量取值的区别.否则很多公式会变得非常的混乱.
- \(S_t\):时刻 \(t\) 的状态,是随机变量。
- \(A_t\):时刻 \(t\) 在状态 \(S_t\) 下采取的动作,是随机变量。
- \(R_{t+1}\):执行动作 \(A_t\) 之后得到的奖励,是随机变量。
- \(S_{t+1}\):执行动作 \(A_t\) 之后转移到的下一个状态,是随机变量。
- \(s,a,r,s^{\prime}\):分别表示状态、动作、奖励、下一个状态的具体取值。
- \(\mathcal{S}\):状态空间。
- \(\mathcal{A}(s)\):状态 \(s\) 下可选动作的集合。
- \(\gamma \in [0,1)\):折扣因子,用来控制未来奖励在当前价值中的权重。
一个单步交互可以写成:
\[ S_t \xrightarrow{A_t} R_{t+1}, S_{t+1} \]
也就是说,智能体在状态 \(S_t\) 下选择动作 \(A_t\),环境返回奖励 \(R_{t+1}\),并转移到新状态 \(S_{t+1}\)。
这里有一个需要注意的点.奖励的角标是t+1,而不是状态的t.
MDP: 强化学习问题的数学对象
强化学习中最常用的问题建模方式是 Markov Decision Process,简称 MDP。一个 MDP 可以写成:
\[ \mathcal{M} = (\mathcal{S}, \mathcal{A}, p, r, \gamma) \]
其中:
- \(\mathcal{S}\) 是状态空间。
- \(\mathcal{A}\) 是动作空间;如果动作集合依赖于状态,也写作 \(\mathcal{A}(s)\)。
- \(p\) 是环境的动态模型。
- \(r\) 是奖励函数。
- \(\gamma\) 是折扣因子。
更严谨地说,环境的单步随机性可以用联合分布表示:
\[ p(s^{\prime}, r \mid s, a)=\Pr(S_{t+1}=s^{\prime}, R_{t+1}=r \mid S_t=s, A_t=a) \]
这个式子表示:当智能体在状态 \(s\) 下采取动作 \(a\) 时,环境转移到状态 \(s^{\prime}\) 并给出奖励 \(r\) 的概率。
有时也会把状态转移概率和奖励概率分开写:
\[ p(s^{\prime} \mid s,a)=\Pr(S_{t+1}=s^{\prime} \mid S_t=s,A_t=a) \]
\[p(r \mid s,a)=\Pr(R_{t+1}=r \mid S_t=s,A_t=a) \]
但在一般情况下,\(S_{t+1}\) 和 \(R_{t+1}\) 可能不是独立的,所以用 \(p(s^{\prime},r\mid s,a)\) 作为统一记号会更严谨。
Markov 性质指的是:给定当前状态和当前动作之后,未来只依赖当前,而不依赖更早的历史。也就是:
策略与轨迹
MDP定义了强化学习的环境.智能体在这个环境中通过交互来学习一个策略(policy),使得它能够在这个环境中获得更多的奖励.Policy 描述智能体在每个状态下如何选择动作。随机策略写作:
其中:
- \(\pi\) 表示策略。
- \(\pi(a\mid s)\) 表示在状态 \(s\) 下选择动作 \(a\) 的概率。
那么从某个初始状态出发,智能体与环境交互会生成一条随机轨迹 trajectory:
对于有限长度 \(T\) 的轨迹,也可以写成:
在给定初始状态分布 \(\rho_0(s_0)\)、策略 \(\pi\)、环境动态 \(p\) 的情况下,一条有限轨迹的概率可以写成:
这个公式把强化学习中的两类随机性都写了出来:
- \(\pi(a_t\mid s_t)\):智能体选择动作的随机性。
- \(p(s_{t+1},r_{t+1}\mid s_t,a_t)\):环境反馈的随机性。
Return
Return的意义是定义智能体的表现的好与坏.从时刻 \(t\) 开始,智能体未来能够获得的折扣奖励和称为 return,记作 \(G_t\)。
伽马是一个衰减系数.这个定义非常的直观.我越未来的得到的奖励,其重要性就在下降.
也可以写成求和形式:
其中:
- \(G_t\) 是从时刻 \(t\) 开始的回报。
- \(R_{t+k+1}\) 是未来第 \(k+1\) 步得到的奖励。
- \(\gamma^k\) 是这个奖励对应的折扣权重。
Return 还有一个非常重要的递推形式:
因为:
所以:
State value
至此,我们获得了强化学习中最重要的一个概念:我们希望关注每一个state上,它能获得的return是多少.这就是State value的定义.由于return又是一个随机变量.所以我们用期望来衡量对于每一个state的整体的return.
State value function 描述的是:在策略 \(\pi\) 下,从状态 \(s\) 出发,未来能得到的期望 return。
它定义为:
其中:
- \(v_\pi(s)\) 是状态 \(s\) 在策略 \(\pi\) 下的 state value。
- \(G_t\) 是从时刻 \(t\) 开始的 return。
- 条件 \(S_t=s\) 表示当前状态固定为 \(s\)。
- 下标 \(\pi\) 表示期望是沿着策略 \(\pi\) 与环境交互产生的轨迹分布计算的。(我个人更喜欢把它看作随机变量\(G_t\)的期望)
更直接地说,state value 是“从某个状态出发,在策略 \(\pi\) 下所有可能 return 的平均值”。如果策略和环境都是确定性的,那么从 \(s\) 出发只会产生一条轨迹,此时 \(v_\pi(s)\) 就等于这条轨迹的 return。只要策略或者环境中有随机性,\(G_t\) 就是随机变量.
Q value / Action value
Action value function,也常被称为 Q value,描述的是:在策略 \(\pi\) 下,从状态 \(s\) 出发,先采取动作 \(a\),之后继续按照策略 \(\pi\) 行动,未来能得到的期望 return。
Q value 的直观理解是从状态出发,每个可能的action未来会获得的return的期望.
它定义为:
其中:
- \(q_\pi(s,a)\) 是状态-动作对 \((s,a)\) 在策略 \(\pi\) 下的 action value。
- 条件 \(S_t=s,A_t=a\) 表示当前状态和当前动作都已经固定。
- 从下一步开始,后续动作仍然由策略 \(\pi\) 产生。
State value 和 Q value 的区别在于条件不同:
前者只固定当前状态,动作仍然按照策略 \(\pi(a\mid s)\) 抽样;后者同时固定当前状态和当前动作。因此,Q value 更适合用来比较“在同一个状态下,哪个动作更好”。
关于这部分的证明,我强烈推荐使用全期望公式进行,也就是 probability 里面的 law of total expectation。一般形式可以写成:
在这里令 \(X=G_t\),\(Y=(S_t=s)\),\(Z=A_t\)。那么:
而根据 Q value 的定义:
所以:
也可以写成期望形式:
这个关系的含义是:状态价值等于在该状态下按照策略选择动作后,所有动作价值的加权平均。也就是说,\(v_\pi(s)\) 是“先固定状态,再按照策略平均动作”;\(q_\pi(s,a)\) 则是“同时固定状态和动作”。
一些其他的概念
Bellman Equation
Bellman equation 是强化学习里面最核心的公式之一。它的作用是把“一个状态的价值”写成“一步奖励”和“下一个状态价值”的关系。这个公式本质上来自 return 的递推定义:
如果说 state value 是对 return 取期望,那么 Bellman equation 就是在这个递推关系的基础上继续取期望。
Bellman 方程的展开形式
先回顾 state value 的定义:
把 return 的递推形式代入:
再把当前动作 \(A_t\)、下一状态 \(S_{t+1}\) 和奖励 \(R_{t+1}\) 全部展开,就得到 Bellman expectation equation 的展开形式:
这里每一层求和都有明确含义:
- \(\sum_a \pi(a\mid s)\):在状态 \(s\) 下,策略可能选择不同动作。
- \(\sum_{s^{\prime}}\sum_r p(s^{\prime},r\mid s,a)\):给定状态和动作后,环境可能返回不同的下一状态和奖励。
- \(r+\gamma v_\pi(s^{\prime})\):当前一步奖励,加上下一个状态的折扣价值。
如果先定义 Q value:
那么 Bellman equation 也可以写得更紧凑:
这个写法和上一节的全期望公式是一致的,只是这里进一步把 \(q_\pi(s,a)\) 里面的一步环境转移也展开了。
Bellman 方程的矩阵形式
如果状态空间是有限的,并且可以写成:
那么可以把所有状态的 value 放进一个向量:
接下来定义策略 \(\pi\) 下的平均即时奖励:
把所有 \(r_\pi(s_i)\) 放进向量:
再定义策略 \(\pi\) 诱导出来的状态转移矩阵 \(\mathbf{P}_\pi\in\mathbb{R}^{n\times n}\)。它的第 \(i,j\) 个元素是:
于是,Bellman equation 可以写成非常简洁的矩阵形式:
把含有 \(\mathbf{v}_\pi\) 的项移到左边:
如果 \(\mathbf{I}-\gamma\mathbf{P}_\pi\) 可逆,就有闭式解:
这个矩阵形式很重要,因为它说明:在给定策略 \(\pi\) 的情况下,求 state value 本质上是在解一个线性方程组。这个问题也被称为 policy evaluation。
Bellman 最优方程与最优策略
前面的 Bellman equation 都是在“给定策略 \(\pi\)”的前提下讨论的。接下来的问题是:什么样的策略是最优策略?
我们可以先定义策略之间的偏序关系。如果对任意状态 \(s\in\mathcal{S}\),都有:
那么就说策略 \(\pi_1\) 不差于策略 \(\pi_2\),记作:
如果一个策略 \(\pi^*\) 对任意其他策略 \(\pi\) 都满足:
那么 \(\pi^*\) 就是一个最优策略。对应的最优 state value 定义为:
最优策略的关键在于:如果已经知道每个动作带来的未来价值,那么在每个状态下都应该选择价值最大的动作。因此 Bellman expectation equation 中的“按照策略加权平均”,在最优情况下会变成“对动作取最大值”:
这就是 Bellman optimality equation。
Bellman optimality equation 的解的存在性和唯一性
这里有一个非常重要的问题:这个方程一定有解吗?如果有解,解是不是唯一的?
在有限状态、有限动作,并且折扣因子满足 \(0\le \gamma < 1\) 的 discounted MDP 中,Bellman optimality equation 的最优 state value \(v^*\) 一定存在,并且是唯一的。
原因可以从 Bellman optimality operator 的角度理解。定义:
如果写成矩阵形式,可以把它理解为:下一步Bellman状态更新的时候,选择让每个状态最大的动作,然后用这个策略对应的状态值作为当前能获得的最优状态值:
这里的 \(\max_\pi\) 不是对整个向量取一个标量最大值,而是对每个状态分别选择能让该状态右侧取到最大值的动作或策略。换句话说,Bellman optimality operator 做的事情就是:给定当前价值估计 \(\mathbf{v}\),在每个状态上做一次 greedy 的 Bellman backup。
那么 Bellman optimality equation 就是:
当 \(0\le \gamma < 1\) 时,\(\mathcal{T}\) 是一个 contraction mapping。因此根据 contraction mapping theorem,它有唯一的不动点。这个唯一不动点就是最优 state value \(v^*\)。
需要注意的是,唯一的是最优价值函数 \(v^* \),不一定是最优策略 \(\pi^* \)。如果在某个状态下有多个动作同时达到最大的 action value,那么这些动作都可以构成最优策略。因此最优策略可能不唯一。
对应地,最优 Q value 满足:
当 \(q^*(s,a)\) 已知时,一个确定性的 greedy policy 可以写成:
如果用随机策略的形式表达,则可以写成:
如果有多个动作同时达到最大值,那么最优策略不一定唯一;可以固定选择其中一个动作,也可以在这些最优动作之间随机选择。
更多的概念和算法
这一节主要对应课程第 4 节到第 8 节,以及第 10 节中的内容。这部分更多是在介绍传统强化学习算法的发展脉络,和大模型中的强化学习应用关系没有那么直接。
如果我们的主要目标是理解 LLM 中的 RLHF、PPO、GRPO 这一类方法,那么这部分内容并不需要逐个公式深入推导。更重要的是掌握它们试图解决什么问题、属于哪一类方法,以及它们引入了哪些后来仍然会反复出现的概念。
所以这一节会尽量采用 QA 的形式组织:每个小节主要回答“这个算法是什么”“它在解决什么问题”“它和其他算法的关系是什么”,(算法的定义和目标).证明细节和复杂推导会尽量省略。
Value iteration 和 Policy iteration
Q: Value iteration 是什么?
Value iteration 是一种求解 Bellman optimality equation 的动态规划算法。它的目标是直接逼近最优价值函数 \(v^*\),然后根据最优价值函数得到最优策略。
Bellman optimality equation 可以看成一个 fixed point equation。定义 Bellman optimality operator \(\mathcal{T}\):
那么 Bellman optimality equation 可以写成:
Value iteration 就是不断做下面这个更新:
也就是:
直观上,它每一步都在问:如果我现在对下一状态的价值估计是 \(v_k\),那么当前状态下最好的动作会带来多少价值?反复更新之后,\(v_k\) 会逐渐逼近 \(v^*\)。
Value iteration 的前提是 model 已知,也就是我们知道环境动态 \(p(s^{\prime},r\mid s,a)\)。如果不知道环境模型,就无法直接把所有可能的 \(s^{\prime}\) 和 \(r\) 都枚举出来求期望。
Q: Policy iteration 是什么?
Policy iteration 是另一种经典动态规划算法。它不是直接迭代最优价值函数,而是在“评估当前策略”和“改进当前策略”之间交替进行。
和 value iteration 一样,policy iteration 也要求 model 已知。因为 policy evaluation 需要构造 \(\mathbf{r}{\pi_k}\) 和 \(\mathbf{P}{\pi_k}\),policy improvement 也需要根据模型计算每个动作的一步期望回报。
它包含两个步骤:
- Policy evaluation:给定当前策略 \(\pi_k\),计算它对应的价值函数 \(v_{\pi_k}\)。
- Policy improvement:根据 \(v_{\pi_k}\) 构造一个更好的策略 \(\pi_{k+1}\)。
Policy evaluation 解的是普通 Bellman equation:
Policy improvement 则是在每个状态上选择 greedy action:
所以 policy iteration 的核心结构是:
它的直观含义是:先认真评估当前策略到底有多好,然后根据这个评估结果改进策略。
Q: Value iteration 和 Policy iteration 有什么区别?
二者都需要环境模型,因此都属于 model-based 的动态规划方法。区别在于它们“评估策略”的程度不同。
Policy iteration 在每次改进策略之前,会尽量把当前策略 \(\pi_k\) 的价值 \(v_{\pi_k}\) 评估清楚。它的 policy evaluation 可能需要解线性方程组,或者进行多次迭代。
Value iteration 则更急。它不会完整评估某一个策略,而是每轮只做一次 Bellman optimality update,然后马上继续改进价值估计。可以把它理解成“边评估,边改进”,而不是“评估充分之后再改进”。
从这个角度看:
- Policy iteration:每一步更重,通常迭代次数更少。
- Value iteration:每一步更轻,通常需要更多轮迭代。
Q: Truncated policy iteration 是什么?
Truncated policy iteration 介于 value iteration 和 policy iteration 之间。
Policy iteration 的 policy evaluation 如果完整做完,可能很贵;value iteration 又只做一步 evaluation。Truncated policy iteration 的想法是:在 policy evaluation 里只做有限步迭代,然后就进行 policy improvement。
所以它可以看成一个连续谱:
- Value iteration:policy evaluation 只做一步。
- Truncated policy iteration:policy evaluation 做有限步。
- Policy iteration:policy evaluation 做到充分收敛。
这个视角很重要,因为它说明很多 RL 算法并不是完全割裂的,而是在“评估多少”和“改进多快”之间做不同折中。
Monte Carlo Learning
Q: Monte Carlo 方法在 RL 里面做什么?
Monte Carlo 方法的核心思想是用采样平均来估计期望。RL 里面的 state value 和 action value 本来就是期望:
如果环境模型未知,我们无法通过 \(p(s^{\prime},r\mid s,a)\) 直接计算这个期望。但我们可以让智能体真实地跑很多条轨迹,得到很多 return 样本,然后用平均 return 估计 value。
所以 Monte Carlo learning 是一种 model-free 方法:它不需要知道环境的转移概率,只需要能和环境交互并采样轨迹。
Q: MC Basic 是什么?
MC Basic 可以看作 policy iteration 的 model-free 版本。
在 model-based policy iteration 中,policy evaluation 通过 Bellman equation 计算 \(q_{\pi_k}(s,a)\)。但在 model-free 场景下,我们不知道环境模型,所以改用采样估计:
其中 \(g^{(i)}(s,a)\) 表示从 \((s,a)\) 出发、之后按照 \(\pi_k\) 行动得到的一次 return 样本。
估计出 \(q_{\pi_k}(s,a)\) 之后,再做 greedy policy improvement:
它的核心问题是效率比较低,因为为了估计每个 \((s,a)\),可能需要从大量 state-action pair 分别出发采样。
完整的 Monte Carlo control 循环大致是:
- 初始化 \(q(s,a)\),并初始化一个策略 \(\pi\)。
- 按照当前策略 \(\pi\) 采样一条完整 episode。
- 从 episode 末尾往前计算每个时间步对应的 return。
- 对 episode 中访问到的 state-action pair \((s_t,a_t)\),用对应的 return 更新 \(q(s_t,a_t)\)。常见做法是对多次访问得到的 return 取平均。
- 根据新的 \(q\) 改进策略,例如令 \(\pi\) 变成 greedy policy 或 ε-greedy policy。
- 重复采样新的 episode,并持续更新 \(q\) 和 \(\pi\)。
所以 MC control 的循环是“采样完整轨迹 -> 用完整 return 更新 action value -> 根据 action value 改进策略”。它和 TD 最大的差别是:MC 必须等 return 完整出现,而 TD 可以在每一步之后立刻更新。
Q: Exploring Starts 是什么?
Exploring Starts 是 Monte Carlo 方法中的一个理论条件。它要求每个 state-action pair \((s,a)\) 都有机会作为 episode 的起点。
为什么需要这个条件?因为如果某个动作从来没有被采样过,我们就无法估计它的 \(q_\pi(s,a)\)。而一个从未被尝试的动作,理论上可能恰好是最优动作。
所以 exploring starts 的作用是保证探索充分。但在真实任务里,它经常不现实。很多环境并不允许我们任意指定初始状态和初始动作。
Q: ε-greedy MC 是什么?
ε-greedy MC 的目标是去掉 exploring starts 这个很强的假设。它通过使用 soft policy 来保证每个动作都有非零概率被选中。
ε-greedy policy 的典型形式是:
其中 \(a^*(s)\) 是当前估计下的 greedy action。
ε-greedy 的意义是平衡 exploration 和 exploitation:
- exploitation:大概率选择当前看起来最好的动作。
- exploration:小概率尝试其他动作,避免过早错过潜在好动作。
Temporal-Difference Learning
Q: TD learning 是什么?
Temporal-Difference learning,简称 TD learning,是强化学习里非常核心的一类 model-free 算法。它的目标是在不需要环境模型的情况下,从经验样本中估计 value。
最基础的 TD state value update 是:
其中:
- \(r_{t+1}+\gamma v_t(s_{t+1})\) 称为 TD target。
- \(r_{t+1}+\gamma v_t(s_{t+1})-v_t(s_t)\) 称为 TD error。
TD 的关键特征是 bootstrapping:它用当前估计出来的 \(v_t(s_{t+1})\) 作为目标的一部分。因此 TD 并不需要等一整条 episode 结束才能更新。
从形式上看,TD learning 使用的正是后文 Robbins-Monro / Stochastic Approximation 的思想:用一个带噪声的采样目标不断修正当前估计。更具体地说,TD target \(r_{t+1}+\gamma v_t(s_{t+1})\) 可以看作 Bellman expectation target 的一次采样近似。关于这个 general 视角,可以参考后文 Robbins-Monro / Stochastic Approximation 是什么?。
Q: TD 和 MC 的区别是什么?
MC 和 TD 都是 model-free 方法,但它们使用经验数据的方式不同。
MC 使用完整 return:
TD 使用一步 TD target:
所以 MC 的特点是:
- 必须等 episode 结束之后才能计算 return。
- 不 bootstrapping。
- 方差通常更大,但 bias 相对更小。
TD 的特点是:
- 每走一步就可以更新。
- bootstrapping。
- 可以处理 continuing task。
- 方差通常更小,但会引入来自当前估计的 bias。
Q: On-policy 和 Off-policy 是什么?
在 TD control 算法里,理解 Sarsa 和 Q-learning 的关键是区分 behavior policy 和 target policy。
- Behavior policy:实际和环境交互、产生样本的策略。
- Target policy:算法真正想评估或优化的策略。
如果 behavior policy 和 target policy 是同一个策略,那么算法是 on-policy:
如果 behavior policy 和 target policy 可以不同,那么算法是 off-policy:
这里的 \(\beta\) 表示 behavior policy,\(\pi\) 表示 target policy。
这个定义放在 Sarsa 和 Q-learning 前面非常重要,因为二者的核心差别不只是 TD target 长得不一样,而是它们学习的目标策略不同。
Q: Sarsa 是什么?
Sarsa 是 TD learning 在 action value 上的版本。它估计的是当前策略 \(\pi\) 下的 \(q_\pi(s,a)\)。
它的名字来自一次更新需要用到的五元组:
Sarsa 的更新形式是:
因为 \(a_{t+1}\) 是按照当前策略 \(\pi\) 采样出来的,所以 Sarsa 是 on-policy 算法。
完整的 Sarsa control 循环大致是:
- 初始化 \(q(s,a)\),并根据 \(q\) 构造一个策略 \(\pi\),例如 ε-greedy policy。
- 在当前状态 \(s_t\) 下,按照当前策略 \(\pi\) 采样动作 \(a_t\)。
- 执行动作 \(a_t\),环境返回奖励 \(r_{t+1}\) 和下一个状态 \(s_{t+1}\)。
- 在新状态 \(s_{t+1}\) 下,继续按照同一个当前策略 \(\pi\) 采样动作 \(a_{t+1}\)。
- 用五元组 \((s_t,a_t,r_{t+1},s_{t+1},a_{t+1})\) 更新 \(q(s_t,a_t)\)。
- 根据新的 \(q\) 改进策略,例如重新令 \(\pi\) 成为关于 \(q\) 的 ε-greedy policy。
- 令 \(s_t\leftarrow s_{t+1}\),\(a_t\leftarrow a_{t+1}\),继续下一步交互。
这里最关键的点是:Sarsa 用当前策略采样 \(a_{t+1}\),也用这个 \(a_{t+1}\) 构造 TD target。因此它学习的是当前策略自己的 action value,并在这个基础上逐步改进当前策略。
从 on/off-policy 的角度看,Sarsa 的 behavior policy 和 target policy 是同一个策略。它怎么采样,就怎么学习;它学习的正是当前正在执行的策略。因此 Sarsa 是 on-policy。
Q: n-step Sarsa 是什么?
n-step Sarsa 介于 one-step Sarsa 和 Monte Carlo 之间。它不用只看一步 TD target,也不一定等到完整 episode 结束,而是看未来 \(n\) 步的奖励,再接上第 \(n\) 步后的 value 估计。
它的 target 可以写成:
当 \(n=1\) 时,它就是普通 Sarsa;当 \(n\) 趋近于 episode 长度时,它就接近 Monte Carlo。
所以 n-step 方法可以看成在 bias 和 variance 之间调节:
- \(n\) 小:更像 TD,更新快,方差小,但 bootstrapping bias 更强。
- \(n\) 大:更像 MC,bias 小,但方差更大。
Q: Q-learning 是什么?
Q-learning 是一种直接估计最优 action value \(q^*(s,a)\) 的 TD 算法。它的更新是:
和 Sarsa 的区别在于 target:
- Sarsa 使用实际采样到的 \(a_{t+1}\)。
- Q-learning 使用下一状态下的最大 action value。
因此 Q-learning 的目标策略是 greedy policy,但行为策略可以是别的探索策略。所以 Q-learning 是 off-policy 算法。
完整的 Q-learning control 循环大致是:
- 初始化 \(q(s,a)\),并设置一个 behavior policy \(\beta\),例如 ε-greedy policy。
- 在当前状态 \(s_t\) 下,按照 \(\beta\) 采样动作 \(a_t\)。
- 执行动作 \(a_t\),环境返回奖励 \(r_{t+1}\) 和下一个状态 \(s_{t+1}\)。
- 用 \(r_{t+1}+\gamma\max_a q(s_{t+1},a)\) 更新 \(q(s_t,a_t)\)。
- 根据新的 \(q\) 更新 target policy,例如令 target policy 在每个状态下选择 \(\arg\max_a q(s,a)\)。
- Behavior policy 可以继续保持 ε-greedy,以便继续探索。
- 令 \(s_t\leftarrow s_{t+1}\),继续采样下一步。
这里最关键的点是:采样动作 \(a_t\) 可以来自带探索的 behavior policy,但更新目标里面使用的是 \(\max_a q(s_{t+1},a)\),也就是 greedy target policy。因此 Q-learning 可以一边探索,一边学习 greedy 最优策略。
从 on/off-policy 的角度看,Q-learning 的 behavior policy 可以是 ε-greedy 这类探索策略,但 target policy 是 greedy policy。采样策略和学习目标不必相同,因此 Q-learning 是 off-policy。
Q: TD 算法属于 general algorithm 还是 RL 算法?
TD learning 本身是 RL 算法。它的对象是 value function,它的样本来自 agent 和 environment 的交互,它要解决的是 Bellman equation 或 Bellman optimality equation。
但是,TD learning 可以从 stochastic approximation 的角度理解。也就是说,它在数学形式上像 Robbins-Monro 这一类随机近似算法:
所以更准确地说:TD 是 RL 算法,但它的理论解释可以借助 general stochastic approximation。
Value Function Methods
Q: 为什么需要 value function approximation?
前面讨论的很多算法默认 value function 可以用表格存储。例如每个状态 \(s\) 都有一个 \(v(s)\),每个 state-action pair \((s,a)\) 都有一个 \(q(s,a)\)。
这在小规模离散环境中是可行的,但如果状态空间很大,甚至是连续的,表格方法就会遇到两个问题:
- 存储困难:状态太多,无法给每个状态单独存一个值。
- 泛化能力弱:表格只记住见过的状态,不能自然泛化到相似但没见过的状态。
Value function approximation 的想法是用一个参数化函数近似 value:
或者:
其中 \(w\) 是参数,可以是线性模型的权重,也可以是神经网络参数。
Q: 从 tabular value 到 function approximation 发生了什么变化?
在 tabular 方法中,更新一个状态的 value 只会改变表格中的一个 entry。
而在 function approximation 中,更新的是参数 \(w\)。因为多个状态共享同一组参数,所以一次更新可能同时影响很多状态的 value 估计。
这带来了两个结果:
- 好处:模型可以把一个状态上学到的信息泛化到相似状态。
- 风险:更新一个状态时,也可能破坏其他状态上的估计。
这也是为什么 function approximation 之后,优化稳定性会变得更重要。
Q: Sarsa with function approximation 是什么?
Sarsa with function approximation 是把 Sarsa 中的表格 \(q(s,a)\) 换成参数化函数 \(\hat{q}(s,a,w)\)。
这里先解释一下 TD target 是什么。我们希望 \(\hat{q}(s_t,a_t,w)\) 能逼近真实的 \(q_\pi(s_t,a_t)\)。而根据 Bellman expectation equation,真实的 \(q_\pi(s_t,a_t)\) 应该满足:
但是在 model-free 场景下,我们无法直接计算这个期望,只能拿到一次真实采样:
于是就用这一次采样得到的“一步奖励 + 下一步估计价值”作为当前 \(q(s_t,a_t)\) 应该靠近的目标。这个目标就叫 TD target。
就是用一步采样的样本近似上面的期望, \(q(s_t,a_t) \approx r_{t+1}+\gamma \hat{q}(s_{t+1},a_{t+1}) \)
回到普通 Sarsa。对于一次经验样本:
TD target 写作:
这里的 \(y_t\) 不是一个新的真实标签,而是由当前样本和当前 value estimate 构造出来的训练目标。它之所以是“TD”的,是因为它只向前看一步,然后用 \(\hat{q}(s_{t+1},a_{t+1},w_t)\) 进行 bootstrapping。
在 tabular Sarsa 中,我们可以直接更新表格里的 \(q(s_t,a_t)\)。但是在 function approximation 中,\(q(s_t,a_t)\) 是函数输出:
所以我们不能直接“改一个表格 entry”,而是要调整参数 \(w\),让函数输出更接近 TD target。
因此定义 TD error:
也就是:
既然我们希望 TD error 越小越好,一个自然做法是构造平方损失:
构造这个 loss 之后,就可以使用梯度下降来更新参数:
所以 Sarsa with function approximation 的训练过程可以理解为:不断采样 \((s_t,a_t,r_{t+1},s_{t+1},a_{t+1})\),用 Sarsa 的 TD target 构造监督信号,再用梯度下降训练 \(\hat{q}(s,a,w)\)。
它仍然是 on-policy,因为下一步动作 \(a_{t+1}\) 来自当前策略。Function approximation 只是把表格 \(q(s,a)\) 换成 \(\hat{q}(s,a,w)\),不改变 on/off-policy 的分类。
完整流程大致是:
- 初始化参数 \(w\),并根据 \(\hat{q}(s,a,w)\) 构造一个策略 \(\pi\),例如 ε-greedy policy。
- 在当前状态 \(s_t\) 下,按照 \(\pi\) 采样动作 \(a_t\)。
- 执行动作 \(a_t\),环境返回 \(r_{t+1}\) 和 \(s_{t+1}\)。
- 在 \(s_{t+1}\) 下继续按照 \(\pi\) 采样 \(a_{t+1}\)。
- 构造 TD target:
- 用 TD error 对平方损失做梯度下降,更新参数 \(w\)。
- 根据新的 \(\hat{q}\) 更新策略,例如重新构造 ε-greedy policy。
- 令 \(s_t\leftarrow s_{t+1}\),\(a_t\leftarrow a_{t+1}\),继续下一步。
这里和表格 Sarsa 的循环完全一致,区别只是更新对象从表格 entry 变成了函数参数 \(w\)。
Q: Q-learning with function approximation 是什么?
Q-learning with function approximation 是把 Q-learning 中的表格 \(q(s,a)\) 换成参数化函数 \(\hat{q}(s,a,w)\)。
和 tabular Q-learning 一样,它想逼近的是最优 action value \(q^*(s,a)\)。这个最优值满足 action-value 形式的 Bellman optimality equation:
但在 model-free 场景下,我们不能直接计算这个期望,只能用一次采样 \((s_t,a_t,r_{t+1},s_{t+1})\) 来构造一步 bootstrap 的样本目标。再把未知的 \(q^*\) 用当前估计 \(\hat{q}(\cdot,\cdot,w_t)\) 替换,就得到 Q-learning with function approximation 的 TD target:
这个方法是 DQN 的前身。它仍然是 off-policy,因为它可以用探索策略采样数据,但 TD target 使用的是 greedy target。它的核心风险是:Q-learning 本来就是 off-policy,再叠加 function approximation 和 bootstrapping,训练可能变得不稳定。
完整流程大致是:
- 初始化参数 \(w\),并设置一个 behavior policy \(\beta\),例如 ε-greedy policy。
- 在当前状态 \(s_t\) 下,按照 \(\beta\) 采样动作 \(a_t\)。
- 执行动作 \(a_t\),环境返回 \(r_{t+1}\) 和 \(s_{t+1}\)。
- 用一步 bootstrap 样本近似 Bellman optimality equation 中的期望,构造 greedy TD target:
- 用 TD error 更新参数 \(w\)。如果用平方误差作为损失,可以写成:
- 根据新的 \(\hat{q}\) 更新 target policy,例如令 target policy 在每个状态下选择 \(\arg\max_a \hat{q}(s,a,w)\)。
- Behavior policy 可以继续保持 ε-greedy,以便继续探索。
- 令 \(s_t\leftarrow s_{t+1}\),继续下一步采样。
这里和表格 Q-learning 的循环也一致,区别同样只是更新对象从表格 entry 变成了函数参数 \(w\)。
Q: Deep Q-learning / DQN 是什么?
DQN 可以理解为用深度神经网络表示 Q function 的 Q-learning。它仍然是在学习最优 action value \(q^*(s,a)\),只是把表格 \(q(s,a)\) 换成了神经网络:
其中 \(w\) 是主网络,也就是 online network 的参数。给定状态 \(s\),网络可以输出每个动作的 Q value;策略通常取 greedy 或 ε-greedy:
DQN 的更新仍然来自 Bellman optimality equation。最优 action value 满足:
这个式子说明:\(q^*(s_t,a_t)\) 是“一步奖励 + 下一状态最优 Q value”的条件期望。DQN 在 model-free 场景下无法直接计算这个期望,所以用一次经验样本:
来构造一步 bootstrap 的样本目标。DQN 通常用 target network \(\hat{q}(\cdot,\cdot,w^{-})\) 估计下一状态的 Q value,因此 TD target 写作:
主网络当前对 \((s_t,a_t)\) 的预测是 \(\hat{q}(s_t,a_t,w)\)。因此 TD error 定义为:
展开就是:
这里 \(w^{-}\) 表示 target network 的参数。因为我们希望 TD error 越小越好,所以构造平方损失:
然后用梯度下降或者深度学习优化器更新主网络参数:
所以 DQN 的训练过程可以理解为:不断采样经验 \((s_t,a_t,r_{t+1},s_{t+1})\),用 Q-learning 的 TD target 构造监督信号,再用梯度下降训练主网络,让 \(\hat{q}(s,a,w)\) 逐渐接近最优 Q function。
DQN 中两个非常重要的工程技巧是:
- Experience replay:把历史经验存到 replay buffer 中,训练时随机采样 mini-batch。
- Target network:用一个更新较慢的网络计算 TD target,减少训练目标剧烈变化。
Q: DQN 为什么需要两个网络?
从概念上说,完全可以把 DQN 看成普通的 Q-learning with function approximation:只用一个神经网络 \(\hat{q}(s,a,w)\) 表示 Q value,然后也用这个网络构造 TD target:
问题在于,这样 target 和 prediction 都依赖同一组参数 \(w\)。一边用梯度下降更新 \(w\),一边又用同一个 \(w\) 生成学习目标,等于让网络追逐一个不断移动的目标。在深度神经网络中,这种 bootstrapping + function approximation + off-policy 的组合很容易导致训练振荡甚至发散。
因此 DQN 引入 target network:
它和主网络结构相同,也表示 Q value,但参数 \(w^{-}\) 暂时固定,只用来计算 TD target:
主网络 \(\hat{q}(s,a,w)\) 负责被梯度下降更新,target network \(\hat{q}(s,a,w^{-})\) 负责提供相对稳定的学习目标。每隔一段时间,再把主网络参数复制给 target network:
所以这两个网络不是在学习两个不同的价值函数。它们本质上都是对 \(q^*(s,a)\) 的近似;区别只是主网络是正在学习的估计,target network 是延迟更新的估计。
Policy Gradient 和 Actor-Critic Methods
Q: 为什么 Actor-Critic 需要先理解 policy gradient?
Value-based 方法的基本思路是先学价值函数,然后从价值函数导出策略。Policy gradient 方法则直接把策略写成参数化函数:
然后定义一个标量目标 \(J(\theta)\),用梯度上升优化策略参数:
Actor-Critic 本质上仍然是 policy gradient 方法,只是它用一个 critic 来估计 value,从而帮助 actor 更新策略。
Q: Actor-Critic 是什么?
Actor-Critic 是一种把 policy-based 和 value-based 结合起来的框架。
- Actor:负责表示和更新策略 \(\pi(a\mid s,\theta)\)。
- Critic:负责估计 value,例如 \(v(s,w)\) 或 \(q(s,a,w)\),用来评价 actor 当前动作的好坏。
最简单地说,actor 决定怎么行动,critic 负责给 actor 的行动打分。
Q: Q Actor-Critic 是什么?
Q Actor-Critic,简称 QAC,是最直接的 Actor-Critic 形式。Actor 用 policy gradient 更新策略,Critic 估计 action value \(q(s,a,w)\)。
策略更新大致形如:
Critic 则可以用类似 Sarsa + function approximation 的方式更新 \(q(s,a,w)\)。
Q: A2C / Advantage Actor-Critic 是什么?
A2C 的核心是把 Q value 换成 advantage:
Advantage 表示:在状态 \(s\) 下,动作 \(a\) 比当前策略的平均水平好多少。
实际算法中,advantage 常常用 TD error 近似:
于是 actor 更新变成:
A2C 的好处是使用 baseline \(v_\pi(s)\) 降低策略梯度估计的方差。
Q: Off-policy Actor-Critic 是什么?
普通 policy gradient 通常是 on-policy 的,因为梯度期望里的动作需要来自当前策略 \(\pi(a\mid s,\theta)\)。
Off-policy Actor-Critic 允许 behavior policy \(\beta\) 和 target policy \(\pi\) 不同。为了修正采样分布不一致,常用 importance sampling weight:
直观上,如果某个动作在目标策略下更可能出现,但在行为策略下较少出现,就提高它的权重;反之则降低权重。
Q: Deterministic Policy Gradient / DPG 是什么?
前面的 policy gradient 通常使用随机策略 \(\pi(a\mid s,\theta)\)。DPG 则使用确定性策略:
它适合连续动作空间,因为连续动作下对所有动作求概率分布再采样可能比较麻烦。DPG 的 actor 直接输出动作,critic 估计 \(q(s,a,w)\),然后 actor 根据 \(q\) 对动作的梯度来更新策略。
DDPG 可以看成 DPG 的深度学习版本:actor 和 critic 都用神经网络表示,并且通常配合 replay buffer 和 target network。
一些 General 算法和思想
Q: Monte Carlo estimation 是什么?
Monte Carlo estimation 是用采样平均估计期望:
它本身不是 RL 专属算法,但 RL 中很多对象都是期望,比如 value、return、policy gradient,所以 Monte Carlo 思想会反复出现。
Q: Robbins-Monro / Stochastic Approximation 是什么?
Robbins-Monro 算法属于 stochastic approximation。它解决的是这样一类问题:我们想求一个方程的根,
其中 \(w\in\mathbb{R}^d\) 是我们要寻找的未知参数,\(g(w)\) 是一个确定性的函数。所谓确定性,是指只要 \(w\) 给定,\(g(w)\) 的值就是固定的。
困难在于:很多时候我们不能直接计算 \(g(w_t)\)(Model Free)。在第 \(t\) 步,算法已经有了当前参数 \(w_t\),但是只能通过一次随机采样得到一个 noisy observation:
这里最容易混淆的是 \(\xi_t\) 到底是什么。\(\xi_t\) 不是参数 \(w_t\),也不是 \(g(w_t)\) 本身。它表示第 \(t\) 次随机采样得到的信息,比如一个数据点、一个 mini-batch、一次随机实验结果,或者 RL 中一次环境交互得到的 transition。
也就是说:
- \(w_t\):当前算法手里的参数,通常可以看成已经确定的量。
- \(g(w_t)\):在 \(w_t\) 处真正想知道的确定性函数值,但通常算不到。
- \(\xi_t\):第 \(t\) 次采样带来的随机信息。
- \(\tilde{g}(w_t,\xi_t)\):用这次随机信息构造出来的 \(g(w_t)\) 的 noisy observation。
Robbins-Monro 的关键假设是:这个 noisy observation 在条件期望意义下等于真正的 \(g(w_t)\):
所以,随机的来源不是“\(g\) 这个函数随机”,而是我们每次只能通过随机样本 \(\xi_t\) 去估计 \(g(w_t)\)。在 \(w_t\) 固定时,\(\tilde{g}(w_t,\xi_t)\) 会随着样本 \(\xi_t\) 改变而改变;但它平均起来应该等于 \(g(w_t)\)。
Robbins-Monro 的更新形式是:
其中 \(\alpha_t>0\) 是 step size。这个迭代形式其实并没有它表面上看起来的那么trival,我们下文只列出它的收敛性条件,它的证明请参考原始课件的第六课.
一个直觉的理解方式:如果我们能直接计算 \(g(w_t)\),做如下迭代,如果 \(g(w_t)=0\),就已经找到了根.
但现在 \(g(w_t)\) 算不到,于是用 \(\tilde{g}(w_t,\xi_t)\) 代替它。也就是说,stochastic approximation 是在用“带噪声的观测”逼近一个确定性的求根过程。
Robbins-Monro 的收敛条件
更严格地说,Robbins-Monro 算法的收敛性通常需要三类条件。为了和课程里的表述一致,先把 noisy observation 写成真实函数值加观测误差:
其中 \(\eta_t\) 是第 \(t\) 次采样带来的 observation error。设 \(\mathcal{H}_t\) 表示第 \(t\) 步之前已经产生的历史信息,例如:
课程里给出的 Robbins-Monro 收敛条件可以概括为:
条件 1:\(g\) 的方向要稳定,并且根要是唯一的。
在一维情形下,一个常见条件是存在常数 \(c_1,c_2>0\),使得:
它表示 \(g(w)\) 单调递增,并且斜率既不会太小也不会太大。单调性保证 \(g(w)=0\) 的根不会有多个;正的下界保证算法在根附近仍然有明确的修正方向;上界则避免函数变化过于剧烈。
条件 2:step size 要逐渐变小,但不能变得太快。
这里 \(\sum_t\alpha_t=\infty\) 表示总步长不能太小,否则算法可能还没有走到根附近就停住了;\(\sum_t\alpha_t^2<\infty\) 表示步长要足够快地变小,使得随机噪声的累计影响可以被控制住。一个典型选择是 \(\alpha_t=1/t\)。
条件 3:观测误差不能有系统性偏差,并且方差要有限。
课程中写作:
第一个式子表示 noisy observation 平均起来不能总是偏向某个错误方向;第二个式子表示噪声不能无限大。一个常见的特殊情况是 \(\eta_t\) 是 iid 的零均值、有限方差随机序列。它不要求噪声必须服从 Gaussian distribution。
在这些条件下,Robbins-Monro 迭代会以概率 1 收敛到 \(g(w)=0\) 的根 \(w^*\)。这里的“以概率 1 收敛”表示:虽然每一次轨迹都会受到随机样本影响,但除了概率为 0 的异常情况,迭代最终都会收敛到正确的根。
应用: 求期望的值
先看一个具体例子:用 stochastic approximation 求期望。假设我们想求随机变量 \(X\) 的均值:
如果令未知参数 \(w\) 表示对 \(\mu\) 的估计,那么这个问题可以写成求根问题:
如果每次只能拿到一个样本 \(X_t\),那么这里的随机变量 \(\xi_t\) 就可以具体理解为:
在当前参数 \(w_t\) 下,\(g(w_t)=w_t-\mathbb{E}[X]\) 算不到,因为 \(\mathbb{E}[X]\) 算不到。但可以用样本 \(X_t\) 构造 noisy observation:
它确实是 \(g(w_t)\) 的无偏观测,因为:
代入 Robbins-Monro 更新:
也就是:
这个例子说明:求期望 \(\mathbb{E}[X]\) 可以转化成求 \(g(w)=0\) 的根;每次样本 \(X_t\) 就是随机观测 \(\xi_t\),它帮助我们构造 \(\tilde{g}(w_t,\xi_t)\)。
应用2: TD learning 是 stochastic approximation 的一个实例
TD learning 和这个思想非常接近。先固定一个策略 \(\pi\),再固定一个状态 \(s\)。按照 state value 的定义,\(v_\pi(s)\) 满足:
这个式子本质上仍然是在求一个期望。把等式右边移到左边,就得到一个求根问题:
为了和 Robbins-Monro 的记号一致,把当前 value estimate 记为 \(w\)。如果先不引入 function approximation,可以把 \(w\) 理解为一张 value table,其中 \(w(s)\) 是状态 \(s\) 的 value estimate。于是对每个状态 \(s\),可以定义:
我们想求的是:
如果能精确计算这个期望,就可以直接得到 \(g_s(w_t)\)。但在 model-free RL 中,这个期望通常算不到。一次环境交互只给出一个 transition:
所以在 TD learning 里,\(\xi_t\) 就是这一次环境交互得到的随机 transition。当访问到状态 \(s_t\) 时,右侧期望
无法直接计算,但可以用这一次 transition 给出的样本来近似:
因此,\(g_{s_t}(w_t)\) 的 noisy observation 可以写成:
这和前面的求均值例子完全同构:真实的期望算不到,于是用一次样本构造 \(\tilde{g}\)。把它代入 Robbins-Monro 更新,就得到 TD(0) 的形式:
也就是:
这里方括号里的量就是 TD error。为了和前面 TD learning 的记号对应,也可以把 \(w_t(s)\) 重新记为 \(v_t(s)\),于是得到熟悉的写法:
所以,从 stochastic approximation 的角度看,TD learning 做的事情就是:把每个状态上的 value equation 写成 \(g_s(w)=0\),再用一次次随机 transition \(\xi_t=(s_t,r_{t+1},s_{t+1})\) 构造 \(\tilde{g}(w_t,\xi_t)\),用 noisy observation 逼近这些方程的根。
Q: SGD、BGD、MBGD 分别是什么?
它们都是优化算法,用来最小化目标函数。
- BGD,Batch Gradient Descent:每次用全部数据估计梯度。
- SGD,Stochastic Gradient Descent:每次用一个样本估计梯度。
- MBGD,Mini-batch Gradient Descent:每次用一小批样本估计梯度。
在深度学习里最常见的是 mini-batch SGD 及其变体。RL 中一旦引入 function approximation,尤其是神经网络,就会自然用到这些优化算法。
Q: Importance sampling 是什么?
Importance sampling 是一种用一个分布下的样本估计另一个分布下期望的方法。
如果样本来自 \(p_1(x)\),但我们想估计 \(p_0(x)\) 下的期望,可以写成:
这里的 \(\frac{p_0(x)}{p_1(x)}\) 就是 importance weight。
在 RL 中,它常用于 off-policy 学习:数据来自 behavior policy,但我们希望估计 target policy 的目标。
强化学习中的概念总结
Model-based 和 Model-free
Model-based 指算法需要或者显式学习环境模型,例如 \(p(s^{\prime},r\mid s,a)\)。Value iteration 和 policy iteration 是典型 model-based 方法。
Model-free 指算法不需要显式知道环境模型,而是直接从经验样本中学习 value 或 policy。MC、TD、Sarsa、Q-learning、policy gradient、actor-critic 都属于 model-free 方法。
On-policy 和 Off-policy
这个概念前面已经在 TD learning 中结合 Sarsa 和 Q-learning 解释过,可以参考 On-policy 和 Off-policy 是什么?。这里再做一次统一总结。
On-policy 指 behavior policy 和 target policy 是同一个策略。也就是说,用当前正在学习的策略去采样数据,并更新这个策略自身。MC control、Sarsa、A2C 通常是 on-policy。
Off-policy 指 behavior policy 和 target policy 可以不同。Q-learning 是经典 off-policy 算法,因为它可以用探索策略采样数据,但学习的是 greedy target policy。Off-policy actor-critic 也是 off-policy。
这个分类和是否使用 function approximation 没有直接关系。Sarsa with function approximation 仍然是 on-policy,因为它用当前策略采样到的下一动作构造 target;Q-learning with function approximation 仍然是 off-policy,因为它可以用探索策略采样数据,却用 greedy target 构造更新目标。
Online 和 Offline
Online learning 指智能体可以边和环境交互边更新,比如 TD、Sarsa、Q-learning。
Offline learning 指需要先收集数据,再用固定数据集学习,或者至少需要等一整条 episode 完成之后再更新。Monte Carlo 方法通常更接近 offline,因为它需要完整 return。
这里要注意:现代语境里的 offline RL 往往特指“只用已有数据集训练,不再和环境交互”。这和课程中 MC 必须等 episode 结束的 offline 说法不是完全同一个层次,但核心区别都是“是否边采样边更新”。
Online / Offline 和 On-policy / Off-policy 的关系
Online / offline 和 on-policy / off-policy 是两组不同的分类,它们回答的问题不同。
Online / offline 关心的是数据如何产生:训练过程中是否还能继续和环境交互、继续采样新数据。On-policy / off-policy 关心的是数据由谁产生:产生数据的 behavior policy 和正在学习的 target policy 是否相同。
因此,off-policy 不等于 offline。Q-learning 和 DQN 通常是 off-policy,但它们可以是 online 的:智能体一边用 ε-greedy behavior policy 和环境交互,一边学习 greedy target policy。
反过来,offline RL 通常需要 off-policy 思想。原因是:如果数据集已经提前固定,训练时的当前策略 \(\pi\) 已经不能再决定数据分布。数据来自某个历史 behavior policy \(\beta\),而我们训练时往往希望得到一个新的、更好的 target policy \(\pi\)。这时 \(\beta\) 和 \(\pi\) 通常不同,所以问题天然带有 off-policy 性质。
所以,对“是不是只有 off-policy 的策略才能提前采集一大批数据,然后再训练”这个问题,可以这样理解:如果只是做 policy evaluation,并且固定数据刚好来自你要评估的同一个策略,那么可以把它看成 on-policy evaluation。但如果你希望用提前采好的数据不断改进策略,得到一个不同于数据采集策略的新策略,那么通常就需要 off-policy learning 的思想。
简单说:
| 数据设置 | 策略关系 | 典型例子 |
|---|---|---|
| Online + On-policy | 边采样边更新,数据来自当前策略 | Sarsa、A2C、PPO 类方法 |
| Online + Off-policy | 边采样边更新,但 behavior policy 和 target policy 不同 | Q-learning、DQN |
| Offline + Off-policy | 数据集固定,训练目标策略通常不同于数据来源策略 | Offline Q-learning、CQL、IQL |
| Offline + On-policy | 数据固定且来自同一个目标策略,通常更像 policy evaluation | 用固定轨迹评估某个策略,用来学习的话很别扭,一般没有这种算法. |
Behavior policy 和 Target policy
Behavior policy 是用来产生数据的策略。Target policy 是算法真正想学习或评估的策略。
在 on-policy 方法中,二者相同。在 off-policy 方法中,二者不同。例如 Q-learning 中,behavior policy 可以是 ε-greedy 的探索策略,而 target policy 是 greedy policy。
Exploration 和 Exploitation
Exploration 是探索还不确定的动作,以免错过潜在更优选择。Exploitation 是利用当前已经知道的高价值动作。
ε-greedy 是最简单的探索机制:大部分时候选择当前最优动作,小概率随机尝试其他动作。
Policy gradient 和 actor-critic 中的随机策略也天然带有探索能力,因为 \(\pi(a\mid s,\theta)\) 本身是一个动作分布。
从“期望”和“样本”理解 RL 算法
RL 算法很多时候看起来很杂,但很多算法都可以用同一个视角来理解:
- 先问:这个算法真正想估计的期望是什么?
- 再问:为了估计这个期望,它实际需要什么样的样本?
第一个问题的时候,尤其想一下这个期望到底是哪几个随机变量的联合期望? 要估计它,样本就要来它的联合分布. 类似的思想还有优化目标,先写优化目标的期望形式,再用样本来近似估计这个期望.
很多 RL 对象本质上都是期望。例如 value 是 return 的期望,Q value 是在给定 state-action 后 return 的期望,policy gradient 是某个随机梯度估计的期望。算法的差别,往往不在于“是不是在求期望”,而在于它选择了什么样的期望形式,以及用什么样的样本去近似这个期望。
一个统一模板是:
实际训练时,我们通常拿不到这个期望,只能采样一个或一批样本,构造 sampled target,然后让当前 estimate 靠近这个 sampled target。
这个视角很有用,因为很多概念都可以放回这个框架里理解:
- On-policy / off-policy:样本来自哪个策略?
- Online / offline:样本是在训练中继续采,还是训练前已经固定?
- Monte Carlo / TD / n-step / GAE:用多长的轨迹样本估计目标?
- Bootstrapping:样本目标里是否用当前 value 或 Q estimate 补未来?
下面用几个典型算法对齐一下。这里用 HTML table,是为了避免 Markdown 表格中的 LaTeX 公式渲染不稳定。
| 算法 | 想估计的期望 | 实际需要的样本 | 样本目标或估计量 |
|---|---|---|---|
| Monte Carlo value | 从 开始的一整条 episode | 完整 return | |
| TD(0) | 一步 transition | ||
| Sarsa | |||
| Q-learning | |||
| DQN | Q-learning 的 Bellman optimality target | replay buffer 中的 transition mini-batch | |
| Policy gradient | on-policy trajectory | likelihood-ratio gradient sample | |
| Actor-Critic | policy gradient 中的 return / advantage 期望 | transition 或短 rollout | TD error / advantage estimate |
| GAE | advantage 的加权多步估计 | 一段 rollout | 多个 TD error 的折扣加权和 |
这个表格也解释了为什么 RL 算法的采样方式会不同。Monte Carlo 需要完整 episode,因为它直接用完整 return 估计期望;TD(0) 只需要一步 transition,因为它把期望写成一步 reward 加下一状态 value;Sarsa 需要额外采样 \(a_{t+1}\),因为它的 target 里有下一步动作;Q-learning 不需要采样 target action,因为它直接对下一状态的 action value 取最大值。
所以,理解一个 RL 算法时,一个很好的检查顺序是:
- 它要估计哪个期望?
- 这个期望条件在什么变量上?
- 为了构造这个期望的样本估计,需要采样哪些随机变量?
- 这个 sampled target 有没有 bootstrapping?
RL 中的样本构造
RL 里很多术语都和“样本长什么样”有关。最核心的对象是 trajectory,其他很多词都可以看成 trajectory 的不同切片、不同用途,或者生成 trajectory 的过程。
Trajectory 指一整条交互序列。常见写法是:
这里 \(s_t\) 是状态,\(a_t\) 是动作,\(r_{t+1}\) 是从 \(s_t\) 执行 \(a_t\) 后得到的奖励,\(s_{t+1}\) 是下一个状态。也可以把 terminal state 后的最后一个动作和奖励写进序列,具体记号会随教材略有差异。
Episode 通常指有明确开始和结束的一条完整 trajectory。它强调的是“这次交互从初始状态开始,并且到某个 terminal state 结束”。例如一局游戏、一次机器人导航任务、一次完整对话,都可以看成一个 episode。
Transition 是 trajectory 中的一步,通常写成:
它是很多 value-based 方法的基本样本单位。比如 TD(0)、Q-learning、DQN 的更新通常只需要一个 transition。
有些算法还需要把下一步动作也作为样本的一部分,例如 Sarsa 的更新目标包含 \(a_{t+1}\),因此它需要:
Rollout 更强调“生成样本的过程”。让当前策略 \(\pi\) 在环境里运行一段时间,采样出一条 trajectory 或一段 partial trajectory,这个过程就叫 rollout。也就是说:
在 LLM 语境中也常说 rollout:给定 prompt,让模型根据当前策略生成一段回答,这也是一次 rollout。生成出来的 token 序列就可以看成 trajectory。
Replay buffer 是保存样本的数据容器。它可以保存 transition,也可以保存整条 trajectory 或短 rollout。DQN 这类 off-policy 方法常用 replay buffer:先把历史 transition 存起来,训练时再随机采样 mini-batch。
所以这些词可以用一个简单关系串起来:
Rollout(采样过程)
↓
Trajectory(完整或部分交互序列)
↓
Episode(有终止状态的一整条 trajectory)
↓
Transition(trajectory 中的一步)
不同算法需要不同粒度的样本。TD 和 Q-learning 通常只需要 transition;Sarsa 需要多一个下一步动作;Monte Carlo 和 policy gradient 往往需要一整条 trajectory 或 episode;GAE 和 actor-critic 常用一段 rollout 来构造 advantage estimate。
Bootstrapping 和 Non-bootstrapping
Bootstrapping 指更新目标里使用了当前 value estimate。例如 TD target:
这里的 \(v_t(S_{t+1})\) 是当前估计值,所以 TD 是 bootstrapping。
更准确地说,bootstrapping 不是“截断轨迹”本身,而是“截断之后用当前估计值补上未来部分”。例如完整 return 是:
TD(0) 没有等到完整 return,而是在一步后截断,并用当前估计 \(v_t(S_{t+1})\) 代替后面的未来回报:
这就是 bootstrapping。
但不是所有截断轨迹的方法都叫 bootstrapping。如果只取前 \(n\) 步奖励,然后直接忽略后面的未来:
这只是 truncated return,不是 bootstrapping。因为它没有使用当前 value estimate 或 Q estimate。
如果截断后接上当前估计值:
这才是 n-step bootstrapping。
所以可以这样区分:
| 方法 | 是否截断轨迹 | 是否 bootstrapping |
|---|---|---|
| Monte Carlo | 否,等完整 episode | 否 |
| TD(0) | 是,一步截断 | 是 |
| n-step TD | 是,\(n\) 步截断 | 是,如果后面接 \(v_t(S_{t+n})\) |
| Truncated return without value estimate | 是 | 否 |
| GAE / λ-return | 混合多个 n-step return | 通常是 |
| Q-learning / DQN | 是,一步截断 | 是 |
所以,一个更准确的说法是:很多 bootstrapping 方法都会截断轨迹,但不是所有截断轨迹的方法都是 bootstrapping。只有当截断后用当前 value estimate 或 Q estimate 去补未来部分时,才叫 bootstrapping。
Monte Carlo 使用完整 return,不依赖当前 value estimate,因此是 non-bootstrapping。TD、Sarsa、Q-learning、DQN 都是 bootstrapping,因为它们的更新目标里都用了当前的 value 或 Q estimate。
Tabular 和 Function Approximation
Tabular 方法把每个状态或 state-action pair 的 value 单独存在表里。它清晰、稳定,但无法扩展到大规模状态空间。
Function approximation 用参数化函数表示 value 或 policy,例如线性模型或神经网络。它可以泛化到没见过的状态,但也引入优化不稳定性。
Value-based、Policy-based 和 Actor-Critic
Value-based 方法先学习 value,再由 value 导出策略。Value iteration、Q-learning、DQN 都属于 value-based。
Policy-based 方法直接优化参数化策略。Policy gradient、REINFORCE 属于 policy-based。
Actor-Critic 是二者结合:actor 学策略,critic 学 value,用 value 信号帮助 policy update。
Episodic Task 和 Continuing Task
Episodic task 有明确终止状态,一条 episode 会结束。例如很多游戏关卡和一次完整对话任务。
Continuing task 没有自然终止状态,智能体会持续和环境交互。TD 方法适合 continuing task,因为它不需要等完整 episode 结束。
常见算法的粗略分类
| 算法 | 是否需要模型 | On-policy / Off-policy | Online / Offline | 是否 bootstrapping |
|---|---|---|---|---|
| Value iteration | Model-based | 不强调 | Offline planning | 是 |
| Policy iteration | Model-based | 不强调 | Offline planning | 是 |
| Monte Carlo control | Model-free | 通常 on-policy | 通常 offline | 否 |
| TD state value learning | Model-free | On-policy evaluation | Online | 是 |
| Sarsa | Model-free | On-policy | Online | 是 |
| Q-learning | Model-free | Off-policy | Online | 是 |
| DQN | Model-free | Off-policy | Online / replay buffer | 是 |
| REINFORCE | Model-free | On-policy | 通常按 episode 更新 | 否 |
| Actor-Critic / A2C | Model-free | 通常 on-policy | Online | 是 |
| Off-policy Actor-Critic | Model-free | Off-policy | Online / replay buffer | 是 |
RL for LLM
适用于大模型的强化学习
在上一章节中,我们介绍了强化学习的基本概念和一些传统算法。不过,这些算法里有很多内容和大模型语境下的强化学习并不是直接对应的。比如在大模型训练中,我们通常不会显式求解 Bellman 方程,也很少像传统表格型强化学习那样维护一个完整的 state value table 或 Q table。
这并不意味着上一节不重要。恰恰相反,上一节真正需要保留下来的,是强化学习的基本问题定义:状态、动作、策略、轨迹、奖励、return、value、on-policy / off-policy、policy-based / value-based 等概念。这些概念是我们理解大模型训练中的 RLHF、PPO、GRPO、DPO 等方法的框架和地基.
这一节开始,我们尝试从头建立大模型体系下的强化学习视角(LLM 是怎么被建模成RL的? LLM相关的RL算法是如何定义的,它们之间的联系又是什么?):
- LLM 为什么可以被看成一个强化学习里的 policy?
- LLM 生成文本时,状态、动作、轨迹、奖励分别是什么?
- 为什么 value-based 方法不太适合 LLM,而 policy-based 方法更自然?
- Policy Gradient 如何成为 PPO、GRPO、RLHF 这条线的起点?
- RLHF、PPO、GRPO、DPO 之间到底是什么关系?
LLM 如何被建模成一个 RL 问题?
Q: 为什么大模型训练会用到强化学习?
预训练语言模型的基本目标是 next-token prediction。给定一段文本前缀,模型学习预测下一个 token。这个目标可以写成最大化训练语料的似然,或者等价地最小化交叉熵损失。
如果只做预训练,模型学到的是“在互联网文本分布中,下一个 token 最可能是什么”。但是我们真正希望聊天模型具备的能力,往往不是简单地复现互联网文本分布,而是:
- 回答应该有帮助。
- 回答应该符合人类偏好。
- 回答应该遵循指令。
- 回答应该避免有害内容。
- 在推理任务中,回答应该尽量正确。
这些目标很难直接写成一个逐 token 的监督学习标签。对于同一个 prompt,可能有很多种合理回答;而且人类偏好通常是对完整回答的整体评价,而不是对每个 token 单独打分。
这时,强化学习的视角就自然出现了:模型生成一段回答,外部环境或奖励模型对这段回答给出一个奖励,然后我们希望调整模型参数,让未来生成的回答获得更高的奖励。
换句话说,监督学习更像是在问:
给定这个前缀,下一个 token 应该是什么?
而强化学习更像是在问:
给定这个 prompt,模型应该生成怎样的一整段回答,才能获得更高的整体评价?
这就是 LLM 与 RL 建立联系的入口。
Q: LLM 如何被建模成一个 RL 问题?
回忆上一节中强化学习的基本对象。一个智能体在状态 \(S_t\) 下,根据策略 \(\pi\) 选择动作 \(A_t\),环境给出奖励 \(R_{t+1}\),并转移到下一个状态 \(S_{t+1}\)。
在 LLM 生成文本的场景中,我们可以把一次回答生成建模成一个有限长度的 episode。
设用户输入的 prompt 为 \(x\),模型生成的回答 token 序列为:
其中:
- \(x\) 表示 prompt。
- \(y_t\) 表示第 \(t\) 个生成 token。
- \(y_{<t}=(y_1,\dots,y_{t-1})\) 表示第 \(t\) 步之前已经生成的 token 前缀。
- \(T\) 表示回答长度,可以是固定长度,也可以由终止 token 决定。
于是,LLM 的 RL 建模可以写成:
| RL 概念 | LLM 中的对应对象 |
|---|---|
| 状态 \(s_t\) | prompt 和当前已生成前缀 \((x,y_{<t})\) |
| 动作 \(a_t\) | 下一个 token \(y_t\) |
| 策略 \(\pi_\theta(a_t\mid s_t)\) | 语言模型的 next-token 分布 \(\pi_\theta(y_t\mid x,y_{<t})\) |
| 轨迹 \(\tau\) | 一次完整生成 \((x,y_1,\dots,y_T)\) |
| 奖励 \(R\) | 对完整回答或中间步骤的评分 |
| episode | 从 prompt 开始,到回答结束的一次生成过程 |
因此,语言模型本身就是一个参数化策略,我们使用\( \pi_\theta \) 替代之前的 \( P \) 来更好的符合强化学习的语境:
其中:
- \(\pi_\theta\) 是由参数 \(\theta\) 决定的语言模型策略。
- \(x\) 是 prompt。
- \(y_{<t}\) 是当前状态中已经生成的 token 前缀。
- \(y_t\) 是当前动作,也就是下一个 token。
一整段回答的生成概率可以写成自回归分解:
这个公式非常重要。它说明:虽然奖励通常是对完整回答 \(y\) 给出的,但是模型实际做决策时,是一步一步选择 token。LLM 的强化学习训练,本质上就是用完整回答级别的奖励,去更新每一步 token 选择的概率。
Q: LLM 中的奖励是什么?
在传统 RL 中,奖励 \(R_{t+1}\) 通常来自环境。例如游戏中得分增加、机器人到达目标位置等。
在 LLM 中,奖励的来源更加灵活。常见情况包括:
- 人工偏好奖励:人类标注者比较两个回答,指出哪个更好。
- 奖励模型 reward model:先用人类偏好数据训练一个模型,再由这个模型给回答打分。
- 规则奖励:例如答案是否匹配标准答案、代码是否通过测试、数学题结果是否正确。
- 混合奖励:把格式、正确性、安全性、长度惩罚、KL 惩罚等组合起来。
LLM引入强化学习框架,就是为了引入更灵活的Reward系统.比如你很难通过之前的NLL损失来定义一个模型具体的表现,比如它是否符合某个风格,或者模型正确的完成了某个指令,或者做了哪个操作.尤其是操作这种思想,非常符合RL的框架.
最常见的 RLHF 设置中,奖励通常是回答级别的。也就是说,模型先完整生成回答 \(y\),然后 reward model 给出一个标量:
其中:
- \(r_\phi\) 是参数为 \(\phi\) 的奖励模型。
- \(x\) 是 prompt。
- \(y\) 是模型生成的完整回答。
- \(r_\phi(x,y)\) 是这段回答的奖励分数。
这和传统 RL 中每一步都有奖励的情况略有不同。对于 LLM 来说,很多时候中间 token 并没有明确奖励,只有整段回答结束后才知道好坏。因此,LLM 强化学习经常面对的是一种 sparse reward 或 sequence-level reward。
为了把它放回上一节的 return 记号中,可以把回答结束时的奖励看成最终奖励:
而中间步骤的奖励近似看成 0:
这时,从生成开始的 return 主要由最终回答奖励决定。
Q: 为什么 value-based 方法在 LLM 中不常用?
上一节介绍的 Q-learning、DQN 等很多传统RL方法都属于 value-based 方法。它们通常先学习 action value:
然后通过比较不同动作的 Q value 来选择动作。最典型的是 Q-learning 中的 greedy 目标:
但是在 LLM 中,这条路线会遇到几个困难。
第一,状态空间极大。LLM 的状态 \(s_t=(x,y_{<t})\) 是 prompt 加任意长度的 token 前缀。这个空间的维度非常惊人.
第二,动作空间很大。动作是词表中的 token,常见词表大小可以达到几万到十几万。每一步都显式估计所有 token 的 Q value,成本很高。
第三,奖励通常是完整回答级别的。一个 token 的好坏高度依赖后续 token。比如同一个 token 在不同推理链条中可能有完全不同的意义。单独学习 \(q(s_t,y_t)\) 并不容易。
第四,LLM 本身已经天然是一个 policy。预训练模型直接给出:
也就是说,我们已经有了一个非常强的参数化策略。与其重新学习一个 Q function 再由 Q function 导出策略,不如直接优化这个策略本身。
所以在 LLM 场景中,主流方法更多走 policy-based 的路线:直接调整 \(\pi_\theta\),让它生成更高奖励的回答。
不过,从传统 RL 的视角看,即使我们直接优化策略,value function 也没有完全消失。PPO 这类 actor-critic 方法通常仍然会训练 value model,用来估计 advantage、降低梯度方差。区别在于,value 在这里主要是 policy update 的辅助量,而不是像 Q-learning 那样作为导出策略的核心对象。
这也是 LLM 中 RL 和传统 RL 的一个重要差异:在大模型训练里,reward 和 value 的地位会被进一步改写。奖励通常来自规则、偏好数据或 reward model;下一节会先从 RL 视角重新解释介绍 Policy Gradient族算法,然后在下一章节再回到LLM语境下的RL.
Policy Gradient
至此,我们开始进入 policy-based 方法的主线。前面介绍 value-based 方法时,核心是先估计 value 或 Q value,再从 value 中导出策略;而 Policy Gradient 的想法更直接:既然策略本身可以写成一个带参数的函数 \(\pi_\theta(a\mid s)\),那就直接优化这个策略。
这部分先从传统 RL 的视角推导,再回到 LLM。原因是 PPO、GRPO、RLHF 虽然应用在大模型上,但它们背后的梯度形式、advantage、critic、GAE 等概念都来自传统 Policy Gradient 和 Actor-Critic。
Q: Policy Gradient 要解决什么问题?
在表格型 RL 中,策略可以直接存成一张表 \(\pi(a\mid s)\)。但一旦状态空间很大,我们通常会把策略表示成参数化函数:
其中:
- \(\theta\) 是策略函数的参数。
- \(s\) 是状态。
- \(a\) 是动作。
- \(\pi_\theta(a\mid s)\) 表示在状态 \(s\) 下选择动作 \(a\) 的概率。
这时,策略优化的问题就变成了:如何选择一组参数 \(\theta\),让策略的整体表现最好?
因此我们需要先构造一个标量目标函数:
然后用梯度上升更新参数:
这就是 Policy Gradient 的基本形式。真正困难的地方在于两个问题:
- \(J(\theta)\) 应该怎么定义?
- \(\nabla_\theta J(\theta)\) 应该怎么计算和采样估计?
Q: 为什么先回顾 value 和 Q value?
虽然 Policy Gradient 是 policy-based 方法,但它并没有完全摆脱 value。相反,Policy Gradient 的推导中会自然出现 \(q_\pi(s,a)\),后面的 Actor-Critic、Advantage、GAE 也都依赖 value function。
先回顾 return。设从时刻 \(t\) 开始的折扣回报为:
也可以写成:
其中:
- \(G_t\) 是从时刻 \(t\) 开始的 return。
- \(R_{t+i+1}\) 是未来第 \(i+1\) 步的奖励。
- \(\gamma\in[0,1)\) 是折扣因子。
State value 定义为:
Action value 定义为:
通过全期望公式,可以得到:
这一步很关键。后面我们会看到目标函数式根据 State Value 构造的,但是我们如果想要优化策略,就需要通过Action Value建立桥梁(变成 Action 的期望 策略显式的出现在目标里面.)
另一个很重要的点会在后面体现,就是所有的Reward都体现在 State Value 或者 Action Value 里面.所以即使我们直接优化策略,也无法完全摆脱 value 的概念.
Q: Policy Gradient 的目标函数怎么构造?
在参数化策略中,我们通常不再要求“每个状态的 value 都同时最大”,而是定义一个整体标量目标。一个常见目标是平均 state value:
其中:
- \(d(s)\) 是状态 \(s\) 的权重,可以理解为某种状态分布。
- \(v_{\pi_\theta}(s)\) 是策略 \(\pi_\theta\) 下状态 \(s\) 的 value。
- \(J(\theta)\) 是策略的整体表现。
如果把 \(v_{\pi_\theta}(s)\) 展开成 action value,就得到:
这个式子很直观:对于每个状态,策略会给不同动作分配概率;动作越好,也就是 \(q_{\pi_\theta}(s,a)\) 越大,我们越希望策略给它更高概率。
为了书写更简洁,后面把状态权重记作 \(\eta(s)\)。我们的核心是想要求损失函数的梯度:
这里暂时可以先把它理解成“对策略概率求梯度,再用动作价值加权”。更完整的推导中,\(q_{\pi_\theta}\) 也依赖 \(\theta\),但 Policy Gradient 定理会把这些间接影响整理进状态分布权重里,最终得到上面的紧凑形式。对于理解后续算法,记住这个形式已经足够。
Q: \(q_{\pi_\theta}(s,a)\) 也依赖 \(\theta\),为什么 Policy Gradient 里不显式对它求导?
这是 Policy Gradient 里最容易困惑的一点。直觉上,\(q_{\pi_\theta}(s,a)\) 当然依赖 \(\theta\),因为它表示在当前策略 \(\pi_\theta\) 下,从 \((s,a)\) 出发之后的期望 return:
后续动作如何采样由 \(\pi_\theta\) 决定,所以 \(q_{\pi_\theta}\) 不可能真的和 \(\theta\) 无关。
因此,Policy Gradient 并不是假设:
更准确地说,Policy Gradient Theorem 说明:当我们从完整轨迹分布出发对目标求导时,\(q_{\pi_\theta}\) 对 \(\theta\) 的间接依赖,会被轨迹概率 \(p_\theta(\tau)\) 的求导统一吸收。最终梯度可以整理成:
一个更直接的理解方式是从 trajectory 形式开始。设一条轨迹为 \(\tau\),目标是:
这里把 \(G(\tau)\) 写成不带 \(\theta\) 的形式,是因为 \(G(\tau)\) 表示“给定一条已经确定的轨迹后,这条轨迹上实际得到的 return”。例如:
那么:
一旦 \(\tau\) 固定,里面的状态、动作、奖励序列都已经固定,所以 \(G(\tau)\) 对 \(\theta\) 不再变化。策略参数 \(\theta\) 真正影响的是:什么样的轨迹更容易被采样出来,也就是 \(p_\theta(\tau)\)。
对 \(\theta\) 求导:
使用 log-derivative trick:
于是:
而轨迹概率可以分解为策略概率和环境转移概率。环境转移概率通常不依赖 \(\theta\),所以:
这就是为什么最终梯度只需要对 policy 的 log probability 求导。\(q_{\pi_\theta}(s,a)\) 或 return 作为权重出现,用来告诉策略“这个动作后续结果好不好”;但 actor 更新时,不需要沿着 \(q_{\pi_\theta}\) 本身继续反传。
不过,这里有一个重要前提:reward 本身不能显式依赖策略参数 \(\theta\)。在标准 RL 里,reward 通常来自环境,所以满足这个前提。LLM 中如果 reward 是冻结的 reward model:
并且 \(\phi\) 在 policy update 时固定,那么对给定的 \((x,y)\),\(R(x,y)\) 也可以看成和 \(\theta\) 无关。
但如果把 KL penalty 也合并进 reward,情况就要小心。例如:
这个 \(R_\theta(x,y)\) 显式依赖 \(\theta\)。严格求导时,除了 policy gradient 项,还会出现:
所以在推导 Policy Gradient 时,最好先把 reward 看成不显式依赖 \(\theta\) 的外部反馈;KL penalty 则作为额外 regularization / penalty 单独处理。这样记号和梯度路径都会更清楚。
在 actor-critic 的实现中,这一点通常表现为:critic / value model 单独训练,actor 更新时把 advantage 当作一个标量权重使用。例如伪代码常写成:
policy_loss = - log_prob(action) * advantage.detach()
这里的 \(\operatorname{detach}\) 并不是说 advantage 真的和策略无关,而是说在 policy gradient 这条更新里,advantage 是 sampled weight;critic 的参数通过自己的 value loss 更新。
所以,这个处理是靠谱的,但它不是一个朴素的“\(q\) 与 \(\theta\) 独立”的假设,而是 Policy Gradient Theorem / likelihood-ratio trick 的结果。
这个目标也可以直接写成期望形式。因为 \(d(s)\) 可以看成状态 \(S\) 的分布,所以:
继续把 state value 展开成 action value:
于是总目标也可以写成:
这个写法更接近后面 Policy Gradient 的推导,因为它明确告诉我们:目标函数本质上是一个关于状态和动作的期望。后面要做的事情,就是对这个期望关于 \(\theta\) 求梯度,并把它改写成可以用样本估计的形式。
Q: log-derivative trick 是什么?
上面的式子里有 \(\nabla_\theta \pi_\theta(a\mid s)\),但实际采样时,我们更希望把梯度写成某个期望的形式。这里要用到 log-derivative trick:
因此:
把它代入 Policy Gradient:
于是可以写成期望形式:
这个公式就是 Policy Gradient 的核心。它把“对整个策略函数求梯度”的问题,变成了“从策略中采样状态和动作,然后构造一个随机梯度估计”的问题。
从期望的角度看,这个变换的思想非常明确:\(\nabla_\theta \pi_\theta(a\mid s)\) 本身并不难计算,真正困难的是状态 \(S\) 的期望不容易直接求。经过 log-derivative trick 之后,目标里显式引入了动作 \(A\) 的期望,而动作可以直接从策略 \(\pi_\theta(\cdot\mid S)\) 中采样,所以我们得到了一种可行的随机梯度估计。不过严格来说,一条有限 rollout 中的状态样本并不自动等同于从理论状态分布 \(\eta(s)\) 中采样,下面单独解释这一点。
Q: 为什么 Q value 仍然会出现在 Policy Gradient 里?
Policy Gradient 是直接优化策略,但更新方向仍然需要知道某个动作好不好。这个“动作好不好”的信号就是 \(q_{\pi_\theta}(S,A)\)。
如果 \(q_{\pi_\theta}(S,A)\) 很大,那么梯度项:
会推动策略提高动作 \(A\) 在状态 \(S\) 下的概率。反过来,如果某个动作带来的 return 很低,它对更新的贡献也会更小,甚至在使用 advantage 后会变成负向更新。
所以,Policy Gradient 和 value-based 方法的区别不是“要不要 value”,而是:
- value-based 方法通常先学习 value,再由 value 导出策略。
- policy-based 方法直接学习策略,但需要 value / return 信号来告诉策略哪些动作值得增加概率。
从期望推导的理论上来看,为了让策略的参数直接出现在目标函数里,我们引入了 \(\pi_\theta(a \mid s)\) 这个可以优化的目标,也就引入了 \(A\) 的期望。从 state value \(v_{\pi_\theta}(S)\) 转变到了 action value \(q_{\pi_\theta}(S,A)\)。
Q: Policy Gradient 如何用样本估计?
真实的期望:
通常无法直接计算。我们能做的是从当前策略 \(\pi_\theta\) 中采样数据。一次 episode 可以写成轨迹:
然后用轨迹中的样本 \((s_t,a_t)\) 构造随机梯度:
其中 \(\hat{q}(s_t,a_t)\) 是 \(q_{\pi_\theta}(s_t,a_t)\) 的估计。不同的 Policy Gradient 算法,核心差别之一就在于:如何估计这个 \(\hat{q}(s_t,a_t)\)。
rollout 采样到的状态真的来自 \(\eta(s)\) 吗?
这里有一个容易混淆的点:Policy Gradient 公式中的状态权重 \(\eta(s)\) 是理论上的状态分布或状态权重,而一次有限长度 rollout 中出现的状态序列,并不一定严格服从这个分布。
换句话说,我们在 rollout 中拿到的是一串相关的样本 \((s_t,a_t)\),它们是否真的可以看成来自理论联合分布 \(\eta(s)\pi_\theta(a\mid s)\),需要更仔细地区分。
如果我们讨论的是 continuing task,并且把 \(\eta(s)\) 取为策略 \(\pi\) 诱导的稳态分布 \(d^\pi(s)\),那么它满足:
这个式子表示:如果当前状态服从 \(d^\pi\),经过一步策略选择和环境转移之后,下一个状态仍然服从 \(d^\pi\)。
但是 rollout 通常从某个初始分布 \(\mu(s_0)\) 开始:
如果初始分布 \(\mu\) 本身不是稳态分布,那么 rollout 前期的状态分布就不是 \(d^\pi(s)\)。这部分通常称为 transient phase,也就是过渡阶段。
在马尔可夫链满足不可约、非周期、正再生等条件时,随着时间趋于无穷,状态分布会收敛到唯一稳态分布:
所以更严谨的说法是:有限 rollout 中的状态样本不严格服从 \(d^\pi(s)\);足够长的 rollout,在丢弃前期 transient 后,可以近似看作来自 \(d^\pi(s)\)。
这也是为什么 REINFORCE、A2C、PPO 这类 on-policy 方法通常不显式估计 \(\eta(s)\)。它们直接用当前策略采样 rollout,再用这些样本对期望做 Monte Carlo 近似。
不过还要注意:在 episodic 或 discounted setting 中,\(\eta(s)\) 不一定是严格的稳态分布。它也可以表示从初始状态分布出发、在策略 \(\pi\) 下产生的 discounted visitation distribution。此时 rollout 近似的是这个访问分布,而不是 continuing task 中的 stationary distribution。
Q: REINFORCE 是什么?
REINFORCE 是最经典、最简单的 Policy Gradient 算法。它用 Monte Carlo return 来估计 \(q_\pi(s_t,a_t)\)。
根据 Q value 的定义:
如果我们已经采样到一整条 episode,就可以用这条 episode 中从 \(t\) 开始的实际 return:
作为 \(q_\pi(s_t,a_t)\) 的样本估计。这里使用 \(\hat{G}_t\) 而不是 \(G_t\),是为了强调它是这一次 rollout 中实际算出来的样本值;而 \(G_t\) 更像是理论上的随机变量。
于是 REINFORCE 在时刻 \(t\) 的样本梯度方向是:
如果把一整条 episode 中每个时间步的贡献加起来,那么一次 episode 给出的梯度估计可以写成:
如果用梯度上升写参数更新:
从操作流程上看,REINFORCE 可以分成几步。
第一步,用当前策略 \(\pi_\theta\) 和环境交互,采样一条完整 episode:
第二步,从 episode 末尾往前计算每个时间步的样本 return \(\hat{G}_t\)。这一步是 Monte Carlo 估计,因为它直接使用这条轨迹中真实发生的后续奖励。
第三步,把每个动作的 log probability 梯度乘上对应的 \(\hat{G}_t\)。如果某个时间步之后得到的 return 高,就增加当时动作的概率;如果 return 低,就减少它的概率。
第四步,把整条 episode 上的梯度贡献加起来,用梯度上升更新策略参数。
举一个很小的例子。假设一条 episode 是:
并且折扣因子 \(\gamma=0.9\)。那么从后往前可以算出:
于是这条 episode 给出的策略梯度估计是:
这个例子体现了 REINFORCE 的直觉:一条轨迹最终表现好,那么轨迹中导致这个结果的动作会得到更大的正向更新;如果 return 本身为负,或者后面引入 baseline / advantage 后相对表现为负,那么对应动作概率就会被压低。
REINFORCE 的优点是概念非常干净:采样一条轨迹,用实际 return 来更新策略。缺点也很明显:必须等到 episode 结束才能得到完整 return,而且 Monte Carlo return 的方差通常很大。后面的 baseline、advantage、actor-critic 和 GAE,都是在这个基础上让估计更稳定。
Q: 为什么可以加入 baseline?
为了降低方差,可以从 \(q_\pi(S,A)\) 中减去一个只依赖状态的 baseline \(b(S)\)。新的梯度形式是:
为什么这样不改变期望?因为:
展开来看:
而:
所以 baseline 不改变梯度的期望,但会改变随机梯度的方差。一个好的 baseline 可以让采样估计更稳定。
直觉上看baseline提供一个参考线,用动作的相对水平来代替动作的绝对水平.理论上这就像是归一化,降低估计的方差,稳定估计结果.
Q: Advantage function 是什么?
常见的 baseline 选择是 state value:
这样就得到 advantage function:
其中:
- \(q_\pi(S,A)\) 表示在状态 \(S\) 下采取动作 \(A\) 后的期望 return。
- \(v_\pi(S)\) 表示在状态 \(S\) 下按照当前策略平均行动的期望 return。
- \(A_\pi(S,A)\) 表示动作 \(A\) 相对于当前状态平均水平的优势。
使用 advantage 后,Policy Gradient 可以写成:
这个形式比直接使用 \(q_\pi(S,A)\) 更合理。因为策略更新真正关心的不是“这个动作的绝对回报是多少”,而是“这个动作是否比当前状态下的平均选择更好”。
如果 \(A_\pi(S,A)>0\),说明动作 \(A\) 比平均水平好,应该提高它的概率;如果 \(A_\pi(S,A)<0\),说明动作 \(A\) 比平均水平差,应该降低它的概率。
Q: Actor-Critic 是什么?
REINFORCE 用完整 return 估计 \(q_\pi(s,a)\),方差比较大。Actor-Critic 的想法是:既然我们需要 value 信号来更新策略,那就额外训练一个 value function 估计器来提供这个信号。
Actor-Critic 中有两个角色:
- Actor:策略函数 \(\pi_\theta(a\mid s)\),负责选择动作,并通过 Policy Gradient 更新。
- Critic:value function 的函数近似器,例如 \(v_w(s)\) 或 \(q_w(s,a)\),负责评估当前策略的动作或状态。
这里的 \(w\) 是 critic 的参数。也就是说,真实的 \(v_\pi(s)\) 通常无法直接计算,我们用一个带参数的函数 \(v_w(s)\) 去拟合它:
所以 Actor-Critic 实际上通常要同时维护两个函数:
- actor network:\(\pi_\theta(a\mid s)\),参数是 \(\theta\),负责产生动作概率。
- critic network:\(v_w(s)\) 或 \(q_w(s,a)\),参数是 \(w\),负责给 actor 提供 value / advantage 信号。
最直接的 actor update 可以写成:
critic 的任务则是学习 \(\hat{q}(s_t,a_t)\) 或 \(\hat{v}(s_t)\)。如果 critic 用 TD learning,就可以不等完整 episode 结束,而是用一步 transition 来更新。
如何估计 state value 或者 action value. 这些就是之前提到的 value-based 方法的内容了,可以参阅之前一节.虽然我们一开始就提到了LLM中使用 Policy based方法就是为了避开对Value的估计.(因为LLM系统中不好定义Value).不过原始RL算法中的Policy Gradient方法并没有完全摆脱Value的概念,它在推导过程中依然要引入Value function(Baseline,Advantage,GAE等算法都是为了估计Value function而设计). 不过幸运的是,LLM中的Value一般和传统RL语境中的Value不太一样.我们后续会看到.
Q: Advantage 如何用 TD error 估计?
在 Advantage Actor-Critic 中,我们通常不单独估计 \(q_\pi(s,a)\),而是用 state value \(v_w(s)\) 构造 advantage 的近似。这里 \(v_w(s)\) 是用函数近似拟合出来的 \(v_\pi(s)\),\(w\) 是 critic 的参数;actor 仍然是 \(\pi_\theta(a\mid s)\),\(\theta\) 是策略参数。因此整个算法同时维护 actor 和 critic 两个网络。
回忆 Bellman 关系:
因此 advantage 可以写成:
把上面的两个式子合在一起,可以看到 advantage 本身也是一个条件期望:
实际训练时,我们从 rollout 里拿到一个 transition 样本 \((s_t,a_t,r_{t+1},s_{t+1})\),再用 \(v_w\) 代替真实的 \(v_\pi\)。这样就得到一步 TD error:
这个 \(\delta_t\) 就可以看成 \(A_\pi(s_t,a_t)\) 的一步样本估计:
于是 A2C (Advantage Actor-Critic) 的 actor update 可以写成:
critic 则用同一个 TD error 更新 value function:
这就是 Actor-Critic 的基本闭环:critic 用 TD error 学 value,actor 用 TD error 作为 advantage 信号更新策略。
Q: GAE 是什么?
一步 TD error 方差较小,但可能有偏;完整 Monte Carlo return 偏差较小,但方差大。GAE,也就是 Generalized Advantage Estimation,试图在两者之间折中。
这句话有点费解: 为什么一般的 MCMC(样本数越多方差越小),但 RL 里的 Monte Carlo return 却随着 horizon 增长方差越来越大?这是因为: MCMC 说的是“估计器的方差随样本数减少”。RL 里的 MC return 说的是“单个样本本身的方差随 horizon 增加而变大”。
它要估计的对象仍然是 advantage:
使用的样本来自当前策略采样得到的一段 rollout:
critic 提供每个状态上的 value 估计:
从期望的角度看,\(n\)-step bootstrap 版本的 advantage 估计对象可以写成:
对应到一条 rollout 样本,就把随机变量替换成采样值,并用 \(v_w\) 近似 \(v_\pi\):
先定义每一步 TD error:
如果只看一步,那么 advantage 的估计就是 TD error:
如果向前多展开一步,就会得到二步 advantage 估计:
继续展开,\(n\)-step advantage 估计可以写成:
这和上面的 \(n\)-step return 写法是等价的,只是改写成了 TD error 的累加形式。这个式子说明了 GAE 的直觉:一步是 TD,展开很多步就越来越接近 Monte Carlo return。更准确地说,GAE 不是只选择某一个 \(n\),而是把不同长度的 \(n\)-step advantage 做指数加权平均:
把 \(\hat{A}_t^{(n)}\) 展开并交换求和顺序,可以得到更常见的形式:
其中:
- \(\hat{A}_t^{\text{GAE}(\gamma,\lambda)}\) 是时刻 \(t\) 的 advantage 估计。
- \(\gamma\) 是奖励折扣因子。
- \(\lambda\in[0,1]\) 控制 bias 和 variance 的折中。
实际实现时,GAE 通常不是从前往后显式求无穷和,而是在一段 rollout 上从后往前递推。令 \(\hat{A}_{t+1}^{\text{GAE}}\) 已经算好,则:
如果 rollout 在 \(T\) 处终止,通常令终止状态之后的 advantage 为 0;如果只是截断了一段固定长度的 rollout,则可以用 critic 对最后一个状态 \(s_T\) 的估计 \(v_w(s_T)\) 做 bootstrap。
当 \(\lambda=0\) 时,GAE 退化为一步 TD error:
当 \(\lambda\) 接近 1 时,它会利用更长的未来轨迹,更接近 Monte Carlo return。也就是说,GAE 可以看成从 TD 到 MC 的连续过渡:\(\lambda\) 越小,越依赖短期 bootstrap;\(\lambda\) 越大,越依赖长轨迹回报。
所以 GAE 估计的是 \(A_\pi(s_t,a_t)\) 这个期望对象;它使用的是 on-policy rollout 中的 reward、next state,以及 critic 给出的 \(v_w(s)\)。PPO 中常用 GAE 来估计 advantage,因为它在稳定性和样本效率之间比较平衡。
Q: PPO 是什么?
PPO,全称 Proximal Policy Optimization,是一种基于 Policy Gradient 的 actor-critic 算法。它要解决的问题是:我们希望用当前策略采样到的 rollout 改进 actor,但又不希望一次更新把新策略推得离旧策略太远。
如果策略更新过大,会出现两个问题。第一,旧策略 \(\pi_{\theta_{\text{old}}}\) 采样得到的数据很快变得“不像”新策略 \(\pi_\theta\) 下的数据,on-policy 估计会变差;第二,actor 的概率变化过猛,可能把原本还不错的行为直接破坏掉,训练会变得不稳定。
PPO 的核心想法是:允许新策略在旧策略附近改进,但限制新旧策略的差异。这里的“附近”不是指参数 \(\theta\) 的欧氏距离,而是指同一个状态动作样本上,新旧策略给出的概率不要相差太多。
更具体地说,PPO 在一次更新中会区分两个策略:
- \(\pi_{\theta_{\text{old}}}\):采样 rollout 时使用的旧策略。
- \(\pi_\theta\):当前正在优化的新策略。
给定旧策略采样得到的样本 \((s_t,a_t)\),PPO 比较新旧策略对同一个动作的概率:
其中 \(r_t(\theta)\) 称为 probability ratio。如果 \(r_t(\theta)>1\),说明新策略提高了旧样本中这个动作的概率;如果 \(r_t(\theta)<1\),说明新策略降低了这个动作的概率。
PPO 的策略目标不是直接最大化 \(r_t(\theta)\hat{A}_t\),而是使用 clipped surrogate objective:
其中:
- \(\hat{A}_t\) 是 advantage 估计,通常来自 TD error 或 GAE。
- \(\epsilon\) 是裁剪范围,常见取值是 0.1 或 0.2。
- \(\operatorname{clip}(r_t,1-\epsilon,1+\epsilon)\) 会把 ratio 限制在 \([1-\epsilon,1+\epsilon]\) 内。
- \(\min\) 的作用是:当新策略相对旧策略改得过猛时,不再继续给这个方向额外收益。
因为 PPO 是 actor-critic 算法,它通常还会同时训练 critic。critic 的目标是让 \(v_w(s_t)\) 接近某个 return 目标 \(\hat{R}_t\),例如 Monte Carlo return 或 bootstrapped return:
实际实现中,还经常加入 entropy bonus,鼓励策略保持一定探索性:
把这些部分合在一起,PPO 的常见优化目标可以写成:
这里 \(c_1\) 控制 value loss 的权重,\(c_2\) 控制 entropy bonus 的权重。因为我们通常把整体目标写成“最大化”,所以 value loss 前面是负号;如果实现里写成 loss 最小化,符号会相应反过来。
从一个完整训练循环看,PPO 大致做这些事:
- 用旧策略 \(\pi_{\theta_{\text{old}}}\) 与环境交互,采样一批 rollout。
- 对 rollout 中每个时间步,计算 reward、return 目标 \(\hat{R}_t\),以及 advantage 估计 \(\hat{A}_t\)。
- 保存旧策略在样本动作上的 log probability,也就是 \(\log \pi_{\theta_{\text{old}}}(a_t\mid s_t)\)。
- 固定这批 rollout,打乱成 mini-batch,对 actor 和 critic 做多轮梯度更新。
- actor 更新时计算 \(r_t(\theta)\),并最大化 clipped surrogate objective。
- critic 更新时最小化 value loss,让 \(v_w(s_t)\) 更接近 \(\hat{R}_t\)。
- 若达到最大 epoch、KL 超过阈值,或这批数据已经用完,就停止本轮更新。
- 把当前策略作为新的旧策略,重新采样 rollout,进入下一轮。
这里有一个很重要的细节:PPO 会对同一批 on-policy rollout 做多轮 mini-batch 更新,但不会无限重复使用旧数据。因为更新次数太多以后,\(\pi_\theta\) 会离 \(\pi_{\theta_{\text{old}}}\) 越来越远,这批旧样本就不再适合估计当前策略的梯度。clipping 正是在这个局部范围内,让“多用几轮样本”和“保持 on-policy 近似”之间取得折中。
因此 PPO 可以理解为:在 Actor-Critic 框架上,加了一个“不要离旧策略太远”的策略更新约束。下一节的 surrogate objective,就是在解释这个约束对应的目标函数从哪里来。
Q: PPO 的 surrogate objective 从哪里来?
其实PPO的思想很直接,从数据样本的角度看,每次更后我的策略已经变了,所以我也不能直接用之前的样本继续更新我的现在的策略.就像是 off-policy 学习一样,我需要使用 importance sampling 来对旧策略进行修正. 而 Clipping 就是确保新旧策略不会偏离的太远,虽然在数学上没有这个限制,但是实际使用中差异过大意味着数值不稳定性,极大可能导致训练崩溃.
如果样本来自旧策略 \(\pi_{\theta_{\text{old}}}\),而我们要更新的是新策略 \(\pi_\theta\),就需要用 importance sampling 把旧策略下的样本改写成新策略下的局部目标:
定义概率比值:
那么 PPO 的基础 surrogate objective,也就是还没有裁剪的目标,就是:
但是如果 \(r_t(\theta)\) 变化太大,策略会更新得过猛。PPO 在这个 surrogate objective 上加入 clipping,限制新旧策略差异,也就是上一节写到的 clipped surrogate objective。
Q: PPO 是 on-policy 还是 off-policy?
这个问题很容易让人困惑,因为 PPO 同时具有两个看起来有点矛盾的特点:
第一,PPO 使用旧策略 \(\pi_{\theta_{\text{old}}}\) 采样得到的数据来更新新策略 \(\pi_\theta\)。这看起来像 off-policy。
第二,PPO 又通常被归类为 on-policy 算法。这看起来又和第一点冲突。
要解开这个问题,需要先区分两组概念:
| 维度 | 问的是什么 | 典型区别 |
|---|---|---|
| online / offline | 数据是不是训练过程中不断重新采样? | online 会持续和环境交互,offline 只用固定数据集 |
| on-policy / off-policy | 更新的策略和采样数据的策略是否一致或足够接近? | on-policy 用当前策略数据,off-policy 可以用其他策略的数据 |
PPO 首先是 online 的。因为它的典型训练流程是:
用当前策略采样 rollout
→ 用这批 rollout 更新几轮
→ 丢掉旧 rollout
→ 用更新后的策略重新采样 rollout
→ 继续训练
所以 PPO 不是 offline RL。Offline RL 指的是只给定一个固定数据集,训练过程中不再和环境交互采样。
更微妙的是 on-policy / off-policy。严格来说,PPO 的一次更新确实不是用“完全同一个策略”做采样和优化。数据来自旧策略:
而正在优化的是新策略:
所以 PPO 需要 importance sampling ratio:
从这个形式看,PPO 确实带有一点 off-policy correction 的味道。
但是 PPO 不是典型的 off-policy 算法。因为 \(\pi_{\theta_{\text{old}}}\) 不是很久以前的任意 behavior policy,而是刚刚用来采样 rollout 的上一版策略。PPO 还会通过 clipping 或 KL 约束限制 \(\pi_\theta\) 不要离 \(\pi_{\theta_{\text{old}}}\) 太远,并且通常只对同一批 rollout 做有限轮 mini-batch 更新,然后就重新采样。
因此 PPO 更准确的说法是:
PPO 是 online、近似 on-policy 的 policy optimization 算法。
或者说:
PPO 用上一版策略采样的数据,对当前策略做一个局部、小步的近似 on-policy 更新。
所以在常见分类中,PPO 通常放在 on-policy 一侧,而不是和 DQN、Q-learning 这类典型 off-policy 方法放在一起。
可以粗略对比如下:
| 算法 | online / offline | on-policy / off-policy |
|---|---|---|
| REINFORCE | online | on-policy |
| A2C / A3C | online | on-policy |
| PPO | online | near on-policy |
| Q-learning | online | off-policy |
| DQN | online | off-policy |
| Offline RL | offline | 通常是 off-policy |
一句话总结:
PPO 不是严格的纯 on-policy,但在算法分类里通常算 on-policy 或 near on-policy;它不是典型 off-policy,更不是 offline RL。
RL for LLM 2
RL 算法如何在 LLM 上应用
上一节已经把 LLM 放进了 RL 的基本框架里:prompt 和已生成前缀构成状态,下一个 token 是动作,完整回答是一条轨迹,奖励通常在回答结束后给出。本节继续往前走,讨论传统 RL 算法怎样落到 LLM 训练里,尤其是 Policy Gradient、PPO、GRPO、DPO 和 RLHF 之间的关系。
这里有一个关键点:即使是Policy Gradient这类直接优化Policy的算法,也没办法离开State value这个概念.这是因为传统RL框架里,所有的reward最终都会体现在State value里面.也就是说如果没有state value的话,实际上策略是无法学习到后续的reward的.
在 LLM 中,state value 的含义没有传统 RL 那么直观。传统环境里,状态 \(s\) 往往是一个清晰的环境状态;而在 LLM 中,状态是 \((x,y_{<t})\),也就是 prompt 加已经生成的前缀。State的维度过于巨大, RL中的State 定义方法会失去效果. LLM中的 State 和 Reward 不再像是一系列Reward定义的期望,而是直接使用稀疏的Reward Model或者规则奖励对整条轨迹定义Reward.这是和传统RL的一大区别.因此理解 LLM 中的 reward model、value model 和 advantage,是理解 RLHF/PPO 的关键。d
其中一个非常重要的因素是对于大模型来说,State value的定义并不是那么明显.但是如果看刚才PG族算法的推导,会发现即使是直接优化策略,我们也是离不开State value这个事情的.这是因为对于强化学习来说,所有的样本的反馈. Reward最后都体现在State value里面.也就是说如果没有state value的话,实际上策略是无法学习到后续的reward的.所以对于LLM来说,我们需要想办法定义state value.
Q: 简单回顾一下 LLM 中的状态、动作、奖励是什么?
在 LLM 中,一次回答生成可以看成一条 trajectory。给定 prompt \(x\),模型逐 token 生成回答:
对应到 RL 记号:
- 状态 \(s_t\):prompt 加已生成前缀,\(s_t=(x,y_{<t})\)。
- 动作 \(a_t\):下一个 token,\(a_t=y_t\)。
- 策略 \(\pi_\theta(a_t\mid s_t)\):语言模型的 next-token distribution,也就是 \(\pi_\theta(y_t\mid x,y_{<t})\)。
- 轨迹 \(\tau\):从 prompt 开始到完整回答结束的 token 序列。
- 奖励 \(R(x,y)\):对完整回答 \(y\) 的评价,可以来自人工偏好、reward model、规则奖励或可验证任务的结果。
因此,LLM 中一条轨迹的概率可以写成:
这和普通 RL 中 trajectory probability 的角色是一样的,只是环境状态被文本前缀替代,动作空间变成了词表。
注意这里,奖励变成了稀疏的,变成了对整条轨迹的奖励.而没有了传统RL中每一步都有reward的设定.这是LLM中的一个重要区别.在LLM中,通常会直接使用reward model或者规则奖励对整条轨迹定义reward,而不是像传统RL那样,把reward定义成每一步的即时reward.这其实对算法产生了非常大的简化
Q: Policy Gradient 如何对应到 LLM?
传统 Policy Gradient 的目标是最大化策略诱导出来的期望回报。写成 trajectory 形式,就是:
其中 \(\tau\) 是策略 \(\pi_\theta\) 采样出来的轨迹,\(G(\tau)\) 是这条轨迹上的 return。Policy Gradient 的核心是:虽然 reward 本身通常不能直接对 \(\theta\) 求导,但 trajectory 的概率依赖 \(\theta\),所以可以通过 log-probability trick 更新策略。
在 LLM 中,prompt \(x\) 可以看成初始条件,完整回答 \(y=(y_1,\ldots,y_T)\) 可以看成 trajectory。语言模型策略是:
整段回答的概率为:
于是 LLM 的优化目标可以写成:
这里 \(R(x,y)\) 是完整回答级别的奖励。它可以来自人工规则、可验证任务的结果,也可以来自 reward model:
其中 \(r_\phi\) 是由偏好数据训练出来的奖励模型。在 RLHF 的 PPO 阶段,\(r_\phi\) 通常会被冻结;它负责给当前模型生成的回答打分,但它本身不是正在更新的 policy。
更常见的 RLHF 目标还会加入 KL penalty,防止当前模型偏离参考模型太远:
这和传统 RL 的一个差异是:在很多传统环境里,reward 是环境交互的一部分;而在 LLM 的 RLHF 中,reward 往往是一个额外训练出来的模型或规则函数,对完整回答进行打分。它和 policy model \(\pi_\theta\) 通常是分开的。
这是大模型的最大的一个特点.强化传统的强化学习中,value function跟策略某种意义上是强耦合的.所以说我们一般用两个网络.或者假设action value跟策略的参数\( \theta \)并不相关.以避免求梯度时候复杂的求导问题.但是两者依然是相当耦合的.即我们还需要专门的用各种各样的算法,策略导出的轨迹中的一系列reward去估计value.这导致两者实际上还是耦合在一起的.
但是大模型中对这个进一步进行了简化.它的Reward一般是针对整个序列的.即之前文章中提到过的稀疏reward.并且这个reward可能是通过规则或者是一个reward model计算出来的.所以它确实与模型参数的,或者说策略本身完全的解耦了.
根据整段回答的 log probability:
接下来说明为什么会得到 Policy Gradient 公式。先把目标的期望展开。为了简化记号,先固定一个 prompt \(x\):
对 \(\theta\) 求梯度:
使用 log-derivative trick:
于是:
也就是:
再把 prompt \(x\sim\mathcal{D}\) 的采样也放回期望里:
最后利用自回归分解:
就得到最朴素的 LLM Policy Gradient:
如果使用 advantage,则写成:
这就是传统 Policy Gradient 到 LLM 的连接点:状态变成 prompt 加已生成前缀,动作变成下一个 token,轨迹变成完整回答,reward 来自 reward model、规则奖励或可验证结果,而 advantage 则需要额外估计。
Q: LLM 中的 advantage 怎么来?需要训练 value model 吗?
在传统 actor-critic 中,advantage 衡量的是“这个动作比当前状态下的平均水平好多少”:
在 LLM 中,状态是 \(s_t=(x,y_{<t})\),动作是 \(a_t=y_t\)。因此 token-level advantage 可以理解为:在当前 prompt 和前缀下,选择 token \(y_t\) 之后,最终回答质量比这个前缀下的平均水平好多少。
如果使用 PPO,通常需要一个 value model,也常叫 value head 或 critic。它输入当前前缀状态,输出这个前缀未来能够得到的期望 return:
这里 \(\psi\) 是 value model 的参数,\(G_t\) 是从第 \(t\) 步开始的 return。在 RLHF 中,reward 往往集中在序列末尾,例如 reward model 对完整回答给出 \(r_\phi(x,y)\)。如果再加上 token-level KL penalty,那么可以把每一步的 reward 写成近似的 shaped reward:
并在最后一步加上 reward model 的分数:
于是从第 \(t\) 步开始的 return 可以写成:
value model 的训练就像一个回归问题:让 \(V_\psi(x,y_{<t})\) 预测采样得到的 return 或 GAE target:
有了 value model 之后,最简单的 advantage 估计可以写成:
PPO 实践中常用 GAE 来估计 advantage。它先定义 TD error:
再把多个未来 TD error 做加权和:
所以答案是:如果使用 PPO 这类 actor-critic 方法,通常需要训练一个 value model 来估计 baseline / advantage。在 LLM 中,这个 value model 不是 reward model;reward model 给完整回答打分,value model 则预测“当前前缀未来大概能得到多少总奖励”。
这也是 GRPO 的一个重要动机:它希望避免单独训练 value model,而是对同一个 prompt 采样多个回答,用组内相对奖励直接构造 advantage。
Q: RLHF 到底是一种算法,还是一套流程?
RLHF 是 Reinforcement Learning from Human Feedback,意思是“从人类反馈中进行强化学习”。严格来说,RLHF 不是一个单独算法,而是一套训练流程。
经典 RLHF 通常包含三个阶段。
第一阶段是 SFT,也就是 Supervised Fine-Tuning。给定人工写好的 prompt-response 数据,继续训练预训练模型,让它学会基本的指令跟随格式。
第二阶段是训练 Reward Model。对于同一个 prompt,标注者比较两个或多个回答,指出哪个更好。然后用这些偏好数据训练一个奖励模型 \(r_\phi(x,y)\),让它能够给回答打分。
第三阶段是 RL Optimization。用当前语言模型生成回答,再用 reward model 打分,然后通过 PPO 等强化学习算法更新语言模型,使它更倾向于生成高奖励回答。
所以,RLHF 的结构可以概括为:
Pretrained LM
↓
SFT model
↓
Reward model from human preference
↓
RL optimization, often PPO
↓
Aligned model
在这个流程里,PPO 是第三阶段常用的优化算法;RLHF 是包含数据收集、奖励建模、策略优化在内的整体框架。
因此,问“RLHF 和 PPO 是什么关系”时,一个准确的回答是:
RLHF 是训练范式,PPO 是 RLHF 中常用的 policy optimization 算法。
Q: 为什么 RLHF 通常还要加 KL 惩罚?
如果只最大化 reward model 的分数,模型可能会找到 reward model 的漏洞,生成一些奖励模型喜欢但人类并不真正喜欢的回答。这种现象通常被称为 reward hacking。
此外,SFT 模型已经包含了大量语言能力和基本对齐能力。如果 RL 更新太激进,模型可能偏离原来的语言分布,导致回答质量下降。
因此,RLHF 通常不会只优化:
而是加入一个相对于参考模型 \(\pi_{\text{ref}}\) 的 KL 惩罚:
其中:
- \(\pi_\theta\) 是当前训练的策略模型。
- \(\pi_{\text{ref}}\) 是参考模型,通常是 SFT 模型的冻结副本。
- \(\beta>0\) 控制 KL 惩罚强度。
- KL 项约束当前模型不要偏离参考模型太远。
在实现中,KL 惩罚经常被写成 token-level 近似:
它的直观含义是:如果当前模型对某些 token 的概率比参考模型高很多,就要付出额外代价。这样可以让模型在追求高奖励的同时,尽量保持语言分布稳定。
Q: LLM 中 PPO 是什么?
PPO 是 Proximal Policy Optimization。它是 RLHF 中最经典的策略优化算法之一。
Policy Gradient 的朴素更新可能会让策略一步变化太大。对于 LLM 来说,这尤其危险:模型参数巨大,输出分布复杂,一次过大的更新可能导致训练不稳定。
PPO 的核心目标是:
允许策略朝着更高奖励的方向更新,但限制新策略不要离旧策略太远。
设:
- \(\pi_{\theta_{\text{old}}}\) 是采样数据时使用的旧策略。
- \(\pi_\theta\) 是当前要更新的新策略。
- \(a_t\) 是旧策略在状态 \(s_t\) 下采样到的动作。
PPO 定义概率比值:
在 LLM 中,这个式子对应:
其中:
- 如果 \(r_t(\theta)>1\),说明新策略提高了这个 token 的概率。
- 如果 \(r_t(\theta)<1\),说明新策略降低了这个 token 的概率。
朴素 policy gradient 的 surrogate objective 可以写成:
其中 \(\hat{A}_t\) 是 advantage 估计。如果 \(\hat{A}_t>0\),我们希望提高该动作概率;如果 \(\hat{A}_t<0\),我们希望降低该动作概率。
PPO 的 clipped objective 是:
其中:
- \(\epsilon\) 是裁剪范围,常见值如 0.1 或 0.2。
- \(\operatorname{clip}(r_t,1-\epsilon,1+\epsilon)\) 会把 ratio 限制在 \([1-\epsilon,1+\epsilon]\) 中。
- \(\min\) 的作用是让策略更新在“过度乐观”时被截断。
直观地说,PPO 不希望模型因为某个 batch 的 advantage 就把 token 概率改得太猛。它给 policy update 加了一个局部信任域,使训练更加稳定。
在 RLHF 中,一个典型 PPO 训练循环是:
1. 从 prompt dataset 中采样一批 prompts。
2. 用当前策略模型生成回答。
3. 用 reward model 给回答打分。
4. 加入 KL penalty,得到最终 reward。
5. 用 value model 估计 advantage,例如 GAE。
6. 用 PPO clipped objective 更新 policy model。
7. 更新 value model。
这里可以看到,PPO 本身不是奖励模型,也不是人类反馈数据。它只是拿到 reward 和 advantage 之后,负责稳定地更新策略。
Q: LLM 中 GRPO 是什么?
GRPO 是 Group Relative Policy Optimization。它可以看成一种面向大模型训练场景的 policy optimization 方法。相对于 PPO,它的一个重要特点是:不再依赖单独的 value model 来估计每个样本的 baseline,而是用同一个 prompt 下多个回答的组内相对分数来构造 advantage。
设对同一个 prompt \(x\),当前模型采样出 \(G\) 个回答:
每个回答都有一个奖励:
GRPO 的核心想法是:不要单独训练一个 value model 来预测 \(v(s)\),而是在这一组回答内部做相对比较。比如可以定义组内均值:
以及组内标准差:
然后把第 \(i\) 个回答的 advantage 估计为:
其中:
- \(r^{(i)}\) 是第 \(i\) 个回答的奖励。
- \(\bar{r}\) 是同组回答的平均奖励。
- \(\sigma_r\) 是同组奖励的标准差。
- \(\hat{A}^{(i)}\) 表示第 \(i\) 个回答相对于同组其他回答的好坏。
这样做的直觉很简单:
对同一个问题,如果某个回答比同组其他回答更好,就提高它的概率;如果它比同组平均水平更差,就降低它的概率。
GRPO 仍然可以使用类似 PPO 的 ratio 和 clipping,只是 advantage 的来源变成了 group-relative reward,而不是 value model。
用非常粗略的方式对比:
| 方法 | baseline / advantage 来源 | 是否需要 value model |
|---|---|---|
| PPO | value model / GAE | 通常需要 |
| GRPO | 同一 prompt 下多回答的组内相对奖励 | 通常不需要 |
这就是 GRPO 在大模型训练中有吸引力的原因:对于超大模型,额外训练和维护 value model 的成本很高;而组内相对奖励可以用采样换掉一部分 critic 的复杂度。
Q: DPO 是什么?
DPO 是 Direct Preference Optimization。它和 PPO、GRPO 的风格明显不同。
PPO / GRPO 仍然是比较典型的 policy optimization:模型生成回答,奖励函数或奖励模型打分,然后根据 reward / advantage 更新策略。
DPO 则试图绕开显式 reward model 和在线 RL 过程,直接用偏好数据优化语言模型。
偏好数据通常长这样:
其中:
- \(x\) 是 prompt。
- \(y_w\) 是 preferred response,也就是人类更喜欢的回答。
- \(y_l\) 是 rejected response,也就是人类不喜欢的回答。
DPO 的目标是让模型更倾向于 \(y_w\),而不是 \(y_l\)。同时,它也会相对于参考模型 \(\pi_{\text{ref}}\) 做约束,避免模型偏离太远。
常见的 DPO loss 可以写成:
其中:
- \(\sigma(\cdot)\) 是 sigmoid 函数。
- \(\beta\) 控制偏好优化强度。
- \(\pi_\theta\) 是当前训练模型。
- \(\pi_{\text{ref}}\) 是参考模型,通常是 SFT 模型。
- \(y_w\) 是 chosen / preferred response。
- \(y_l\) 是 rejected response。
这个目标的直觉是:
相对于参考模型,如果当前模型更提高 chosen response 的概率,并更降低 rejected response 的概率,那么 loss 就会变小。
DPO 和 RLHF 的关系可以这样理解:DPO 可以从带 KL 约束的 RLHF 目标推导出来,但它把“训练 reward model + 用 PPO 做 RL 优化”这两步合并成了一个直接的偏好分类式目标。
所以 DPO 的优势是训练流程更简单、更像监督学习;但它通常依赖已有的 preference pair 数据,而不是在线探索新回答。
Q: PPO、GRPO、DPO、RLHF 之间是什么关系?
可以把这几个概念放在同一张逻辑图里:
Human preference data
│
├── RLHF route
│ ├── train reward model
│ └── optimize policy with PPO / GRPO
│
└── Direct preference route
└── optimize policy with DPO
更具体地说:
| 方法 / 概念 | 它是什么 | 核心目标 |
|---|---|---|
| RLHF | 一套训练流程 | 用人类反馈构造奖励信号,再优化模型 |
| PPO | policy optimization 算法 | 在限制策略变化幅度的前提下提高奖励 |
| GRPO | policy optimization 算法 | 用组内相对奖励构造 advantage,减少对 value model 的依赖 |
| DPO | preference optimization 算法 | 直接让模型更偏向 chosen response,而不显式跑 PPO 式 RL |
它们之间不是同一层级的概念。RLHF 是流程,PPO / GRPO 是这个流程中可以使用的策略优化算法,DPO 则是另一条从偏好数据直接优化模型的路线。
如果用“目标是什么”来概括:
- PPO:我有 reward 和 advantage,如何稳定地更新 policy?
- GRPO:我能不能不用 value model,而用同组回答的相对好坏来更新 policy?
- DPO:我能不能不用显式 reward model 和在线 RL,直接从偏好对中优化 policy?
- RLHF:我如何把人类反馈转化成可以训练语言模型的信号?
Q: 这一节应该记住什么?
第一,LLM 天然就是一个 policy。它在每一步根据当前上下文输出下一个 token 的概率分布:
第二,LLM 的一次回答生成可以看成一个 episode。状态是 prompt 加已生成前缀,动作是下一个 token,轨迹是完整回答,奖励通常来自完整回答级别的偏好评价。
第三,LLM 场景更自然地走 policy-based 路线,而不是 value-based 路线。原因是状态和动作空间巨大,奖励又常常是 sequence-level 的;而预训练模型本身已经提供了一个强大的参数化策略。
第四,Policy Gradient 是理解 PPO、GRPO、RLHF 的入口。它的核心公式是:
第五,advantage 是为了判断“这个动作是否比当前状态下的平均选择更好”。GAE 是 advantage 的一种常见估计方法,通常服务于 PPO 这类 actor-critic 方法。
第六,RLHF、PPO、GRPO、DPO 不是同一层级的概念。RLHF 是训练流程,PPO 和 GRPO 是策略优化方法,DPO 是直接偏好优化方法。
MiniMind 3 升级内容
这份笔记前半部分是参考25年9月份Minimind的实现,现在26年5月MiniMind又做了一些升级,在此我们对项目中的代码也进行了相应的更新,以适配Minimind项目最新的实现.
Commit hash @9da8e1ab18ca0bbb3df9d8b5dbfbc8748810a5bf
如果用一句话概括,MiniMind 3 的升级方向大概是:
让模型结构更接近当前主流小型 LLM 的实现方式,让数据和训练接口更统一,同时让训练脚本在续训、分布式、混合精度和编译优化下更稳。
整篇文章将按照这3个角度进行梳理:
- 模型/数据的改进
- 训练流程的改进
- 工程优化,细节上的升级.
1. 模型和数据做了哪些改进
1.1 Attention 中加入 Q/K RMSNorm
新版模型在 attention 的 query 和 key 上增加了 RMSNorm。这个变化不改变 attention 的基本形式,仍然是:
其中,\(Q\) 表示 query 矩阵,\(K\) 表示 key 矩阵,\(V\) 表示 value 矩阵,\(d\) 表示每个 attention head 的维度。标准 attention 可以写成:
\[ \mathrm{Attention}(Q, K, V) = \mathrm{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V \]
但是在真正计算 RoPE 和 attention score 之前,MiniMind 3 会先对 \(Q\) 和 \(K\) 做 RMSNorm。这样做的直观意义是:让参与点积的 query/key 向量尺度更稳定,从而让 attention score 不容易因为向量范数波动过大而变得过尖或者过散。
对应代码在 src/minimind_learning/model/model_minimind.py:
class Attention(nn.Module):
def __init__(self, config: MiniMindConfig):
super().__init__()
self.num_key_value_heads = config.num_attention_heads if config.num_key_value_heads is None else config.num_key_value_heads
self.n_local_heads = config.num_attention_heads
self.n_local_kv_heads = self.num_key_value_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = config.head_dim
self.is_causal = True
# Q/K/V/O 投影矩阵。GQA 下 K/V head 数量可以少于 Q head 数量。
self.q_proj = nn.Linear(config.hidden_size, config.num_attention_heads * self.head_dim, bias=False)
self.k_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.v_proj = nn.Linear(config.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)
self.o_proj = nn.Linear(config.num_attention_heads * self.head_dim, config.hidden_size, bias=False)
# 新版 MiniMind 在 Q/K 上增加 RMSNorm,有助于稳定注意力分数。
self.q_norm = RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.k_norm = RMSNorm(self.head_dim, eps=config.rms_norm_eps)
在 forward 里,Q/K Norm 发生在 RoPE 之前:
xq, xk, xv = self.q_proj(x), self.k_proj(x), self.v_proj(x)
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xq, xk = self.q_norm(xq), self.k_norm(xk)
cos, sin = position_embeddings
xq, xk = apply_rotary_pos_emb(xq, xk, cos, sin)
这说明新版结构更重视 attention 内部的数值稳定性。对于小模型来说,这类改动通常不会显著增加参数量,但会让训练过程更稳。
1.2 RoPE 外推改成新版 YaRN 形式
RoPE 的作用是把位置信息注入到 attention 的 query/key 中。MiniMind 3 中仍然保留 RoPE,但对长上下文外推的处理更接近新版 YaRN 写法。
如果不考虑外推,RoPE 中每个维度对应的频率可以理解为:
其中,\(d\) 表示 head 维度,\(i\) 表示频率维度索引,\(\theta\) 表示 rope_theta。频率为:
\[ \omega_i = \frac{1}{\theta^{2i/d}} \]
对于位置 \(p\),旋转角度可以写成:
\[ \alpha_{p,i} = p \cdot \omega_i \]
MiniMind 3 的升级重点不在这个基础公式,而在于当目标上下文长度超过原始训练长度时,如何平滑地缩放不同频率的部分。代码里使用了一个 ramp,让低维和高维频率不是突然整体缩放,而是按区间逐步过渡。
对应代码在 src/minimind_learning/model/model_minimind.py:
if rope_scaling is not None:
orig_max, factor, beta_fast, beta_slow, attn_factor = (
rope_scaling.get("original_max_position_embeddings", 2048),
rope_scaling.get("factor", 16),
rope_scaling.get("beta_fast", 32.0),
rope_scaling.get("beta_slow", 1.0),
rope_scaling.get("attention_factor", 1.0),
)
if end / orig_max > 1.0:
# YaRN: f'(i) = f(i) * ((1 - ramp) + ramp / factor)
def inv_dim(beta):
return (dim * math.log(orig_max / (beta * 2 * math.pi))) / (2 * math.log(rope_base))
low = max(math.floor(inv_dim(beta_fast)), 0)
high = min(math.ceil(inv_dim(beta_slow)), dim // 2 - 1)
ramp = torch.clamp(
(torch.arange(dim // 2, device=freqs.device).float() - low) / max(high - low, 0.001),
0,
1,
)
freqs = freqs * (1 - ramp + ramp / factor)
这里可以把 ramp 理解成一个从 0 到 1 的平滑权重。它不是简单地把所有频率都除以同一个 factor,而是让不同频段有不同程度的缩放。这样做的目的,是在扩展上下文长度时,尽量减少位置编码分布和原训练分布之间的突变。
1.3 引入 MoE FeedForward
旧版学习实现里虽然有 use_moe 配置,但模型主体中实际上不支持 MoE。MiniMind 3 中,FFN 可以从普通 dense FFN 切换成 MoE FFN。
普通 FFN 是所有 token 都走同一套参数:
class FeedForward(nn.Module):
def __init__(self, config: MiniMindConfig, intermediate_size: int = None):
super().__init__()
intermediate_size = intermediate_size or config.intermediate_size
self.gate_proj = nn.Linear(config.hidden_size, intermediate_size, bias=False)
self.up_proj = nn.Linear(config.hidden_size, intermediate_size, bias=False)
self.down_proj = nn.Linear(intermediate_size, config.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x: torch.Tensor):
middle = self.act_fn(self.gate_proj(x)) * self.up_proj(x)
return self.down_proj(middle)
MoE FFN 则多了一层 router。router 会给每个 token 分配专家权重,然后只激活 top-k 个 expert:
scores = F.softmax(self.gate(x_flat), dim=-1)
topk_weight, topk_idx = torch.topk(scores, k=self.config.num_experts_per_tok, dim=-1, sorted=False)
if self.config.norm_topk_prob:
topk_weight = topk_weight / (topk_weight.sum(dim=-1, keepdim=True) + 1e-20)
y = torch.zeros_like(x_flat)
for i, expert in enumerate(self.experts):
mask = topk_idx == i
if mask.any():
token_idx = mask.any(dim=-1).nonzero().flatten()
weight = topk_weight[mask].view(-1, 1)
y.index_add_(0, token_idx, (expert(x_flat[token_idx]) * weight).to(y.dtype))
从结构上看,MoE 的核心思想是:总参数量可以变大,但每个 token 实际激活的参数量不一定同步变大。比如有 4 个 expert,每个 token 只选择 1 个 expert,那么模型拥有更多“容量”,但单个 token 的计算路径仍然比较稀疏。
MoE 还有一个重要问题:如果 router 总是偏向某几个 expert,其他 expert 学不到东西。所以训练时会加入 router auxiliary loss:
if self.training and self.config.router_aux_loss_coef > 0:
load = F.one_hot(topk_idx, self.config.num_experts).float().mean(0)
self.aux_loss = (load * scores.mean(0)).sum() * self.config.num_experts * self.config.router_aux_loss_coef
else:
self.aux_loss = scores.new_zeros(1).squeeze()
这部分 loss 的作用不是直接预测下一个 token,而是约束 router 不要过度集中到少数 expert 上。
1.4 模型 forward 直接支持 labels
旧版训练代码中,Dataset 返回 (X, Y, loss_mask),训练脚本手动计算交叉熵:
loss = loss_fct(
# B batch size, L sequence length, V vocab size
# [B,L,V] -> [B*L,V]
res.logits.view(-1, res.logits.size(-1)),
Y.view(-1)
).view(Y.size())
loss = (loss * loss_mask).sum() / loss_mask.sum()
MiniMind 3 更接近 HuggingFace 模型的接口习惯:Dataset 返回 input_ids 和 labels,模型内部完成 shift 和 ignore_index=-100 的 loss 计算。
对应代码在 src/minimind_learning/model/model_minimind.py:
loss = None
if labels is not None:
# shifted LM loss
# B batch size, L sequence length, V vocab size
# logits : [B,L,V] -> [B,L-1,V]
# labels: [B,L] -> [B,L-1]
x = logits[..., :-1, :].contiguous()
y = labels[..., 1:].contiguous()
loss = F.cross_entropy(x.view(-1, x.size(-1)), y.view(-1), ignore_index=-100)
这个变化看起来只是接口变化,但实际影响很大:pretrain、SFT、DPO 都可以围绕同一种模型输出结构来组织,训练脚本不再需要各自手写一套语言模型 loss。
1.5 数据格式从 loss_mask 转向 labels
对应地,数据集也从显式返回 loss_mask,转向直接构造 labels。
以 SFT 为例,用户问题、system prompt、工具描述等位置都不应该参与 loss;只有 assistant 回复部分参与训练。新版实现里,这些“不训练的位置”直接写成 -100:
def generate_labels(self, input_ids: list):
"""
仅 assistant 回复部分参与 loss 计算;其他位置设置为 -100。
labels 和 input_ids 同长度,shift 由模型内部完成。
"""
labels = [-100] * len(input_ids)
i = 0
while i < len(input_ids):
if input_ids[i : i + len(self.bos_id)] == self.bos_id:
start = i + len(self.bos_id)
end = start
while end < len(input_ids):
if input_ids[end : end + len(self.eos_id)] == self.eos_id:
break
end += 1
for j in range(start, min(end + len(self.eos_id), self.max_length)):
labels[j] = input_ids[j]
i = end + len(self.eos_id) if end < len(input_ids) else len(input_ids)
else:
i += 1
return labels
这样做的好处是,mask 逻辑被压缩到数据构造阶段。训练阶段只需要把 input_ids 和 labels 交给模型:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
从学习角度看,这也更容易建立统一心智模型:labels == -100 的位置不参与语言模型 loss,其他位置正常预测下一个 token。
2. 训练部分引入了哪些改进
2.1 Pretrain 和 SFT 训练接口统一
新版 pretrain 和 full SFT 的训练循环非常接近,核心都是:
for step, (input_ids, labels) in enumerate(loader, start=start_step + 1):
input_ids = input_ids.to(args.device)
labels = labels.to(args.device)
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
loss = loss / args.accumulation_steps
这说明 pretrain 和 SFT 在训练代码层面的差异被压缩了。它们真正的区别主要转移到了数据构造上:
- pretrain 数据:几乎所有非 pad token 都参与预测。
- SFT 数据:只有 assistant 回复部分参与预测。
这是一种更清晰的分层:模型只关心 input_ids/labels,训练循环只关心反向传播和优化器更新,任务差异由 Dataset 负责。
2.2 DPO loss 口径调整
DPO 的目标是让策略模型相对于参考模型,更偏好 chosen 而不是 rejected。
其中,\(\pi_\theta\) 表示当前训练的策略模型,\(\pi_\mathrm{ref}\) 表示冻结的参考模型,\(y_w\) 表示 chosen response,\(y_l\) 表示 rejected response,\(x\) 表示 prompt,\(\beta\) 是控制偏好强度的超参数。DPO loss 可以写成:
代码实现里,先对每个 token 的 log probability 按 mask 聚合:
def dpo_loss(ref_log_probs, policy_log_probs, mask, beta):
"""
ref_log_probs 和 policy_log_probs 都是 shape: (batch_size, seq_len)。
batch 前半部分为 chosen,后半部分为 rejected。
"""
ref_log_probs = (ref_log_probs * mask).sum(dim=1)
policy_log_probs = (policy_log_probs * mask).sum(dim=1)
batch_size = ref_log_probs.shape[0]
chosen_ref_log_probs = ref_log_probs[: batch_size // 2]
reject_ref_log_probs = ref_log_probs[batch_size // 2 :]
chosen_policy_log_probs = policy_log_probs[: batch_size // 2]
reject_policy_log_probs = policy_log_probs[batch_size // 2 :]
# log-ratio 比较:策略模型 vs 参考模型。
pi_logratios = chosen_policy_log_probs - reject_policy_log_probs
ref_logratios = chosen_ref_log_probs - reject_ref_log_probs
logits = pi_logratios - ref_logratios
loss = -F.logsigmoid(beta * logits)
return loss.mean()
这个版本更贴近 DPO 公式本身:比较的是 response 整体的 log probability 差异,而不是每个样本平均 token log probability 之后再比较。
2.3 MoE auxiliary loss 进入训练目标
因为模型可能启用 MoE,所以训练 loss 不再只有语言模型 loss 或 DPO loss,还要加上 aux_loss:
with autocast_ctx:
res = model(input_ids, labels=labels)
loss = res.loss + res.aux_loss
loss = loss / args.accumulation_steps
DPO 中也是一样:
dpo_loss_val = dpo_loss(ref_log_probs, policy_log_probs, mask, beta=beta)
loss = dpo_loss_val + outputs.aux_loss
loss = loss / args.accumulation_steps
如果不开 MoE,aux_loss 基本就是 0,不影响普通 dense 模型。这样训练脚本可以同时兼容 dense 和 MoE,不需要为 MoE 单独写一套训练流程。
2.4 梯度累积处理更完整
梯度累积的目的是用多个小 batch 模拟一个更大的 batch。核心逻辑是:每个小 batch 都 backward,但不是每次都 optimizer.step()。
新版训练脚本除了正常的 accumulation step,还补上了 epoch 末尾“不足一个累积窗口”的情况:
if last_step > start_step and last_step % args.accumulation_steps != 0:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.grad_clip)
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad(set_to_none=True)
这个细节的意义是:如果一个 epoch 的 batch 数不能被 accumulation_steps 整除,最后剩下的梯度也不会被浪费掉。
2.5 增加 torch.compile 入口
训练脚本新增了 --use_compile,可以选择性启用 PyTorch 2.x 的 torch.compile:
if args.use_compile == 1:
model = torch.compile(model)
Logger("torch.compile enabled")
这属于训练性能优化,不改变模型数学含义。它的作用是让 PyTorch 尝试对模型计算图进行编译优化,在某些环境下可以提升吞吐。不过它也可能增加首次编译开销,所以做实验时最好把它作为一个显式开关,而不是默认强制开启。
3. 工程上做了哪些优化
3.1 checkpoint 保存更稳
MiniMind 3 对 checkpoint 保存做了更稳的处理,尤其是兼容 DDP 和 torch.compile。
在 DDP 下,真正的模型包在 model.module 里;在 torch.compile 之后,原始模型可能包在 _orig_mod 里。如果保存时不 unwrap,可能会保存到包装器状态,或者出现权重 key 不符合预期的问题。
现在统一通过 unwrap_model 取原始模型:
def unwrap_model(model):
raw_model = model.module if isinstance(model, DistributedDataParallel) else model
return getattr(raw_model, "_orig_mod", raw_model)
保存权重时也会转成 half 并放到 CPU:
raw_model = unwrap_model(model)
state_dict = raw_model.state_dict()
state_dict = {k: v.half().cpu() for k, v in state_dict.items()}
ckp_tmp = ckp_path + ".tmp"
torch.save(state_dict, ckp_tmp)
os.replace(ckp_tmp, ckp_path)
这里有两个工程意义:
half().cpu()可以减少保存文件大小,也减少保存 checkpoint 时的显存压力。- 先保存到
.tmp,再用os.replace替换正式文件,可以降低写 checkpoint 中途失败导致文件损坏的风险。
3.2 resume 对 world size 变化更友好
分布式训练中,续训时 GPU 数量可能和上次不一样。比如上次 2 张卡,这次 1 张卡,如果直接用旧 step,跳过 batch 的数量可能不一致。
因此 checkpoint 加载时会记录并比较 world size:
saved_ws = ckp_data.get("world_size", 1)
current_ws = dist.get_world_size() if dist.is_initialized() else 1
if saved_ws != current_ws:
ckp_data["step"] = ckp_data["step"] * saved_ws // current_ws
Logger(f'GPU数量变化({saved_ws}->{current_ws}),step已自动转换为{ckp_data["step"]}')
这不是严格意义上的训练算法改进,但对实际训练很重要。因为真实实验里,经常会遇到中途换机器、换卡数、恢复训练的情况。
3.3 模型命名统一为 MiniMindModel
这次 src 中的模型主干命名也做了整理。旧实现里主干模型叫 MiniMind_Dense,容易让人误以为它只能表示 dense 版本。但新版模型已经可以根据配置切换 dense FFN 或 MoE FFN,因此更合适的名字是 MiniMindModel。
现在结构是:
class MiniMindModel(torch.nn.Module):
"""
MiniMind 主干模型:Embedding -> Transformer Blocks -> RMSNorm。
"""
...
class MiniMindForCausalLM(PreTrainedModel, GenerationMixin):
config_class = MiniMindConfig
def __init__(self, config: MiniMindConfig = None):
self.config = config or MiniMindConfig()
super().__init__(self.config)
self.model = MiniMindModel(self.config)
self.lm_head = nn.Linear(self.config.hidden_size, self.config.vocab_size, bias=False)
这个命名更符合常见 HuggingFace 风格:
MiniMindModel表示 backbone。MiniMindForCausalLM表示在 backbone 上加了lm_head的语言模型。
为了避免旧笔记或旧代码引用断掉,代码中暂时保留了一个兼容别名:
# 兼容旧笔记/旧代码中的命名。新代码请使用 MiniMindModel。
MiniMind_Dense = MiniMindModel
3.4 参数统计区分总参数和激活参数
MoE 模型有一个很容易误解的地方:总参数量和每个 token 实际激活的参数量不是一回事。
新版工具函数中增加了参数统计逻辑:
def get_model_params(model, config):
total = sum(p.numel() for p in model.parameters()) / 1e6
n_routed = getattr(config, "num_experts", 0)
n_active = getattr(config, "num_experts_per_tok", 0)
expert = sum(p.numel() for n, p in model.named_parameters() if "mlp.experts.0." in n) / 1e6
base = total - expert * n_routed
active = base + expert * n_active
if active < total:
Logger(f"Model Params: {total:.2f}M-A{active:.2f}M")
else:
Logger(f"Model Params: {total:.2f}M")
这里的 total 是模型拥有的总参数量,active 是一个 token 前向传播时大致会激活的参数量。对于 MoE 模型来说,这两个数字都值得看:
- 总参数量反映模型容量。
- 激活参数量更接近单 token 的计算成本。
4. 小结
MiniMind 3 的升级可以理解为三条线同时推进。
第一条线是模型结构升级:Q/K RMSNorm、YaRN RoPE、MoE FFN,让模型更接近当前小型 LLM 的常见实现。
第二条线是训练接口升级:把 labels 交给模型内部计算 loss,pretrain/SFT/DPO 的训练循环因此更统一;MoE 的 auxiliary loss 也自然进入总训练目标。
第三条线是工程稳定性升级:checkpoint unwrap、CPU 半精度保存、resume world size 处理、torch.compile 开关和参数统计,都让这个项目更像一个可以反复实验的训练框架,而不只是一个最小 demo。
从学习角度看,这次升级最值得关注的不是某一个参数默认值变了,而是代码组织方式的变化:模型、数据、训练、保存这几层之间的边界更清晰了。
PyTorch Cookbook
这篇笔记主要整理我在学习 LLM 和阅读训练代码时经常会碰到的 PyTorch 张量操作。目标不是写成一份完整文档,而是把那些最常用、最容易混淆、最需要建立直觉的内容整理出来,方便后面反复查。
1. PyTorch 张量基础
1.1 张量的维度和常见 shape
在 PyTorch 里,最先要建立的直觉就是:很多操作本质上都和 shape 有关。
同一个算子,一旦输入张量的维度理解错了,后面的广播、拼接、索引、矩阵乘法都会跟着错。
一些常见模型里的张量 shape:
| 模型 | 常见 shape | 含义 |
|---|---|---|
| MLP | (batch_size, feature_dim) | 最后一个维度通常是特征维度 |
| RNN / LSTM | (batch_size, seq_len, dim) | 每个时间步对应一个 embedding |
| Transformer | (batch_size, seq_len, dim) | 每个 token 对应一个 embedding |
| CNN | (batch_size, channels, H, W) | 最后两个维度通常是空间维度 |
在 LLM 代码里,经常会看到下面这种张量:
x.shape == (batch_size, seq_len, hidden_dim)
这里:
batch_size表示一批样本的数量。seq_len表示序列长度,也就是 token 个数。hidden_dim表示每个 token 对应的隐藏向量维度。
很多层默认都是“最后一个维度是特征维度”这个思路在工作,比如 LayerNorm、线性层前后的很多广播操作。
1.2 索引机制
PyTorch 的索引方式和 NumPy 很接近。最常见的是切片、整数索引和维度插入。
import torch
x = torch.randn(2, 3, 4)
x[0].shape # (3, 4)
x[:, 1].shape # (2, 4)
x[:, :, 0].shape # (2, 3)
可以把它理解成:每写一个索引,就是在对应维度上做一次选择。
1.3 None 和 ...
None 是 Python 的语法糖,用于在当前位置插入一个长度为 1 的新维度,效果等价于 unsqueeze()。
x = torch.randn(2, 3, 4, 5)
y = x[:, :, :, None, :]
z = x.unsqueeze(3)
print(y.shape) # (2, 3, 4, 1, 5)
print(z.shape) # (2, 3, 4, 1, 5)
所以:
x[:, :, :, None, :] == x.unsqueeze(3)
... 表示“中间剩下的维度全部保留”,在高维张量里很好用:
x[..., 0] # 取最后一个维度上的第 0 个元素
x[..., None] # 在最后面插入一个新维度
1.4 广播机制
广播机制是 PyTorch 里最重要的基础概念之一。几乎所有逐元素运算,比如加法、减法、乘法、除法,都支持广播。
例如:
self.weight * normalized_x
如果:
self.weight.shape == (d,)
normalized_x.shape == (batch_size, ..., d)
那么结果 shape 为:
(batch_size, ..., d)
原因是广播会从最后一个维度开始对齐。
广播规则可以简化为:
- 从最后一个维度开始对齐,也就是右对齐。
- 如果两个维度相等,或者其中一个维度是
1,就可以广播。 - 如果两个维度既不相等,也都不是
1,就会报错。
例如:
[m, n] * [n]
[l, m, n] * [n]
[l, m, n] * [m, n]
[l, m, n] * [m, 1]
[l, m, n] * [1, m, 1]
一个比较有用的理解方式是:把没有出现的维度当成自动补了一个 1,然后从右往左匹配。
和 1 对应的那个维度,可以理解成“这一维要被复制展开”。
需要注意的是:
- 广播不会真的复制数据。
- 它只是逻辑上把 shape 扩展到可以逐元素运算的形式。
- 所以广播通常很省内存。
1.5 连续内存、stride 和 contiguous
PyTorch 里的张量不只是 shape,还有内存布局问题。
连续张量可以粗略理解为:它在内存中的排布是按当前 shape 顺序紧密存储的,没有跳着访问,也没有重复引用。
判断一个张量是否连续:
x.is_contiguous()
有些操作会返回非连续张量,比如:
transposepermuteexpand
这些操作很多时候并不会真的复制数据,而只是修改张量的“视图解释方式”。这时就会涉及 stride。
stride 可以理解成:在某个维度上移动一步时,底层内存地址要跳多少。
x.stride()
如果你只是想先建立直觉,可以先记住一句话:
shape决定“怎么看这个张量”。stride决定“按这个看法去访问内存时怎么跳”。
这也是为什么有些张量虽然 shape 看起来没问题,但不能直接 view()。
如果需要查看底层存储大小,可以用:
x.untyped_storage().size()
2. 形状变换与维度操作
2.1 unsqueeze() 和 squeeze()
torch.unsqueeze(dim) 用于在指定位置插入一个长度为 1 的维度。
x = torch.tensor([1, 2, 3]) # shape: [3]
print(x.unsqueeze(0).shape) # [1, 3]
print(x.unsqueeze(1).shape) # [3, 1]
squeeze() 用于去掉长度为 1 的维度。
x = torch.randn(1, 3, 1, 4)
print(x.squeeze().shape) # [3, 4]
print(x.squeeze(0).shape) # [3, 1, 4]
print(x.squeeze(2).shape) # [1, 3, 4]
这两个函数在对齐 shape、准备广播、给 matmul 或 gather 喂输入时非常常见。
numpy: expand_dims() / squeeze()
import numpy as np
x = np.array([1, 2, 3])
print(np.expand_dims(x, axis=0).shape) # (1, 3)
print(np.expand_dims(x, axis=1).shape) # (3, 1)
y = np.random.randn(1, 3, 1, 4)
print(np.squeeze(y).shape) # (3, 4)
print(np.squeeze(y, axis=0).shape) # (3, 1, 4)
2.2 view() vs reshape()
这两个函数都可以改 shape,但区别非常重要。
| 特性 | view() | reshape() |
|---|---|---|
| 是否要求连续内存 | 是,必须是 contiguous tensor | 否,不连续时会自动处理 |
| 是否可能复制数据 | 不会,只返回 view | 可能复制数据 |
| 失败行为 | 张量不连续时直接报错 | 通常会自动返回可用结果 |
例子:
x = torch.arange(12)
y = x.view(3, 4)
z = x.reshape(3, 4)
如果张量经过了 transpose() 或 permute(),这时往往不能直接 view(),需要先:
x = x.contiguous().view(...)
或者直接:
x = x.reshape(...)
经验上可以这么记:
- 你明确知道张量是连续的,并且想要“只改视图不复制数据”,可以用
view()。 - 如果只是想安全地改 shape,通常
reshape()更省心。
numpy: reshape()
import numpy as np
x = np.arange(12)
y = x.reshape(3, 4)
print(y.shape) # (3, 4)
2.3 transpose()、permute() 和 contiguous()
transpose(dim0, dim1) 用于交换两个维度。
x = torch.randn(2, 3, 4)
print(x.transpose(1, 2).shape) # (2, 4, 3)
permute() 更一般,可以一次性重排多个维度。
x = torch.randn(2, 3, 4)
print(x.permute(2, 0, 1).shape) # (4, 2, 3)
在 Transformer 代码里,permute() 和 transpose() 很常见,比如把张量从:
(batch_size, seq_len, num_heads, head_dim)
改成:
(batch_size, num_heads, seq_len, head_dim)
很多时候这些操作只会修改视图,不会复制数据,因此结果张量常常不是连续的。
这时如果后面要 view(),通常需要先调用:
x = x.contiguous()
numpy: transpose()
import numpy as np
x = np.random.randn(2, 3, 4)
print(np.swapaxes(x, 1, 2).shape) # (2, 4, 3)
print(np.transpose(x, (2, 0, 1)).shape) # (4, 2, 3)
2.4 expand() vs repeat() vs repeat_interleave()
这几个函数经常一起混。
expand():广播视图,不复制数据
expand() 返回的是一个广播视图。它不会真的复制数据,所以很省内存,但只能扩展原来 size 为 1 的维度。
x = torch.tensor([[1, 2]])
x_expand = x.expand(3, 2)
print(x_expand.shape) # (3, 2)
这里看起来像是把第一维复制成了 3 份,但实际上底层数据并没有复制。
repeat():真实复制数据
repeat() 会真的复制内容,生成一个新的张量。
x = torch.tensor([[1, 2]])
x_repeat = x.repeat(2, 3)
print(x_repeat.shape) # (2, 6)
repeat_interleave():逐元素重复
如果你想重复的是“元素”而不是整个维度块,可以用 repeat_interleave()。
x = torch.tensor([1, 2, 3])
print(torch.repeat_interleave(x, repeats=2))
# tensor([1, 1, 2, 2, 3, 3])
总结如下:
| 函数 | 是否复制数据 | 是否节省内存 | 是否支持任意维度扩展 | 典型用途 |
|---|---|---|---|---|
repeat | 是 | 否 | 是 | 需要真实复制数据 |
expand | 否 | 是 | 否,只能扩展 size 为 1 的维度 | 做广播视图 |
repeat_interleave | 是 | 否 | 元素级重复 | 扩展标签、索引、位置等 |
还要注意一点:expand() 得到的张量常常不是标准连续内存布局,所以后面如果继续 view() 或某些依赖连续内存的操作,需要格外小心。
numpy: broadcast_to() / tile() / repeat()
import numpy as np
x = np.array([[1, 2]])
print(np.broadcast_to(x, (3, 2)).shape) # (3, 2)
print(np.tile(x, (2, 3)).shape) # (2, 6)
print(np.repeat(np.array([1, 2, 3]), 2))
# [1 1 2 2 3 3]
2.5 flatten()
flatten() 用于把若干连续维度压平成一个维度。
x = torch.randn(2, 3, 4)
print(x.flatten().shape) # (24,)
print(x.flatten(1).shape) # (2, 12)
print(x.flatten(0, 1).shape) # (6, 4)
这在把多维特征送进线性层、或者把批量维和时间维合并时很常见。
numpy: reshape() / ravel()
import numpy as np
x = np.random.randn(2, 3, 4)
print(x.reshape(-1).shape) # (24,)
print(x.reshape(2, -1).shape) # (2, 12)
print(x.reshape(6, 4).shape) # (6, 4)
3. 张量拼接与组合
3.1 torch.cat()
torch.cat([tensor1, tensor2, ...], dim=0) 用于在已有维度上拼接张量。
特点:
- 按指定维度进行拼接。
- 除了拼接的那个维度之外,其他维度必须完全一致。
torch.cat()本身不支持广播。
例子:
x = torch.randn([2, 3, 4])
y = torch.randn([2, 3, 3])
print(torch.cat([x, x]).shape)
print(torch.cat([x, x], dim=1).shape)
print(torch.cat([x, y], dim=-1).shape)
输出:
torch.Size([4, 3, 4])
torch.Size([2, 6, 4])
torch.Size([2, 3, 7])
numpy: concatenate()
import numpy as np
x = np.random.randn(2, 3, 4)
y = np.random.randn(2, 3, 3)
print(np.concatenate([x, x], axis=0).shape) # (4, 3, 4)
print(np.concatenate([x, x], axis=1).shape) # (2, 6, 4)
print(np.concatenate([x, y], axis=-1).shape) # (2, 3, 7)
3.2 torch.stack()
torch.stack([tensor1, tensor2, ...], dim=0) 会先插入一个新维度,再把多个张量沿这个新维度叠起来。
特点:
- 所有输入张量的 shape 必须完全一致。
- 结果比原张量多一个维度。
dim表示新维度插入的位置。
例如:
x = torch.randn(2, 3)
y = torch.randn(2, 3)
print(torch.stack([x, y], dim=0).shape) # (2, 2, 3)
print(torch.stack([x, y], dim=1).shape) # (2, 2, 3)
虽然 shape 都是 (2, 2, 3),但维度语义不同。
可以粗略理解成:
cat是在原有轴上接起来。stack是新增一个轴,把多个张量摞起来。
numpy: stack()
import numpy as np
x = np.random.randn(2, 3)
y = np.random.randn(2, 3)
print(np.stack([x, y], axis=0).shape) # (2, 2, 3)
print(np.stack([x, y], axis=1).shape) # (2, 2, 3)
3.3 torch.hstack() 和 torch.vstack()
这两个函数本质上可以理解成 cat() 的语法糖。
| 函数 | 本质操作 | 默认拼接维度 | 适用场景 |
|---|---|---|---|
torch.cat() | 通用拼接函数 | 手动指定 dim | 最灵活 |
torch.hstack() | 水平拼接 | 最后一维 | 类似 NumPy 的 hstack |
torch.vstack() | 垂直拼接 | 第 0 维 | 类似 NumPy 的 vstack |
需要注意:
- 它们只适用于维度大于等于 1 的张量。
- 对一维张量来说,
hstack和vstack的行为不完全一样。 vstack往往会先把一维张量视为行向量再拼接。
numpy: hstack() / vstack()
import numpy as np
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
print(np.hstack([x, y])) # [1 2 3 4 5 6]
print(np.vstack([x, y]).shape) # (2, 3)
3.4 torch.outer()
torch.outer(a, b) 要求输入都是一维张量。
如果:
a.shape == (m,)
b.shape == (n,)
那么:
torch.outer(a, b).shape == (m, n)
本质上就是把两个向量做外积,每一对元素都相乘一次。
numpy: outer()
import numpy as np
a = np.array([1, 2])
b = np.array([3, 4, 5])
print(np.outer(a, b))
# [[ 3 4 5]
# [ 6 8 10]]
4. 索引、选择与收集
4.1 基础切片和布尔索引
基础切片前面已经讲过。另一个很常用的是布尔索引。
x = torch.tensor([1, 2, 3, 4, 5])
mask = x > 2
print(mask) # tensor([False, False, True, True, True])
print(x[mask]) # tensor([3, 4, 5])
这在筛选 loss、过滤 padding、提取满足条件的位置时很常见。
numpy: 布尔索引
import numpy as np
x = np.array([1, 2, 3, 4, 5])
mask = x > 2
print(mask) # [False False True True True]
print(x[mask]) # [3 4 5]
4.2 torch.gather()
torch.gather(input, dim, index) 是 LLM 代码里非常常见的函数,尤其是在:
- 按 token 位置取值
- 从 logits 中取出目标 token 对应分数
- 根据索引收集某一维上的元素
它的参数含义:
input:原始张量。dim:沿着哪一个维度取值。index:要取哪些位置。
形状规则:
index.shape必须和input.shape在除了dim之外的维度上保持一致。- 在
dim这个维度上,index.size(dim)可以和input.size(dim)不同。 - 输出的 shape 就等于
index.shape。
例子:
input = torch.tensor([
[10, 20, 30],
[40, 50, 60]
]) # shape: [2, 3]
index = torch.tensor([
[2, 1, 0],
[0, 1, 2]
]) # shape: [2, 3]
out = torch.gather(input, dim=1, index=index)
print(out)
输出:
tensor([
[30, 20, 10],
[40, 50, 60]
])
如果你把它放到 LLM 场景里,可以把 input 理解成 logits,把 index 理解成目标 token id,就比较容易理解为什么它这么常用。
numpy: take_along_axis()
import numpy as np
input = np.array([
[10, 20, 30],
[40, 50, 60]
])
index = np.array([
[2, 1, 0],
[0, 1, 2]
])
out = np.take_along_axis(input, index, axis=1)
print(out)
# [[30 20 10]
# [40 50 60]]
4.3 index_select()
index_select() 也是按索引取值,但它比 gather() 更简单,适合“在某个维度上统一选几列/几行”的场景。
x = torch.tensor([
[10, 20, 30],
[40, 50, 60]
])
index = torch.tensor([0, 2])
out = torch.index_select(x, dim=1, index=index)
print(out)
输出:
tensor([
[10, 30],
[40, 60]
])
可以简单记成:
gather()更灵活,适合“每个位置取的索引都可能不同”。index_select()更适合“整行整列统一挑选”。
numpy: take()
import numpy as np
x = np.array([
[10, 20, 30],
[40, 50, 60]
])
index = np.array([0, 2])
out = np.take(x, index, axis=1)
print(out)
# [[10 30]
# [40 60]]
5. 常用 API 速查
这一节不打算写成完整手册,只整理一些在模型代码里最常见的 API。
5.1 查看张量属性
x.shape
x.size()
x.dim()
x.dtype
x.device
x.stride()
x.is_contiguous()
5.2 常见创建函数
torch.zeros(2, 3)
torch.ones(2, 3)
torch.arange(10)
torch.randn(2, 3)
torch.tensor([1, 2, 3])
torch.zeros_like(x)
torch.ones_like(x)
torch.randn_like(x)
5.3 常见形状操作
x.unsqueeze(dim)
x.squeeze(dim)
x.view(...)
x.reshape(...)
x.flatten(...)
x.transpose(dim0, dim1)
x.permute(...)
x.contiguous()
5.4 常见拼接操作
torch.cat([...], dim=...)
torch.stack([...], dim=...)
torch.hstack([...])
torch.vstack([...])
torch.outer(a, b)
5.5 常见归约操作
x.sum(dim=...)
x.mean(dim=...)
x.max(dim=...)
x.argmax(dim=...)
这里需要注意:
sum、mean、max这类操作往往会让某个维度消失。- 如果后面还要保留这个维度参与广播,可以用
keepdim=True。
例如:
x = torch.randn(2, 3, 4)
y = x.mean(dim=-1, keepdim=True)
print(y.shape) # (2, 3, 1)
5.6 常见逐元素运算
x + y
x - y
x * y
x / y
torch.exp(x)
torch.log(x)
torch.sqrt(x)
torch.clamp(x, min=0.0)
这类操作通常都支持广播。
5.7 matmul / bmm / einsum
这几个函数在 Transformer 和注意力代码里非常常见。它们本质上都和“乘法 + 某些维度上的求和”有关,但抽象层级不一样。
torch.matmul()
matmul() 是最通用的矩阵乘法接口。它会根据输入维度自动选择行为:
- 两个一维张量:做点积
- 两个二维张量:做标准矩阵乘法
- 高维张量:把前面的维度当作 batch 维,最后两维做矩阵乘法
例如:
x = torch.randn(2, 3)
y = torch.randn(3, 4)
z = torch.matmul(x, y)
print(z.shape) # (2, 4)
在高维情况下:
q = torch.randn(8, 16, 128, 64)
k = torch.randn(8, 16, 64, 128)
scores = torch.matmul(q, k)
print(scores.shape) # (8, 16, 128, 128)
这里前两维 (8, 16) 可以看作 batch 维,最后两维做矩阵乘法。这正是多头注意力里非常典型的写法。
torch.bmm()
bmm() 是 batched matrix multiplication,只支持三维张量。
如果:
x.shape == (b, m, n)
y.shape == (b, n, p)
那么:
torch.bmm(x, y).shape == (b, m, p)
例子:
x = torch.randn(32, 128, 64)
y = torch.randn(32, 64, 128)
z = torch.bmm(x, y)
print(z.shape) # (32, 128, 128)
可以把它理解成:对 batch 中的每一对矩阵分别做一次普通矩阵乘法。
经验上:
- 如果你想写通用代码,通常
matmul()更常用。 - 如果你明确知道自己处理的是三维 batch 矩阵,
bmm()语义更直接。
torch.einsum()
einsum() 更像是一种“张量计算记号”,它允许你直接描述每个维度之间如何对应、如何求和。
例如矩阵乘法:
x = torch.randn(2, 3)
y = torch.randn(3, 4)
z = torch.einsum("ik,kj->ij", x, y)
这里:
i表示x的第 0 维k表示被求和掉的中间维j表示y的第 1 维
在注意力里,一个常见写法是:
scores = torch.einsum("bhqd,bhkd->bhqk", q, k)
符号说明:
b:batch sizeh:num_headsq:query lengthk:key lengthd:head_dim
这里的意思是:在 d 这个维度上做乘法并求和,输出 (b, h, q, k),也就是 attention score。
einsum() 的优点是表达力很强,读维度关系很直接;缺点是刚开始不熟的时候容易写错。
可以先记住它的使用场景:
- 维度很多,
permute()+matmul()写起来不直观 - 想直接把“哪个维度保留,哪个维度求和”写清楚
5.8 Transformer 里常见的几个操作
softmax()
softmax() 通常用于把一组分数归一化成概率分布。
如果输入为向量 $x = (x_1, x_2, \dots, x_n)$,其中 $x_i$ 表示第 $i$ 个位置的原始分数,那么 softmax 定义为:
$$ \mathrm{softmax}(x_i) = \frac{e^{x_i}}{\sum_{j=1}^n e^{x_j}} $$
在 PyTorch 里经常写成:
probs = torch.softmax(logits, dim=-1)
dim=-1 表示在最后一个维度上做归一化。在 LLM 里,这通常意味着:
- 对词表维度做 softmax,得到下一个 token 的概率
- 对 attention score 的 key 维度做 softmax,得到注意力权重
masked_fill()
masked_fill() 很适合和 mask 一起使用。它的含义是:把 mask 为真的那些位置,用某个值填掉。
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
mask = torch.tensor([[False, True], [False, False]])
print(x.masked_fill(mask, float("-inf")))
输出:
tensor([[1., -inf],
[3., 4.]])
在 attention 里,一个非常常见的写法是:
scores = scores.masked_fill(mask == 0, float("-inf"))
attn = torch.softmax(scores, dim=-1)
原因是 softmax 之后:
-inf对应的位置概率会变成 0- 这样就能把 padding token 或未来位置屏蔽掉
torch.where()
torch.where(condition, a, b) 可以理解成逐元素版的 if-else。
x = torch.tensor([1, 2, 3, 4])
y = torch.where(x > 2, x, torch.zeros_like(x))
print(y) # tensor([0, 0, 3, 4])
它在这些场景里经常出现:
- 根据条件选择不同值
- 构造 mask 后做条件替换
- 避免直接写 Python 循环
和 masked_fill() 相比:
masked_fill()更适合“把某些位置统一替换成同一个值”where()更适合“满足条件时选 a,否则选 b”
6. PyTorch 与深度学习模型实现
前面更多是在整理“张量怎么操作”,这一节开始整理“模型代码到底是怎么组织起来的”。
读训练代码的时候,经常会同时看到下面这些概念:
nn.Parameterbufferrequires_gradgradnn.Modulestate_dict()
它们之间其实是有关联的。可以先用下面这个角度整体理解:
| 概念 | 是什么 | 会不会被优化器更新 | 会不会跟着模型一起搬到 GPU | 会不会进入 state_dict() |
|---|---|---|---|---|
普通 Tensor | 只是一个普通张量属性 | 默认不会 | 默认不会自动跟随 | 默认不会 |
nn.Parameter | 被注册为模型参数的张量 | 会,如果 requires_grad=True | 会 | 会 |
| buffer | 被注册为模型状态的张量,但不是参数 | 不会 | 会 | 默认会,除非 persistent=False |
grad | 参数在反向传播后得到的梯度 | 不是参数本身 | 跟着对应参数走 | 不单独保存 |
很多看起来“都是挂在 module 上的 tensor”,但语义完全不同:
- 如果它是需要训练的量,就应该注册成
nn.Parameter。 - 如果它是模型运行时需要保存的状态,但不参与训练,就适合注册成 buffer。
- 如果它只是临时变量,那就只是普通 tensor,不需要注册。
6.1 nn.Module 是什么
几乎所有模型都继承自 nn.Module,因为它不只是一个“写 forward 的类”,更重要的是它提供了一整套模型管理机制。
一个 nn.Module 主要负责:
- 注册参数
- 注册子模块
- 管理训练 / 推理模式
- 管理 device 迁移
- 导出和加载
state_dict
一个最简单的例子:
import torch
import torch.nn as nn
class ToyModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(4, 8)
def forward(self, x):
return self.linear(x)
这里 self.linear 会自动被注册成子模块,而 linear 里面的权重和偏置又会自动被注册成参数。
所以当你调用:
model.parameters()
model.to("cuda")
model.state_dict()
这些操作都会递归地作用到整个模型树上。这也是为什么 nn.Module 是 PyTorch 模型组织的核心。
6.2 nn.Parameter 与参数注册
nn.Parameter 的作用可以简单概括成一句话:把一个张量明确标记为“这是模型参数”。
例如:
self.weight = nn.Parameter(torch.ones(d))
这行代码的含义不是“创建了一个 tensor”这么简单,而是:
- 这个张量会被
nn.Module识别为参数。 - 它会出现在
model.parameters()里。 - 优化器会默认看到它。
- 它会随着
model.to(device)一起迁移。 - 它会进入
state_dict()。
如果你只是这样写:
self.weight = torch.ones(d)
那它只是一个普通 tensor 属性,不会自动被注册成参数。
一个最小例子:
class MyLayer(nn.Module):
def __init__(self, d):
super().__init__()
self.weight = nn.Parameter(torch.ones(d))
def forward(self, x):
return x * self.weight
这里的 weight 就是一个可学习参数。前面讲广播机制时提到的:
self.weight * normalized_x
经常就是这种写法。
6.3 requires_grad 和 grad
requires_grad 表示:这个张量是否需要被 autograd 跟踪,并在反向传播时计算梯度。
例如:
x = torch.tensor([1.0, 2.0], requires_grad=True)
如果一个张量 requires_grad=True,并且它参与了计算图,那么在调用:
loss.backward()
之后,它的梯度会出现在:
x.grad
对于模型训练来说,最常见的流程是:
optimizer.zero_grad()
loss = model(x)
loss.backward()
optimizer.step()
这里的逻辑是:
forward()算出 loss。backward()沿着计算图反向传播,给各个参数算出梯度。- 梯度会存到参数的
.grad属性里。 optimizer.step()读取这些梯度,更新参数。
要注意:
.grad是梯度,不是参数本身。- 梯度默认会累积,所以每轮训练前通常都要
zero_grad()。
对于大多数 nn.Parameter 来说,默认就是:
requires_grad = True
但也可以手动冻结参数:
param.requires_grad = False
这在冻结 embedding、冻结 backbone、只训练 LoRA 层时很常见。
6.4 register_buffer() 与 buffer
有些张量是模型运行时的一部分,但并不是要训练的参数。这类东西就很适合注册成 buffer。
你的这段例子就非常典型:
freqs_cos, freqs_sin = precompute_freqs_cis(
dim=config.hidden_size // config.num_attention_heads,
end=config.max_position_embeddings,
rope_base=config.rope_theta,
rope_scaling=config.rope_scaling
)
self.register_buffer("freqs_cos", freqs_cos, persistent=False)
self.register_buffer("freqs_sin", freqs_sin, persistent=False)
这里的 freqs_cos 和 freqs_sin 是预先计算好的 RoPE 频率表。它们:
- 是模型运行时需要用到的状态。
- 应该跟着模型一起搬到 GPU。
- 但它们不是要优化的参数,不应该交给优化器更新。
这正是 buffer 的典型使用场景。
可以这样理解 register_buffer():
- 它把一个 tensor 注册为“模型状态的一部分”。
- 它会跟着
model.to(device)一起迁移。 - 它默认会出现在
state_dict()里。 - 但它不是参数,不会出现在
model.parameters()里。
所以你原来的理解可以整理成:
nn.Parameter:把向量保存成参数。register_buffer:模型的一部分,一起加载进 GPU,不用手动to(device),不过不是参数,不进行优化。
这里还有一个细节:
persistent=False
这表示这个 buffer 不进入 state_dict()。
也就是说:
- 它仍然是 buffer。
- 它仍然会随着模型一起迁移 device。
- 但在保存模型权重时不会被保存下来。
这很适合那种“可以根据配置重新计算出来”的量,比如某些预计算表、缓存或辅助常量。
6.5 state_dict():模型到底保存了什么
state_dict() 可以理解成:模型当前状态的一个字典表示。
通常它包含:
- 所有参数
- 所有 persistent buffer
例如:
model.state_dict().keys()
通常会看到:
embedding.weightlayers.0.attn.q_proj.weightnorm.weight- 某些 buffer 名字
需要注意:
- 普通 tensor 属性默认不会进
state_dict()。 nn.Parameter会进。register_buffer(..., persistent=True)注册的 buffer 会进。persistent=False的 buffer 不会进。
所以从“是否保存模型状态”这个角度,也可以反过来理解 parameter 和 buffer 的语义。
6.6 nn.ModuleList vs nn.Sequential
这两个东西本质上都在做一件事:注册并管理子模块。
但它们的使用场景不一样。
| 特性 | nn.ModuleList | nn.Sequential |
|---|---|---|
| 是否自动 forward | 否,需要手动执行 | 是,自动顺序执行 |
| 是否注册参数 | 是 | 是 |
| 是否支持灵活逻辑 | 是,适合复杂结构 | 否,更适合纯顺序结构 |
| 典型应用 | Transformer、ResNet 等 | 简单 MLP、CNN 堆叠结构 |
可以把它们理解成:
nn.Sequential:不仅帮你注册模块,还默认把这些模块按顺序连起来。nn.ModuleList:只负责把模块收进来并注册好,真正怎么执行要你自己写。
例如:
self.layers = nn.ModuleList([
Block(config) for _ in range(config.num_hidden_layers)
])
for layer in self.layers:
x = layer(x)
这是 Transformer 里非常常见的写法。因为每一层之间往往不只是“无脑串起来”,中间可能还要插入:
- attention mask
- residual
- cache
- 条件分支
这时候 ModuleList 就比 Sequential 灵活得多。
6.7 train() 和 eval()
nn.Module 还有一个很重要但很容易被忽略的机制,就是训练模式和推理模式。
model.train()
model.eval()
它们不会直接关闭梯度,也不会直接更新参数,而是告诉某些模块当前应该采用哪种行为。
最典型的例子有:
DropoutBatchNorm
训练时和推理时它们的行为不同,所以模型在验证和推理前通常都要显式切到:
model.eval()
如果只是想关闭梯度计算,通常用的是:
with torch.no_grad():
...
这两个概念不要混在一起。
6.8 Autograd 图、叶子节点和 detach()
前面已经讲了 requires_grad 和 .grad,这里再补一层更接近底层的理解。
PyTorch 的 autograd 本质上是在记录一张计算图。只要一个张量:
requires_grad=True- 并且参与了后续计算
那么 PyTorch 就会把这些操作串成一张图,等你调用:
loss.backward()
时再沿图反向传播。
这里一个常见概念是叶子节点。
粗略理解:
- 用户直接创建、并且
requires_grad=True的参数,通常是叶子节点 - 中间计算结果通常不是叶子节点
例如:
w = torch.tensor([2.0], requires_grad=True)
y = w * 3
z = y.sum()
这里:
w是叶子节点y、z是中间结果
通常只有叶子节点会默认保留 .grad。
detach()
detach() 的作用是:返回一个和原张量共享数据、但不再参与当前计算图的新张量。
x = torch.randn(3, requires_grad=True)
y = x * 2
z = y.detach()
这里 z 的数据和 y 一样,但 autograd 不会继续追踪 z 后面的操作。
常见用途:
- 不希望某段路径继续反向传播
- 记录中间结果但不保留梯度链路
- 构造 target、cache 或某些分析输出
torch.no_grad()
如果你想在一整段代码里都关闭梯度计算,通常用:
with torch.no_grad():
y = model(x)
这和 detach() 的区别是:
detach()是针对某个张量切断图torch.no_grad()是在一个上下文里整体不记录计算图
推理和验证阶段非常常用 no_grad(),因为这样可以节省显存和计算开销。
6.9 CUDA、device 和 dtype 管理
训练代码里另一个非常常见的问题不是“公式错了”,而是“张量不在同一个 device / dtype 上”。
device
每个 tensor 都有自己的 device,比如:
x.device
常见值有:
cpucuda:0
把张量或模型移动到某个 device:
x = x.to("cuda")
model = model.to("cuda")
一个非常重要的原则是:
- 参与同一次运算的张量,通常必须在同一个 device 上。
例如下面这种情况就会报错:
x = torch.randn(2, 3, device="cuda")
y = torch.randn(2, 3, device="cpu")
z = x + y
为什么 parameter 和 buffer 很重要
这也能反过来解释,为什么 nn.Parameter 和 buffer 要注册到 nn.Module 里。
因为一旦它们被注册了,下面这种操作:
model.to("cuda")
就会自动把:
- 参数
- buffer
一起迁移过去。否则很多时候你就得手动管理每个 tensor 的 device。
dtype
dtype 表示张量的数据类型,例如:
torch.float32torch.float16torch.bfloat16torch.int64
查看类型:
x.dtype
转换类型:
x = x.to(torch.float16)
x = x.float()
x = x.long()
在 LLM 里经常会同时碰到:
- token id:通常是整数类型,比如
torch.long - 激活值和参数:通常是浮点类型,比如
float32、float16、bfloat16
这也是为什么 embedding 的输入通常要是整数索引,而不能直接拿 float 去喂。
一个常见写法
训练代码里经常会看到:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
x = x.to(device)
如果还要统一 dtype,也可能写成:
model = model.to(device=device, dtype=torch.bfloat16)
常见报错来源
如果你在读 MiniMind 或自己写代码时看到下面这种错误,通常就该先检查 device 和 dtype:
- expected all tensors to be on the same device
- expected scalar type Float but found Half
- expected Long but got Float
先查这几个属性往往比盯着公式更有效:
x.shape
x.device
x.dtype
7. 一些容易混淆的点
7.1 cat 和 stack 的区别
cat:沿已有维度拼接,不增加新维度。stack:先增加一个新维度,再拼接。
7.2 view 和 reshape 的区别
view:要求连续内存,不复制数据。reshape:更宽松,必要时可能复制数据。
7.3 expand 和 repeat 的区别
expand:不复制数据,只做广播视图。repeat:真实复制数据。
7.4 为什么有时候 view() 会报错
通常是因为前面做了 transpose()、permute()、expand() 之类的操作,得到的张量不是 contiguous tensor。
这时一般有两种处理方式:
x = x.contiguous().view(...)
或者:
x = x.reshape(...)
Math Cookbook
这一部分整理学习 LLM 时常遇到的数学符号和概念。数学是一个很讲究定义和严谨的学科,然而细节和内容又太多太杂.所以我觉得一份Cookbook是一个很好的选择,把相关的概念整理成闭包,随时查阅.
Probability Space
概率空间、随机变量和分布:从集合到测度
在机器学习里,我们经常直接写:
\[ x \sim p(x), \quad \mathbb{E}_{x \sim p(x)}[f(x)] \]
这种写法很方便,但它把很多底层概念压缩到了一行里:什么是样本空间?什么是事件?什么是概率?随机变量到底是不是一个“变量”?分布和密度函数又是什么关系?
如果只做工程实现,很多时候不需要把这些概念全部展开。但一旦进入期望、条件概率、似然、KL 散度、最大似然估计这些内容,严格区分这些对象会让公式更清楚。概率空间就是这套符号的地基。
概率空间是什么
一个概率空间通常写成:
\[ (\Omega, \mathcal{F}, \mathbb{P}) \]
这里的三个对象分别是:
- \(\Omega\):样本空间,表示所有可能的实验结果。
- \(\mathcal{F}\):事件集合,是 \(\Omega\) 上的一个 \(\sigma\)-代数,表示哪些集合可以被讨论概率。
- \(\mathbb{P}\):概率测度,给每个可测事件分配一个 \([0,1]\) 之间的数。
可以把它理解成:
概率空间不是直接给“点”分配概率,而是先规定哪些“事件集合”可以讨论概率,再用 \(\mathbb{P}\) 给这些事件赋值。
例如,掷一次骰子时,可以令:
\[ \Omega = \{1,2,3,4,5,6\} \]
事件“掷出偶数”不是一个单独结果,而是一个集合:
\[ A = \{2,4,6\} \]
如果骰子是公平的,那么:
\[ \mathbb{P}(A) = \frac{3}{6} = \frac{1}{2} \]
这里真正被赋予概率的是事件集合 \(A\),而不是“偶数”这个自然语言描述。
\(\sigma\)-代数是什么
\(\mathcal{F}\) 是 \(\Omega\) 上的一个 \(\sigma\)-代数。它的作用是规定:哪些集合可以被当作事件,哪些集合可以被概率测度 \(\mathbb{P}\) 处理。
一个集合族 \(\mathcal{F}\) 如果是 \(\sigma\)-代数,至少要满足:
- 包含全集:\(\Omega \in \mathcal{F}\)。
- 对补集封闭:如果 \(A \in \mathcal{F}\),那么 \(A^c \in \mathcal{F}\)。
- 对可列并封闭:如果 \(A_1,A_2,\dots \in \mathcal{F}\),那么 \(\bigcup_{i=1}^{\infty} A_i \in \mathcal{F}\)。
这些条件保证了我们平时对事件做的操作仍然是合法事件。例如,已知 \(A\) 和 \(B\) 是事件,那么“不是 \(A\)”、“\(A\) 或 \(B\)”、“\(A\) 且 \(B\)”也都应该是事件。
在有限样本空间里,通常可以直接取幂集:
\[ \mathcal{F} = 2^\Omega \]
也就是 \(\Omega\) 的所有子集都可以讨论概率。
但在连续空间里,比如 \(\Omega=\mathbb{R}\),并不是所有子集都适合被赋予概率。测度论引入 \(\sigma\)-代数,就是为了避开那些过于病态、无法稳定定义测度的集合。机器学习里通常不用深究这些病态集合,但知道 \(\mathcal{F}\) 的角色很重要:概率不是定义在任意东西上的,而是定义在可测事件上的。
测度是什么
测度可以理解成一种“给集合赋大小”的函数。概率测度是测度的一种特殊情况。
在概率空间中,\(\mathbb{P}\) 是一个函数:
\[ \mathbb{P}: \mathcal{F} \to [0,1] \]
它把一个可测事件 \(A \in \mathcal{F}\) 映射成一个概率值 \(\mathbb{P}(A)\)。
概率测度至少满足三个核心性质:
- 非负性:对任意事件 \(A \in \mathcal{F}\),都有 \(\mathbb{P}(A) \geq 0\)。
- 规范化:整个样本空间的概率为 \(\mathbb{P}(\Omega)=1\),空集的概率为 \(\mathbb{P}(\varnothing)=0\)。
- 可列可加性:如果 \(A_1,A_2,\dots\) 两两不相交,则
\[ \mathbb{P}\left(\bigcup_{i=1}^{\infty} A_i\right) = \sum_{i=1}^{\infty}\mathbb{P}(A_i) \]
其中,\(A_i\) 表示第 \(i\) 个事件,\(\bigcup_{i=1}^{\infty} A_i\) 表示这些事件的并集。
直观上,可列可加性就是说:如果一组事件互不重叠,那么“它们中至少发生一个”的概率,等于每个事件概率的和。
这里引入了测度论中概率测度的概念。如果只从概率论的视角看,概率,或者说概率测度,就是一个函数:它把事件集合映射到 \([0,1]\) 之间的数值。
这其实也揭示了测度论的基本思想:我们想要给某些集合赋予一个“大小”或者“权重”(measure)。概率测度就是给事件集合赋予一个“概率大小”。可以说,概率论是测度论在总大小为 1 时的一种特殊表现形式。
随机变量是什么
随机变量 \(X\) 并不是普通意义上的“变量”。更严格地说,它是一个从样本空间到取值空间的函数:
\[ X: \Omega \to \mathcal{X} \]
其中:
- \(\Omega\):底层样本空间,包含所有实验结果 \(\omega\)。
- \(\mathcal{X}\):随机变量的取值空间。
- \(X(\omega)\):当实验结果为 \(\omega\) 时,随机变量 \(X\) 取到的值。
例如,掷一次骰子时,底层实验结果可以就是骰子的实际点数。此时可以定义:
\[ X(\omega) = \omega \]
如果我们只关心“是不是偶数”,也可以定义另一个随机变量:
\[ Y(\omega) = \begin{cases} 1, & \omega \in \{2,4,6\} \\ 0, & \omega \in \{1,3,5\} \end{cases} \]
这里 \(X\) 和 \(Y\) 是两个不同的随机变量。它们面对同一个底层实验结果 \(\omega\),但提取的信息不同。
在机器学习里,底层样本空间 \(\Omega\) 往往不会显式写出来。比如我们说“一条训练样本 \(X\) 来自数据分布”,真正关心的是 \(X\) 的取值空间,比如文本序列、图片张量或 token id 序列,而不是底层的 \(\omega\)。但从严格数学上说,随机变量仍然是从 \(\Omega\) 到取值空间的映射。
分布是什么
有了随机变量 \(X\) 之后,我们通常关心的是:\(X\) 落到某个取值集合 \(A\) 里的概率是多少?
这里的 \(A\) 是取值空间 \(\mathcal{X}\) 里的集合。可是原始概率测度 \(\mathbb{P}\) 定义在样本空间 \(\Omega\) 上,不能直接作用在 \(A\) 上。因此,我们需要先把 \(A\) 拉回到样本空间:
\[ X^{-1}(A) = \{ \omega \in \Omega : X(\omega) \in A \} \]
这里 \(X^{-1}(A)\) 表示所有会被 \(X\) 映射到 \(A\) 里的底层实验结果。它是 \(\Omega\) 里的事件,所以可以用 \(\mathbb{P}\) 计算概率。
于是我们定义一个新的测度 \(\mu_X\):
\[ \mu_X(A) = \mathbb{P}(X^{-1}(A)) \]
这个 \(\mu_X\) 就是随机变量 \(X\) 在取值空间 \(\mathcal{X}\) 上诱导出来的分布,也叫推前测度。也就是说:
分布不是凭空出现的函数,而是随机变量把底层概率测度 \(\mathbb{P}\) 推到取值空间之后得到的测度。
严格写法可以写成:
\[ X \sim \mu_X \]
意思是:随机变量 \(X\) 的分布是 \(\mu_X\)。
\(\mathbb{P}\)、\(\mu_X\) 和 \(p(x)\) 的区别
这里出现了两个很容易混淆的概念:概率测度 \(\mathbb{P}\),还有我们刚才提到的测度 \(\mu_X\)。
当时一个很让我困扰的问题是:概率空间里面到底有几个概率测度?
答案是:概率空间本身只定义了一个概率测度 \(\mathbb{P}\)。\(\mu_X\) 不是概率空间里额外给出的第二个原始测度,而是随机变量 \(X\) 和原始概率测度 \(\mathbb{P}\) 一起诱导出来的分布测度。
这可能有点绕口,不过这么理解就会清楚一些:测度是什么?就是给一系列集合赋值的函数。在概率空间里,这一系列集合是事件集合 \(\mathcal{F}\),赋值函数是 \(\mathbb{P}\)。而概率空间 \((\Omega,\mathcal{F},\mathbb{P})\) 的定义里面本身不包含随机变量,所以 \(\mathbb{P}\) 只是定义在事件集合上的。
那么随机变量加入之后发生了什么呢?我们开始关心的往往不再是底层事件 \(A \subseteq \Omega\),而是随机变量 \(X\) 在取值空间 \(\mathcal{X}\) 里会落到哪些集合中。例如,我们关心的可能是 \(X\) 是否落在某个集合 \(B \subseteq \mathcal{X}\) 里。
但 \(\mathbb{P}\) 不能直接作用在 \(B\) 上,因为 \(B\) 是取值空间里的集合,不是样本空间里的事件。于是我们需要先通过 \(X^{-1}(B)\) 把它拉回到样本空间,再用 \(\mathbb{P}\) 计算概率:
\[ \mu_X(B) = \mathbb{P}(X^{-1}(B)) \]
这就是为什么说 \(\mu_X\) 是“由随机变量诱导出的分布/测度”。显然,随机变量不同,同样的取值集合对应的概率也可能不同。这样看就清晰了:\(\mathbb{P}\) 定义在原始事件空间上,而 \(\mu_X\) 定义在随机变量的取值空间上。
最后,分布本质上是在描述“随机变量落入取值空间中某些集合的概率”。这正是测度做的事情:给集合赋值。所以在测度论的语境下,分布可以理解为定义在取值空间上的概率测度。
另一种描述抽象的描述: 随机变量是一个可测函数,它把概率测度推前(pushforward)成分布测度。
总结:
- \(\mathbb{P}\):定义在原始样本空间 \(\Omega\) 上的概率测度。
- \(\mu_X\):由随机变量 \(X\) 诱导到取值空间 \(\mathcal{X}\) 上的分布测度。
- \(p(x)\):当 \(\mu_X\) 可以用密度函数或质量函数表示时,\(p(x)\) 是这个函数在点 \(x\) 处的值。
如果 \(\mu_X\) 在连续空间上有密度 \(p(x)\),可以写成:
\[ d\mu_X(x) = p(x)dx \]
其中,\(dx\) 表示对取值空间中的变量 \(x\) 做积分时使用的基础测度,通常是 Lebesgue 测度;\(p(x)\) 是相对于这个基础测度的密度。
因此,严格地说,分布首先是一个测度 \(\mu_X\),密度函数 \(p(x)\) 只是表示这个测度的一种方式。我们平时说“分布 \(p(x)\)”是一种常见简写。
测度论视角下的期望
从原始概率空间看,如果 \(X\) 是随机变量,\(f(X)\) 也是随机变量,那么期望可以写成:
\[ \mathbb{E}[f(X)] = \int_{\Omega} f(X(\omega))d\mathbb{P}(\omega) \]
这里:
- \(\omega\):样本空间里的实验结果。
- \(X(\omega)\):随机变量在实验结果 \(\omega\) 上的取值。
- \(f(X(\omega))\):函数 \(f\) 作用在这个取值上的结果。
- \(d\mathbb{P}(\omega)\):按照概率测度 \(\mathbb{P}\) 对 \(\omega\) 加权积分。
由于 \(X\) 已经把 \(\mathbb{P}\) 推到了取值空间,期望也可以写成对分布测度 \(\mu_X\) 的积分:
\[ \mathbb{E}[f(X)] = \int_{\mathcal{X}} f(x) d\mu_X(x) \]
如果 \(\mu_X\) 有密度 \(p(x)\),那么:
\[ \mathbb{E}[f(X)] = \int_{\mathcal{X}} f(x)p(x) dx \]
这里的 \(x\) 是积分变量,也就是 dummy variable。它不是随机变量本身,而是取值空间中的占位符。
这也解释了为什么机器学习论文里常写:
\[ \mathbb{E}_{x \sim p(x)}[f(x)] \]
严格来看,这种角标里的 \(x \sim p(x)\) 不是在说“积分变量 \(x\) 真的服从分布”。它更像是 ML 语境下的简写:提醒我们用 \(x\) 作为积分变量,并按照 \(p(x)\) 加权积分,或者从采样平均的角度理解这个期望。
一个实用记忆方式
可以把这几个对象按层次记住:
- 概率空间 \((\Omega,\mathcal{F},\mathbb{P})\):定义底层随机性。
- 随机变量 \(X:\Omega \to \mathcal{X}\):从底层结果中提取我们关心的值。
- 分布 \(\mu_X\):随机变量 \(X\) 在取值空间上诱导出的测度。
- 密度或质量函数 \(p(x)\):在可以表示时,用函数形式描述分布。
- 期望 \(\mathbb{E}[f(X)]\):对随机变量函数做测度积分。
因此,看到:
\[ X \sim p(x) \]
可以理解为:随机变量 \(X\) 的分布可以用密度或质量函数 \(p(x)\) 描述。
看到:
\[ \mathbb{E}_{x \sim p(x)}[f(x)] \]
可以理解为:对取值空间中的 \(x\),按照 \(p(x)\) 加权,计算 \(f(x)\) 的平均效果。
这样读,既能兼容机器学习论文里的常见简写,也能保留概率论中“随机变量、取值、分布、测度”之间的严格关系。
Expectation Notation
样本还是随机变量? 期望和分布的严格Notation
期望角标和括号里的 \(X\) 应该大写还是小写?这个问题看似很简单,但实际并没有那么显然。ML 里的符号有很多工程化简写,再加上不同学科的符号习惯并不完全一致,导致同一个符号在不同语境下可能承担不同角色。
符号是定义的体现。所以这一节先从严格的数学视角出发,区分随机变量、取值、样本和分布;再回到 ML 论文中常见的简写,说明这些简写到底省略了什么。
随机变量、取值和样本
严格来说,期望括号里的对象应该是随机变量,或者是随机变量的函数。例如:
\[ \mathbb{E}[X] \]
这里的 \(X\) 通常使用大写,表示一个随机变量。与之对应,\(x\) 通常使用小写,表示随机变量 \(X\) 的一个具体取值。
例如,如果 \(X\) 表示“从数据集中随机抽取一条样本”,那么 \(X\) 是随机变量;而某一次真正抽到的样本,比如一段具体的文本、一张具体的图片,才是 \(x\)。所以,\(X\) 和 \(x\) 的区别不是“抽象”和“具体”这么简单,而是:
- \(X\):随机变量,还没有真正落到某个具体值上。
- \(x\):随机变量 \(X\) 的一个可能取值,或者一次采样得到的样本。
这个区分在把期望写成积分或者求和时尤其重要。
分布应该怎么写
如果随机变量 \(X\) 服从某个分布,常见写法是:
\[ X \sim p(x) \]
这句话的含义是:随机变量 \(X\) 的分布由概率质量函数或者概率密度函数 \(p(x)\) 描述。其中,\(x\) 是随机变量 \(X\) 的取值。
更严格一点说,\(p\) 表示分布本身,或者表示这个分布对应的概率质量函数、概率密度函数;\(p(x)\) 表示这个函数在具体取值 \(x\) 处的值。
因此,下面几个符号的角色并不完全一样:
- \(X\):随机变量。
- \(x\):随机变量 \(X\) 的取值。
- \(p\):分布,或者分布对应的概率函数。
- \(p(x)\):在取值 \(x\) 处的概率质量或概率密度。
如果这时候\(x \) 被理解成了取值,样本最好就由 \(x_i\) 来表示.然而无论是变量,还是样本本质是都是固定的值,它们都不能服从分布. 只有随机变量才谈得上“服从分布”.这种简写在 ML 论文中非常常见,通常是为了简化表达,表示这个样本符合某个分布.
\[ x \sim p(x) \]
期望角标怎么写
如果上下文已经明确了 \(X\) 的分布,可以直接写:
\[ \mathbb{E}[X] \]
如果想强调“对随机变量 \(X\) 求期望”,但暂时不显式写出它的分布,可以写:
\[ \mathbb{E}_X[f(X)] \]
这里的角标 \(X\) 表示期望是关于随机变量 \(X\) 的。这个写法省略了 \(X\) 具体服从哪个分布,因此适合用于分布已经在上下文中定义清楚的场景。
如果想把分布也写清楚,可以写:
\[ \mathbb{E}_{X \sim p}[f(X)] \]
这个写法比较严格,含义是:随机变量 \(X\) 服从分布 \(p\),然后对随机变量的函数 \(f(X)\) 求期望。
也可以看到下面这种写法:
\[ \mathbb{E}_{X \sim p(x)}[f(X)] \]
它的意思仍然是 \(X\) 服从由 \(p(x)\) 描述的分布。不过从符号层面看,\(p(x)\) 里面的小写 \(x\) 是密度函数或质量函数的自变量,而角标里的 \(X\) 是随机变量。这个写法能读懂,但不如 \(\mathbb{E}_{X \sim p}[f(X)]\) 干净。
在 ML 论文中,更常见的写法是:
\[ \mathbb{E}_{x \sim p(x)}[f(x)] \]
这个写法里的 \(x\) 不再严格表示随机变量,而是更像“从分布 \(p\) 中采样得到的一个样本”。它强调的是采样过程:从 \(p(x)\) 中采样一个 \(x\),然后计算 \(f(x)\),最后对很多次采样结果取平均。
所以,\(\mathbb{E}_{x \sim p(x)}[f(x)]\) 是机器学习语境下非常自然的写法,但如果从严格概率论的角度看,它其实是把随机变量和它的取值都记成了 \(x\)。这种省略通常没有问题,只要读者知道这里的 \(x\) 代表“采样得到的样本”。
还有一种常见简写是:
\[ \mathbb{E}_{p(x)}[f(x)] \]
这里的角标 \(p(x)\) 表示“在分布 \(p(x)\) 下求期望”。严格来说,\(p(x)\) 不是随机变量,而是概率质量函数或概率密度函数,所以这个写法也是一种省略。它省略的是“哪个随机变量服从这个分布”。完整含义可以理解为:
\[ X \sim p, \quad \mathbb{E}_{X \sim p}[f(X)] \]
积分形式和求和形式
假设 \(X\) 是连续随机变量,\(p(x)\) 是 \(X\) 的概率密度函数。对于随机变量函数 \(f(X)\),它的期望可以写成:
\[ \mathbb{E}_{X \sim p}[f(X)] = \int f(x) p(x) dx \]
这里需要注意左右两边的符号变化。左边的 \(f(X)\) 使用大写 \(X\),表示它是随机变量的函数;右边的 \(f(x)\) 使用小写 \(x\),因为积分里需要一个具体的积分变量。
如果 \(X\) 是离散随机变量,\(p(x)\) 是 \(X\) 的概率质量函数,那么对应的求和形式是:
\[ \mathbb{E}_{X \sim p}[f(X)] = \sum_x f(x) p(x) \]
从积分的角度: \[ \mathbb{E}_{x \sim p(x)}[f(x)] = \int f(x) p(x) dx \] 中间的 \(x \) 在某些情况下也被理解成 dummy variable (积分变量),而不是样本或者随机变量. 这确实会引入更多的费解: 积分变量或者样本并不能复合一个分布.
推荐的写法
只能说样本,随机变量,积分变量这几个概念实在是太相似又有点乱,而字母又不够用.所以期望的形式实际并不是那么清晰,
不过始终要牢记,期望是作用于随机变量的算子,而不是样本或者一般变量.(时刻思考期望在对哪个随机变量做积分)这一点会在条件期望的时候变得非常重要,让很多形式变得清晰:
所以我个人更倾向于下面这种写法,强调随机变量的写法:
\[ X \sim p(x), \quad \mathbb{E}_{X \sim p}[f(X)] \]
这种写法清楚地区分了随机变量 \(X\)、分布 \(p\),随机变量取值 \( x \),以及随机变量函数 \(f(X)\)。
如果是在讨论机器学习论文、损失函数或者训练目标,也可以使用更常见的采样式写法:
\[ \mathbb{E}_{x \sim p(x)}[f(x)] \]
这更多是在从积分变量(对随机变量的积分),或者样本采样的角度来理解期望(对某个随机变量采样).但我还是建议时刻从随机变量的角度来思考,就像是括号里的内容.
所以,一个比较实用的阅读规则是:
- 看到 \(\mathbb{E}_{X \sim p}[f(X)]\),把它理解为严格的随机变量记法。
- 看到 \(\mathbb{E}_{x \sim p(x)}[f(x)]\),把它理解为 ML 论文中的采样记法。
- 看到 \(\mathbb{E}_{p(x)}[f(x)]\),把它理解为“在分布 \(p(x)\) 下取期望”的省略写法。
只要先定义清楚符号,这几种写法通常都可以使用。真正重要的是不要在同一段推导里随意切换含义:如果 \(X\) 表示随机变量,\(x\) 表示具体取值,那么后面的公式最好持续保持这个约定。
Likelihood
Likelihood 是什么?它和条件概率有什么区别
似然 likelihood 是机器学习里非常容易混淆的概念。它看起来和条件概率长得一模一样,比如:
\[ p(x \mid \theta) \]
但在不同语境下,这个表达式的阅读方式完全不同。
如果 \(\theta\) 是固定参数,\(x\) 是随机变量的取值,那么 \(p(x \mid \theta)\) 是一个条件概率分布或条件密度。它回答的是:
在参数 \(\theta\) 已知的情况下,观测到数据 \(x\) 的概率或密度是多少?
如果观测数据 \(x\) 已经固定,而我们把 \(\theta\) 当成变量来看,那么同一个表达式就变成了 \(\theta\) 的似然函数:
\[ L(\theta; x) = p(x \mid \theta) \]
它回答的是:
已经观测到数据 \(x\) 之后,不同参数 \(\theta\) 对这份数据的解释能力有多强?
所以,似然和条件概率的联系是:它们经常使用同一个数学表达式。区别是:条件概率把参数固定、数据当随机对象;似然把数据固定、参数当作待比较的对象。
从条件概率开始
假设有一个带参数的概率模型。参数记为 \(\theta\),数据随机变量记为 \(X\),观测值记为 \(x\)。
模型通常写成:
\[ p(x \mid \theta) \]
这里:
- \(\theta\):模型参数,例如高斯分布的均值和方差,或者语言模型的所有权重。
- \(X\):随机变量,表示模型可能生成的数据。
- \(x\):随机变量 \(X\) 的一个具体观测值。
- \(p(x \mid \theta)\):在参数为 \(\theta\) 时,观测到 \(x\) 的概率质量或概率密度。
如果 \(\theta\) 已经固定,那么 \(p(x \mid \theta)\) 是关于 \(x\) 的分布。它必须满足概率分布的要求。
离散情况下:
\[ \sum_x p(x \mid \theta) = 1 \]
连续情况下:
\[ \int p(x \mid \theta) dx = 1 \]
这时我们是在问:在这个模型参数下,不同数据 \(x\) 出现的概率如何分布?
似然函数是什么
当数据 \(x\) 已经观测到以后,我们往往想反过来问:哪个参数 \(\theta\) 更可能生成这份数据?
这时定义似然函数:
\[ L(\theta; x) = p(x \mid \theta) \]
这里的分号 \(;\) 是一种常见记号,用来提醒读者:\(x\) 是已经固定的观测数据,\(\theta\) 才是我们正在比较的变量。
因此,似然函数不是关于 \(x\) 的函数,而是关于 \(\theta\) 的函数:
\[ \theta \mapsto L(\theta; x) \]
它的值越大,表示参数 \(\theta\) 越能解释已经观测到的数据 \(x\)。但要特别注意:
似然不是 \(\theta\) 的概率分布。
也就是说,一般并不要求:
\[ \int L(\theta; x) d\theta = 1 \]
或者在离散参数空间中:
\[ \sum_\theta L(\theta; x) = 1 \]
似然值只适合在不同参数之间做相对比较。它告诉我们哪个参数让观测数据更“合理”,但它本身还不是参数的概率。
条件概率和似然的区别
同一个表达式:
\[ p(x \mid \theta) \]
可以有两种读法。
第一种读法是条件概率或条件密度:
\[ x \mapsto p(x \mid \theta) \]
这里 \(\theta\) 固定,\(x\) 是变量。它描述的是:给定参数 \(\theta\),不同数据 \(x\) 出现的概率或密度。
第二种读法是似然函数:
\[ \theta \mapsto L(\theta; x) = p(x \mid \theta) \]
这里 \(x\) 固定,\(\theta\) 是变量。它描述的是:已经看到数据 \(x\),不同参数 \(\theta\) 对这份数据的支持程度。
可以用一句话概括:
条件概率是在参数已知时看数据;似然是在数据已知时看参数。
这也是为什么 likelihood 通常翻译成“似然”:它不是直接说某个参数“概率大”,而是说这个参数看起来“像是能生成这份数据”。
一个抛硬币的例子
假设一枚硬币正面朝上的概率是 \(\theta\)。我们抛 \(n\) 次硬币,观测到正面 \(k\) 次,反面 \(n-k\) 次。
设 \(X\) 表示正面出现的次数。如果参数 \(\theta\) 固定,那么:
\[ X \sim \mathrm{Binomial}(n,\theta) \]
其中,\(n\) 表示实验次数,\(\theta\) 表示每次正面朝上的概率。于是:
\[ p(k \mid \theta) = \binom{n}{k}\theta^k(1-\theta)^{n-k} \]
这里:
- \(k\):已经观测到的正面次数。
- \(n\):总抛掷次数。
- \(\theta\):硬币正面朝上的概率。
- \(\binom{n}{k}\):从 \(n\) 次抛掷中选出 \(k\) 次正面的组合数。
如果 \(\theta\) 固定,比如 \(\theta=0.5\),那么 \(p(k \mid \theta)\) 是关于 \(k\) 的概率分布。它回答:公平硬币抛 \(n\) 次,正面出现 \(k\) 次的概率是多少?
但如果我们已经观测到了 \(k\),比如 \(n=10\),\(k=7\),那么:
\[ L(\theta; k) = \binom{10}{7}\theta^7(1-\theta)^3 \]
这时 \(k=7\) 固定,\(\theta\) 是变量。我们在比较不同 \(\theta\) 对“10 次里有 7 次正面”这件事的解释能力。
比如:
\[ L(0.5; 7) = \binom{10}{7}0.5^7(1-0.5)^3 \]
\[ L(0.7; 7) = \binom{10}{7}0.7^7(1-0.7)^3 \]
如果 \(L(0.7;7) > L(0.5;7)\),说明 \(\theta=0.7\) 比 \(\theta=0.5\) 更能解释这次观测结果。但这不等于说“\(\theta=0.7\) 的概率比 \(\theta=0.5\) 大”。要谈参数的概率,还需要引入先验分布。
最大似然估计
最大似然估计 maximum likelihood estimation, MLE 的思想很直接:选择让观测数据似然最大的参数。
设观测数据为 \(x\),参数为 \(\theta\),似然函数为:
\[ L(\theta; x)=p(x \mid \theta) \]
那么最大似然估计定义为:
其中:
- \(\hat{\theta}_{\mathrm{MLE}}\):最大似然估计得到的参数。
- \(\arg\max_{\theta}\):让目标函数取得最大值的 \(\theta\)。
- \(L(\theta;x)\):观测数据 \(x\) 固定时,参数 \(\theta\) 的似然。
在实际计算中,我们常用对数似然:
\[ \ell(\theta; x) = \log L(\theta; x) = \log p(x \mid \theta) \]
因为对数函数单调递增,所以最大化 \(L(\theta;x)\) 和最大化 \(\ell(\theta;x)\) 得到的参数相同:
\[ \arg\max_{\theta} L(\theta;x) = \arg\max_{\theta} \ell(\theta;x) \]
对数似然的好处是可以把很多连乘变成求和,数值上也更稳定。
多个独立样本的似然
假设观测到一组独立同分布样本:
\[ x_1, x_2, \dots, x_N \]
其中,\(x_i\) 表示第 \(i\) 个观测样本,\(N\) 表示样本数量。若每个样本都来自同一个参数为 \(\theta\) 的模型,并且样本之间相互独立,则联合概率为:
\[ p(x_1,\dots,x_N \mid \theta) = \prod_{i=1}^{N} p(x_i \mid \theta) \]
因此似然函数为:
\[ L(\theta; x_1,\dots,x_N) = \prod_{i=1}^{N} p(x_i \mid \theta) \]
对数似然为:
\[ \ell(\theta; x_1,\dots,x_N) = \sum_{i=1}^{N} \log p(x_i \mid \theta) \]
这就是很多机器学习训练目标的基本形式。最大化训练数据的对数似然,等价于让模型给真实数据分配更高的概率或密度。
在语言模型中,如果一段 token 序列为:
\[ x_1, x_2, \dots, x_T \]
自回归模型通常分解为:
\[ p_\theta(x_1,\dots,x_T) = \prod_{t=1}^{T} p_\theta(x_t \mid x_{<t}) \]
其中,\(x_{<t}\) 表示第 \(t\) 个 token 之前的上下文。训练时最大化:
\[ \sum_{t=1}^{T} \log p_\theta(x_t \mid x_{<t}) \]
或者等价地最小化负对数似然:
\[ -\sum_{t=1}^{T} \log p_\theta(x_t \mid x_{<t}) \]
这就是语言模型交叉熵损失背后的概率解释。
似然和贝叶斯后验
如果只使用似然,我们只能比较不同 \(\theta\) 对数据的解释能力。若想得到“参数 \(\theta\) 在看到数据后的概率”,需要使用贝叶斯公式。
这里有一个容易混淆的点:贝叶斯公式里面的 \(p(x \mid \theta)\),到底是条件概率,还是似然?
更准确的说法是:在贝叶斯公式本身里,\(p(x \mid \theta)\) 是条件概率或条件密度;但是当观测数据 \(x\) 已经固定,而我们把它看成 \(\theta\) 的函数时,它就承担了似然函数的角色。
设:
- \(p(\theta)\):参数的先验分布,表示观测数据前对 \(\theta\) 的相信程度。
- \(p(x \mid \theta)\):给定参数 \(\theta\) 时,数据 \(x\) 的条件概率或条件密度。
- \(p(\theta \mid x)\):后验分布,表示观测到 \(x\) 后对 \(\theta\) 的相信程度。
贝叶斯公式写成:
\[ p(\theta \mid x) = \frac{p(x \mid \theta)p(\theta)}{p(x)} \]
从这个公式本身看,\(p(x \mid \theta)\) 是一个条件分布里的项。也就是说,如果固定 \(\theta\),它描述的是数据 \(x\) 如何分布。离散情况下,它对 \(x\) 求和应该为 1;连续情况下,它对 \(x\) 积分应该为 1。
其中,\(p(x)\) 是证据项:
\[ p(x) = \int p(x \mid \theta)p(\theta) d\theta \]
但在贝叶斯统计里,我们通常已经观测到了数据 \(x\),接下来关心的是 \(\theta\) 的后验分布。这时 \(x\) 被固定下来,\(p(x \mid \theta)\) 就可以被看成 \(\theta\) 的函数:
\[ L(\theta; x) = p(x \mid \theta) \]
这个 \(L(\theta;x)\) 就是似然函数。它不需要对 \(\theta\) 归一化,因此它本身不是 \(\theta\) 的概率分布。它只是告诉我们:不同的 \(\theta\) 对已经观测到的数据 \(x\) 有多大的支持程度。
如果只关心 \(\theta\) 的相对大小,贝叶斯公式可以写成正比形式:
\[ p(\theta \mid x) \propto p(x \mid \theta)p(\theta) \]
这时候右边的 \(p(x \mid \theta)\) 就是在作为“似然因子”使用。因此我们经常说:
后验 \(p(\theta \mid x)\) 正比于似然 \(L(\theta;x)\) 乘以先验 \(p(\theta)\)。
这句话里的“似然”,不是说 \(p(x \mid \theta)\) 在原始定义上变成了一个关于 \(\theta\) 的概率分布,而是说:在固定观测数据 \(x\) 之后,我们把同一个条件概率或条件密度表达式当作 \(\theta\) 的函数来使用。
所以更严谨地说:
- 贝叶斯公式中的 \(p(x \mid \theta)\) 是条件概率或条件密度。
- 固定观测数据 \(x\) 后,\(p(x \mid \theta)\) 作为 \(\theta\) 的函数,就是似然 \(L(\theta;x)\)。
- 后验不是似然本身,而是先验乘以似然,再通过证据项 \(p(x)\) 归一化之后得到的分布。
如果没有先验和归一化,似然本身不能直接解释成参数的概率分布。
连续变量中的一个注意点
在连续随机变量中,\(p(x \mid \theta)\) 是密度,不是点概率。也就是说:
\[ \mathbb{P}(X=x \mid \theta) = 0 \]
但密度 \(p(x \mid \theta)\) 仍然可以用来比较不同参数对观测值附近区域的解释能力。
例如,对于高斯模型:
\[ X \sim \mathcal{N}(\mu,\sigma^2) \]
如果 \(\sigma\) 已知,\(\mu\) 是未知参数,那么观测到一个具体值 \(x\) 后,似然函数是:
\[ L(\mu; x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x-\mu)^2}{2\sigma^2}\right) \]
这里 \(x\) 固定,\(\mu\) 是变量。似然最大的 \(\mu\) 会靠近观测值 \(x\)。但 \(L(\mu;x)\) 仍然不是 \(\mu\) 的概率密度,除非我们进一步引入先验并做归一化。
一个实用区分
可以用下面这张表来区分条件概率和似然:
| 表达式 | 固定什么 | 变量是什么 | 含义 | 是否需要对变量归一化 |
|---|---|---|---|---|
| \(p(x \mid \theta)\) 作为条件概率 | \(\theta\) | \(x\) | 参数已知时数据的分布 | 需要对 \(x\) 归一化 |
| \(L(\theta;x)=p(x \mid \theta)\) 作为似然 | \(x\) | \(\theta\) | 数据已知时参数的相对解释能力 | 不需要对 \(\theta\) 归一化 |
一句话总结:
条件概率关心“给定参数,数据怎么分布”;似然关心“给定数据,哪个参数更能解释它”。
在机器学习训练里,我们通常已经有固定的数据集,所以会把模型参数 \(\theta\) 当作变量,最大化数据在这些参数下的似然。这就是最大似然训练的基本思想。
参考资料与引用
本章节用于说明这套笔记项目的主要参考来源,以及当他人希望引用本项目时,建议采用的引用方式。
项目来源说明
这套笔记最初基于我对 MiniMind 项目的学习与代码阅读。在此基础上,我逐步补充了自己的理解、实验记录、问题整理与扩展阅读,最终将其组织成一套可持续更新的 mdBook 笔记。
因此,这个项目并不是对上游仓库的简单搬运,而是一个以学习过程为核心、以问题组织内容、以实践串联理论的个人笔记工程。
主要参考来源
当前公开标注的核心参考来源包括:
- MiniMind
- Awesome-LLM
- Andrej Karpathy: Let’s build GPT
- Stanford CS224N
- GPT in Numpy
- Hugging Face NLP Course
后续如果某一章节直接引用了具体论文、文章、课程或代码实现,我会继续在对应章节中补充更细的出处说明。
如何引用本项目
如果这份笔记项目对你的学习、写作、课程整理或二次创作有帮助,欢迎引用本项目。
引用:转载、引用或参考本项目内容时,请注明原作者和项目来源。
Cited as:
LEE. (May 2026). LLM ALL in One: 从零开始构建大型语言模型.
https://github.com/leemojiang/llm-from-scratch
Or
@misc{lee2026llm_all_in_one,
title = {LLM ALL in One: 从零开始构建大型语言模型},
author = {LEE},
year = {2026},
month = may,
howpublished = {\url{https://github.com/leemojiang/llm-from-scratch}},
note = {GitHub repository}
}
使用与改编说明
本项目是持续更新中的学习笔记。引用、摘录或参考时,建议注意以下几点:
- 部分内容是围绕个人学习路径组织的,不一定等价于标准教材结构
- 部分章节会随着进一步学习继续补充、修订或重写
- 如果你引用了具体公式、代码片段或段落,建议同时给出对应仓库链接,便于读者查看上下文
致谢
感谢开源社区提供的大量高质量课程、代码仓库、博客文章与教程。尤其是 MiniMind 项目,为这套笔记提供了非常重要的实践入口和组织参照。